







强化学习笔记专栏传送
上一篇:强化学习RL学习笔记6-马尔可夫决策过程(MDP)(3)
下一篇:强化学习RL学习笔记8-策略梯度(Policy Gradient)
前言
强化学习(Reinforcement Learning, RL),又称再励学习、评价学习或增强学习,是机器学习的范式和方法论之一,用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题 。
本文是笔者对强化学习的一点学习记录,成文于笔者刚开始接触强化学习期间,主要内容参考LeeDeepRL-Notes,学习期间很多概念和理论框架还很不成熟,若文中存在错误欢迎批评指正,也欢迎广大学习者沟通交流、共同进步。
MDP
强化学习的三个重要的要素:状态(state)、动作(action)和奖励(reward)。 强化学习智能体跟环境是一步步交互的,就是先观察一下状态,然后再输入动作。再观察一下状态,再输出动作,拿到 reward 。它是一个跟时间相关的序列决策的问题。
状态转移概率是具有马尔可夫性质的(系统下一时刻的状态仅由当前时刻的状态决定,不依赖于以往任何状态)。因为状态转移概率,是下一时刻的状态是取决于当前的状态,它和之前的 s t − 1 s_{t-1} st−1 和 s t − 2 s_{t-2} st−2 都没有什么关系。然后再加上这个过程也取决于智能体跟环境交互的这个 a t a_t at ,所以有一个决策过程在里面。我们就称这样的一个过程为马尔可夫决策过程(Markov Decision Process, MDP)。
MDP 就是序列决策这样一个经典的表达方式。MDP 也是强化学习里面一个非常基本的学习框架。状态、动作、状态转移概率和奖励 (S,A,P,R),这四个合集就构成了强化学习 MDP 的四元组,后面也可能会再加个衰减因子构成五元组。
1.Model-based
当我们知道 P 函数和 R 函数时,就说这个 MDP 是已知的,可以通过 policy iteration 和 value iteration 来找最佳的策略,用这两个函数去描述环境
2.Model-free
Model-free 指处在一个未知的环境,也就是一系列的决策的 P 函数和 R 函数是未知的,这就是 model-based 跟 model-free 的一个最大的区别。
强化学习就是可以用来解决用完全未知的和随机的环境。
- 用价值函数 V(s) 来代表这个状态是好或坏的。
- 用 Q 函数判断在什么状态下做什么动作能够拿到最大奖励,用 Q 函数来表示这个状态-动作的价值。
3.Model-based vs. Model-free
- Policy iteration 和 value iteration 都需要得到环境的转移和奖励函数,所以在这个过程中,agent 没有跟环境进行交互。
- 在很多实际的问题中,MDP 的模型可能是未知的,也有可能模型太大了,不能进行迭代的计算。比如 Atari 游戏、围棋、控制直升飞机、股票交易等问题,这些问题的状态转移太复杂了,在这种情况下,我们使用 model-free 强化学习的方法来解。
- Model-free 没有获取环境的状态转移和奖励函数,而是让 agent 跟环境进行交互,采集到很多的轨迹数据,agent 从轨迹中获取信息来改进策略,从而获得更多的奖励。
Q-table
Q-table 是一张已经训练好的表格,即各个状态下采取不同的 action 可以获得的 return。
有的时候把目光放得太长远不好,因为如果事情很快就结束的话,你考虑到最后一步的收益无可厚非。如果是一个持续的没有尽头的任务,即持续式任务(Continuing Task),你把未来的收益全部相加,作为当前的状态价值就很不合理。
所以可以引入衰减因子 γ \gamma γ 计算未来总收益, γ ∈ [ 0 , 1 ] \gamma \in [0,1] γ∈[0,1] ,越往后 γ n \gamma^n γn 就会越小,也就是说越后面的收益对当前价值的影响就会越小。

类似于上图,最后我们要求解的就是一张 Q 表格
- 它的行数是所有的状态数量,一般可以用坐标来表示表示格子的状态,也可以用 1、2、3、4、5、6、7 来表示不同的位置。
- Q 表格的列表示上下左右四个动作。
最开始这张 Q 表格会全部初始化为零,然后 agent 会不断地去和环境交互得到不同的轨迹,当交互的次数足够多的时候,我们就可以估算出每一个状态下,每个行动的平均总收益去更新这个 Q 表格。 怎么去更新 Q 表格就是接下来要引入的强化概念。
强化就是我们可以用下一个状态的价值来更新当前状态的价值,其实就是强化学习里面 bootstrapping 的概念。在强化学习里面,你可以每走一步更新一下 Q 表格,然后用下一个状态的 Q 值来更新这个状态的 Q 值,这种单步更新的方法叫做时序差分。
Model-free Prediction
在没法获取 MDP 的模型情况下,我们可以通过以下两种方法来估计某个给定策略的价值:
- Monte Carlo policy evaluation
- Temporal Difference(TD) learning
1.Monte-Carlo Policy Evaluation
蒙特卡罗(Monte-Carlo,MC)方法是基于采样的方法,我们让 agent 跟环境进行交互,就会得到很多轨迹。每个轨迹都有对应的 return: G t = R t + 1 + γ R t + 2 + γ 2 R t + 3 + . . . G_t=R_{t+1}+\gamma R_{t+2}+\gamma ^2R_{t+3}+... Gt=Rt+1+γRt+2+γ2Rt+3+...
- 把每个轨迹的 return 进行平均,就可以知道某一个策略下面对应状态的价值。
- MC 是用 empirical mean return 的方法来估计。
- MC 方法不需要 MDP 的转移函数和奖励函数,并且不需要像动态规划那样用 bootstrapping 的方法。
- MC 的局限性:只能用在有终止的 MDP 。
DP 和 MC 方法的差异:
- 动态规划也是常用的估计价值函数的方法。在动态规划里面,我们使用了 bootstrapping 的思想。bootstrapping 的意思就是我们基于之前估计的量来估计一个量。
- DP 就是用 Bellman expectation backup,就是通过上一时刻的值 v i − 1 ( s ′ ) v_{i-1}(s') vi−1(s′) 来更新当前时刻 v i ( s ) v_i(s) vi(s) 这个值,不停迭代,最后可以收敛。Bellman expectation backup 就有两层加和,内部加和和外部加和,算了两次 expectation,得到了一个更新。
- MC 是通过 empirical mean return (实际得到的收益)来更新。只是更新轨迹上的所有状态,跟轨迹没有关系的状态都没有更新。
- MC 可以在不知道环境的情况下 work,而 DP 是 model-based。
- MC 只需要更新一条轨迹的状态,而 DP 则是需要更新所有的状态。状态数量很多的时候(比如一百万个,两百万个),DP 这样去迭代的话,速度是非常慢的。这也是 sample-based 的方法 MC 相对于 DP 的优势。
2.Temporal Difference
为更好地理解时序差分(Temporal Difference,TD)这种更新方法,给出它的物理意义。
我们先理解一下巴普洛夫的条件反射实验,这个实验讲的是小狗会对盆里面的食物无条件产生刺激,分泌唾液。一开始小狗对于铃声这种中性刺激是没有反应的,可是我们把这个铃声和食物结合起来,每次先给它响一下铃,再给它喂食物,多次重复之后,当铃声响起的时候,小狗也会开始流口水。盆里的肉可以认为是强化学习里面那个延迟的 reward,声音的刺激可以认为是有 reward 的那个状态之前的一个状态。多次重复实验之后,最后的这个 reward 会强化小狗对于这个声音的条件反射,它会让小狗知道这个声音代表着有食物,这个声音对于小狗来说也就有了价值,它听到这个声音也会流口水。
巴普洛夫效应揭示的是中性刺激(铃声)跟无条件刺激(食物)紧紧挨着反复出现的时候,条件刺激也可以引起无条件刺激引起的唾液分泌,然后形成这个条件刺激。
这种中性刺激跟无条件刺激在时间上面的结合,就称之为强化。 强化的次数越多,条件反射就会越巩固。小狗本来不觉得铃声有价值的,经过强化之后,小狗就会慢慢地意识到铃声也是有价值的,它可能带来食物。更重要是一种条件反射巩固之后,我们再用另外一种新的刺激和条件反射去结合,还可以形成第二级条件反射,同样地还可以形成第三级条件反射。
-
TD 是介于 MC 和 DP 之间的方法。
-
TD 是 model free 的,不需要 MDP 的转移矩阵和奖励函数。
-
TD 可以从不完整的 episode 中学习,结合了 bootstrapping 的思想。
-
目的:对于某个给定的策略,在线(online)地算出它的价值函数,即一步一步地(step-by-step)算。
-
最简单的算法是 TD(0),每往前走一步,就做一步 bootstrapping,用得到的 estimated return 来更新上一时刻的值。
-
Estimated return R t + 1 + γ v ( S t + 1 ) R_{t+1}+\gamma v(S_{t+1}) Rt+1+γv(St+1) 被称为 TD target,TD target 是带衰减的未来收益的总和。TD target 由两部分组成:
- 走了某一步后得到的实际奖励: R t + 1 R_{t+1} Rt+1
- 利用了 bootstrapping 的方法,通过之前的估计来估计 v ( S t + 1 ) v(S_{t+1}) v(St+1) ,然后加了一个折扣系数,即 γ v ( S t + 1 ) \gamma v(S_{t+1}) γv(St+1) 。
-
TD error δ = R t + 1 + γ v ( S t + 1 ) − v ( S t ) \delta=R_{t+1}+\gamma v(S_{t+1})-v(S_t) δ=Rt+1+γv(St+1)−v(St) 。
-
类比于 Incremental Monte-Carlo 的方法,写出如下的更新方法: v ( S t ) ← v ( S t ) + α ( R t + 1 + γ v ( S t + 1 ) − v ( S t ) ) v\left(S_{t}\right) \leftarrow v\left(S_{t}\right)+\alpha\left(R_{t+1}+\gamma v\left(S_{t+1}\right)-v\left(S_{t}\right)\right) v(St)←v(St)+α(Rt+1+γv(St+1)−v(St))
上式体现了强化这个概念(即通过当前状态的下一状态 value 更新当前状态的 value )。
对比 MC 和 TD:
-
在 MC 里面 G i , t G_{i,t} Gi,t 是实际得到的值(可以看成 target),因为它已经把一条轨迹跑完了,可以算每个状态实际的 return。
-
TD 没有等轨迹结束,往前走了一步,就可以更新价值函数。
-
TD 可以 online learning,每走一步就可以更新,效率高。
-
MC 必须等游戏结束才可以学习。
-
TD 可以从不完整序列上进行学习。
-
MC 只能从完整的序列上进行学习。
-
TD 可以在连续的环境下(没有终止)进行学习。
-
MC 只能在有终止的情况下学习。
-
TD 利用了马尔可夫性质,在马尔可夫环境下有更高的学习效率。
-
MC 没有假设环境具有马尔可夫性质,利用采样的价值来估计某一个状态的价值,在不是马尔可夫的环境下更加有效
TD 能够在知道结果之前就开始学习,相比 MC,其更快速、灵活。
可以把 TD 进行进一步的推广。之前是只往前走一步,即 one-step TD,TD(0)。可以调整步数,变成 n-step TD。 比如 TD(2),即往前走两步,然后利用两步得到的 return,使用 bootstrapping 来更新状态的价值。这样就可以通过 step 来调整这个算法需要多少的实际奖励和 bootstrapping。
通过调整步数,可以进行一个 MC 和 TD 之间的 trade-off,如果
n
=
∞
n=\infty
n=∞ , 即整个游戏结束过后,再进行更新,TD 就变成了 MC。
n-step 的 TD target 如下式所示:
G
t
n
=
R
t
+
1
+
γ
R
t
+
2
+
…
+
γ
n
−
1
R
t
+
n
+
γ
n
v
(
S
t
+
n
)
G_{t}^{n}=R_{t+1}+\gamma R_{t+2}+\ldots+\gamma^{n-1} R_{t+n}+\gamma^{n} v\left(S_{t+n}\right)
Gtn=Rt+1+γRt+2+…+γn−1Rt+n+γnv(St+n) 得到 TD target 之后,用 incremental learning 的方法来更新状态的价值:
v
(
S
t
)
←
v
(
S
t
)
+
α
(
G
t
n
−
v
(
S
t
)
)
v\left(S_{t}\right) \leftarrow v\left(S_{t}\right)+\alpha\left(G_{t}^{n}-v\left(S_{t}\right)\right)
v(St)←v(St)+α(Gtn−v(St))
3.Bootstrapping and Sampling for DP,MC and TD
-
Bootstrapping:更新时使用了估计:
- MC 没用 bootstrapping,因为它是根据实际的 return 来更新。
- DP 用了 bootstrapping。
- TD 用了 bootstrapping。
-
Sampling:更新时通过采样得到一个期望:
- MC 是纯 sampling 的方法。
- DP 没有用 sampling,它是直接用 Bellman expectation equation 来更新状态价值的。
- TD 用了 sampling。TD target 由两部分组成,一部分是 sampling,一部分是 bootstrapping。
(1)DP

DP 是直接算 expectation,把它所有相关的状态都进行加和。
v
(
S
t
)
←
E
π
[
R
t
+
1
+
γ
v
(
S
t
+
1
)
]
v(S_t)\leftarrow \Bbb E_\pi[R_{t+1}+\gamma v(S_{t+1})]
v(St)←Eπ[Rt+1+γv(St+1)]
(2)MC

MC 在当前状态下,采一个支路,在一个path 上进行更新,更新这个 path 上的所有状态。
v
(
S
t
)
←
v
(
S
t
)
+
α
(
G
t
−
v
(
S
t
)
)
v(S_t)\leftarrow v(S_t)+\alpha (G_t-v(S_t))
v(St)←v(St)+α(Gt−v(St))
G
t
=
R
t
+
1
+
γ
R
t
+
2
+
γ
2
R
t
+
3
+
.
.
.
G_t=R_{t+1}+\gamma R_{t+2}+\gamma ^2R_{t+3}+...
Gt=Rt+1+γRt+2+γ2Rt+3+...
(3)TD(0)

TD(0) 是从当前状态开始,往前走了一步,关注的是非常局部的步骤。
v
(
S
t
)
←
v
(
S
t
)
+
α
(
R
t
+
1
+
γ
v
(
S
t
+
1
)
−
v
(
S
t
)
)
v(S_t)\leftarrow v(S_t)+\alpha (R_{t+1}+\gamma v(S_{t+1})-v(S_t))
v(St)←v(St)+α(Rt+1+γv(St+1)−v(St))
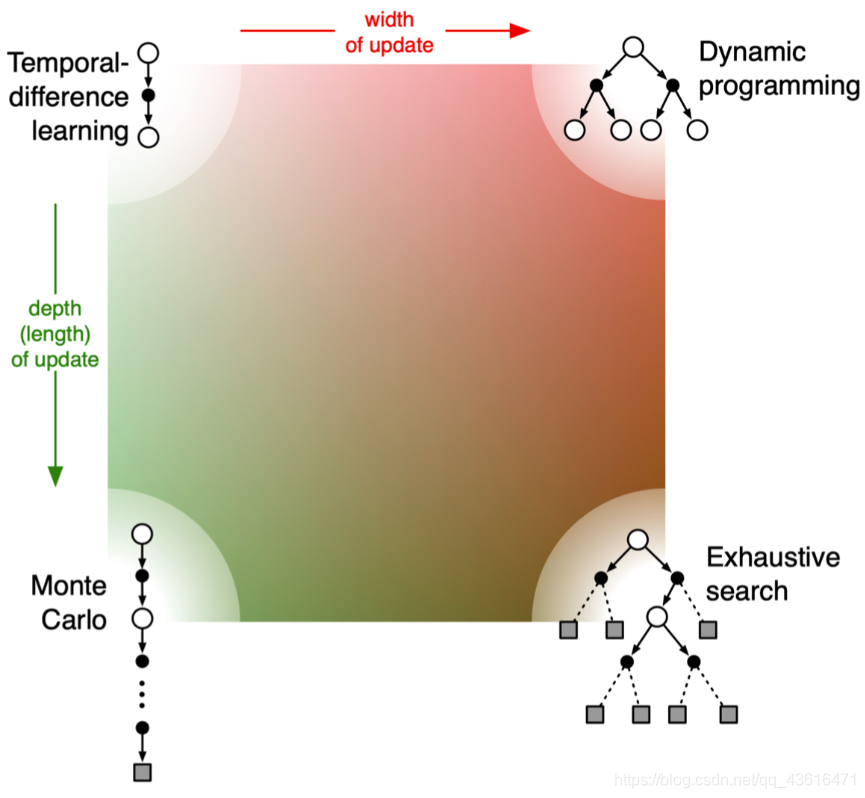
- 如果 TD 需要更广度的 update,就变成了 DP(因为 DP 是把所有状态都考虑进去来进行更新)。
- 如果 TD 需要更深度的 update,就变成了 MC。
- 右下角是穷举的方法(exhaustive search),穷举的方法既需要很深度的信息,又需要很广度的信息。
Model-free Control
不知道 MDP 模型情况下,如何优化价值函数,得到最佳的策略?可以把 policy iteration 进行一个广义的推广,使它能够兼容 MC 和 TD 的方法,即 Generalized Policy Iteration(GPI) with MC and TD。
Policy iteration 由两个步骤组成:
- 根据给定的当前的 policy π \pi π 来估计价值函数;
- 得到估计的价值函数后,通过 greedy 的方法来改进它的算法。

这两个步骤是一个互相迭代的过程。
在迭代过程的 improvement 过程中,需要利用下式通过 value-state 函数得到 Q 函数: q π i ( s , a ) = R ( s , a ) + γ ∑ s ′ ∈ S P ( s ′ ∣ s , a ) v π i ( s ′ ) q_{\pi_i}(s,a)=R(s,a)+\gamma \sum_{s' \in S}P(s'\mid s,a)v_{\pi_i}(s') qπi(s,a)=R(s,a)+γs′∈S∑P(s′∣s,a)vπi(s′)
但在 model-free 的情况下,并不知道它的奖励函数和状态转移,所以就没法估计它的 Q 函数。所以这里有一个问题:当我们不知道奖励函数和状态转移时,如何进行策略的优化。
针对上述情况,我们引入了广义的 policy iteration 的方法。我们对 policy improvement 部分进行修改:用 MC 的方法代替 DP 的方法去估计 Q 函数。当得到 Q 函数后,就可以通过 greedy 的方法去改进它。
MC 估计 Q 函数的算法:
- 假设每一个 episode 都有一个 exploring start,exploring start 保证所有的状态和动作都在无限步的执行后能被采样到,这样才能很好地去估计。
- 算法通过 MC 的方法产生了很多的轨迹,每个轨迹都可以算出它的价值。然后,我们可以通过average 的方法去估计 Q 函数。Q 函数可以看成一个 Q-table,通过采样的方法把表格的每个单元的值都填上,然后我们使用 policy improvement 来选取更好的策略。
- 算法核心:如何用 MC 方法来填 Q-table。
为了确保 MC 方法能够有足够的探索,我们使用了 ε \varepsilon ε-greedy exploration。
ε -greedy \varepsilon\text{-greedy} ε-greedy 的意思是说,有 1 − ε 1-\varepsilon 1−ε 的概率会按照 Q-function 来决定 action,通常 ε \varepsilon ε 设一个很小的值, 1 − ε 1-\varepsilon 1−ε 可能是 90%,也就是 90% 的概率会按照 Q-function 来决定 action,但是有 10% 的机率是随机的。通常在实现上 ε \varepsilon ε 会随着时间递减。在最开始的时候。因为还不知道那个 action 是比较好的,所以你会花比较大的力气在做 exploration。接下来随着 training 的次数越来越多。已经比较确定说哪一个 Q 是比较好的。你就会减少你的 exploration,你会把 ε \varepsilon ε 的值变小,主要根据 Q-function 来决定你的 action,比较少做 random,这是 ε -greedy \varepsilon\text{-greedy} ε-greedy。
当使用 MC 和
ε
ε
−
g
r
e
e
d
y
\varepsilonε-greedy
εε−greedy 探索这个形式的时候,可以确保价值函数是单调的,改进的。

上图是 MC with
ε
\varepsilon
ε-greedy exploration 算法的伪代码。
与 MC 相比,TD 有如下几个优势:
- 低方差。
- 能够在线学习。
- 能够从不完整的序列学习。
所以我们可以把 TD 也放到 control loop 里面去估计 Q-table,再采取这个 ε \varepsilon ε-greedy improvement。这样就可以在 episode 没结束的时候来更新已经采集到的状态价值。

- 偏差(bias):描述的是预测值(估计值)的期望与真实值之间的差距。偏差越大,越偏离真实数据,如上图第二行所示。
- 方差(variance):描述的是预测值的变化范围,离散程度,也就是离其期望值的距离。方差越大,数据的分布越分散,如上图右列所示。
1.Sarsa: On-policy TD Control
TD 是给定了一个策略,然后去估计它的价值函数。接着我们要考虑怎么用 TD 这个框架来估计 Q-function。
Sarsa 所作出的改变很简单,就是将原本我们 TD 更新 V 的过程,变成了更新 Q,如下式所示:
Q
(
S
t
,
A
t
)
←
Q
(
S
t
,
A
t
)
+
α
[
R
t
+
1
+
γ
Q
(
S
t
+
1
,
A
t
+
1
)
−
Q
(
S
t
,
A
t
)
]
Q(S_t,A_t) \leftarrow Q (S_t,A_t)+\alpha[R_{t+1}+\gamma Q(S_{t+1},A_{t+1})-Q(S_t,A_t)]
Q(St,At)←Q(St,At)+α[Rt+1+γQ(St+1,At+1)−Q(St,At)]
这个公式就是说可以拿下一步的 Q 值
Q
(
S
t
+
1
,
A
t
+
1
)
Q(S_{t+_1},A_{t+1})
Q(St+1,At+1) 来更新我这一步的 Q 值
Q
(
S
t
,
A
t
)
Q(S_t,A_t)
Q(St,At) 。
Sarsa 是直接估计 Q-table,得到 Q-table 后,就可以更新策略。
为了理解这个公式,如上图所示,我们先把 R t + 1 + γ Q ( S t + 1 , A t + 1 ) R_{t+1}+\gamma Q\left(S_{t+1}, A_{t+1}\right.) Rt+1+γQ(St+1,At+1) 当作是一个目标值,就是 Q ( S t , A t ) Q(S_t,A_t) Q(St,At) 想要逼近的一个目标值。 R t + 1 + γ Q ( S t + 1 , A t + 1 ) R_{t+1}+\gamma Q\left(S_{t+1}, A_{t+1}\right.) Rt+1+γQ(St+1,At+1) 就是 TD target。 R t + 1 + γ Q ( S t + 1 , A t + 1 ) − Q ( S t , A t ) R_{t+1}+\gamma Q\left(S_{t+1}, A_{t+1}\right)-Q\left(S_{t}, A_{t}\right) Rt+1+γQ(St+1,At+1)−Q(St,At) 就是 TD error。
该算法由于每次更新值函数需要知道当前的状态(state)、当前的动作(action)、奖励(reward)、下一步的状态(state)、下一步的动作(action),即 ( S t , A t , R t + 1 , S t + 1 , A t + 1 ) (S_{t}, A_{t}, R_{t+1}, S_{t+1}, A_{t+1}) (St,At,Rt+1,St+1,At+1) 这几个值 ,由此得名 Sarsa 算法。它走了一步之后,拿到了 ( S t , A t , R t + 1 , S t + 1 , A t + 1 ) (S_{t}, A_{t}, R_{t+1}, S_{t+1}, A_{t+1}) (St,At,Rt+1,St+1,At+1) 之后,就可以做一次更新。
Sarsa 属于单步更新法,也就是说每执行一个动作,就会更新一次价值和策略。如果不进行单步更新,而是采取 n 步更新或者回合更新,即在执行 n 步之后再来更新价值和策略,这样就得到了 n 步 Sarsa(n-step Sarsa)。
具体来说,对于 Sarsa,在 tt 时刻其价值的计算公式为 q t = R t + 1 + γ Q ( S t + 1 , A t + 1 ) q_{t}=R_{t+1}+\gamma Q\left(S_{t+1}, A_{t+1}\right) qt=Rt+1+γQ(St+1,At+1)
而对于 n 步 Sarsa,它的 n 步 Q 收获为 q t ( n ) = R t + 1 + γ R t + 2 + … + γ n − 1 R t + n + γ n Q ( S t + n , A t + n ) q_{t}^{(n)}=R_{t+1}+\gamma R_{t+2}+\ldots+\gamma^{n-1} R_{t+n}+\gamma^{n} Q\left(S_{t+n}, A_{t+n}\right) qt(n)=Rt+1+γRt+2+…+γn−1Rt+n+γnQ(St+n,At+n)
如果给
q
t
(
n
)
q_t^{(n)}
qt(n) 加上衰减因子
λ
\lambda
λ 并进行求和,即可得到 Sarsa(
λ
\lambda
λ) 的 Q 收获:
q
t
λ
=
(
1
−
λ
)
∑
n
=
1
∞
λ
n
−
1
q
t
(
n
)
q_{t}^{\lambda}=(1-\lambda) \sum_{n=1}^{\infty} \lambda^{n-1} q_{t}^{(n)}
qtλ=(1−λ)n=1∑∞λn−1qt(n)
因此,n 步 Sarsa(\lambdaλ)的更新策略可以表示为 Q ( S t , A t ) ← Q ( S t , A t ) + α ( q t ( n ) − Q ( S t , A t ) ) Q\left(S_{t}, A_{t}\right) \leftarrow Q\left(S_{t}, A_{t}\right)+\alpha\left(q_{t}^{(n)}-Q\left(S_{t}, A_{t}\right)\right) Q(St,At)←Q(St,At)+α(qt(n)−Q(St,At))
总的来说,Sarsa 和 Sarsa( λ \lambda λ) 的差别主要体现在价值的更新上。
2.Q-learning: Off-policy TD Control
Sarsa 是一种 on-policy 策略。Sarsa 优化的是它实际执行的策略,它直接拿下一步会执行的 action 来去优化 Q 表格,所以 on-policy 在学习的过程中,只存在一种策略,它用一种策略去做 action 的选取,也用一种策略去做优化。所以 Sarsa 知道它下一步的动作有可能会跑到悬崖那边去,所以它就会在优化它自己的策略的时候,会尽可能的离悬崖远一点。这样子就会保证说,它下一步哪怕是有随机动作,它也还是在安全区域内。
而 off-policy 在学习的过程中,有两种不同的策略:
- 第一个策略是我们需要去学习的策略,即target policy(目标策略),一般用 π \pi π 来表示,Target policy 就像是在后方指挥战术的一个军师,它可以根据自己的经验来学习最优的策略,不需要去和环境交互。
- 另外一个策略是探索环境的策略,即behavior policy(行为策略),一般用 μ \mu μ 来表示。 μ \mu μ 可以大胆地去探索到所有可能的轨迹,采集轨迹,采集数据,然后把采集到的数据喂给 target policy 去学习。而且喂给目标策略的数据中并不需要 A t + 1 A_{t+1} At+1,而 Sarsa 是要有 A t + 1 A_{t+1} At+1 的。Behavior policy 像是一个战士,可以在环境里面探索所有的动作、轨迹和经验,然后把这些经验交给目标策略去学习。比如目标策略优化的时候,Q-learning 不会管你下一步去往哪里探索,它就只选收益最大的策略。
在 off-policy learning 的过程中,我们这些轨迹都是 behavior policy 跟环境交互产生的,产生这些轨迹后,我们使用这些轨迹来更新 target policy π。
Off-policy learning 有很多好处:
- 我们可以利用 exploratory policy 来学到一个最佳的策略,学习效率高;
- 可以让我们学习其他 agent 的行为,模仿学习,学习人或者其他 agent 产生的轨迹;
- 重用老的策略产生的轨迹。探索过程需要很多计算资源,这样的话,可以节省资源。
Target policy π \pi π 直接在 Q-table 上取 greedy,就取它下一步能得到的所有状态,如下式所示: π ( S t + 1 ) = arg max a ′ Q ( S t + 1 , a ′ ) \pi\left(S_{t+1}\right)=\underset{a^{\prime}}{\arg \max}~ Q\left(S_{t+1}, a^{\prime}\right) π(St+1)=a′argmax Q(St+1,a′) Behavior policy μ \mu μ 可以是一个随机的 policy,但我们采取 ε -greedy \varepsilon\text{-greedy} ε-greedy,让 behavior policy 不至于是完全随机的,它是基于 Q-table 逐渐改进的。
我们可以构造 Q-learning target,Q-learning 的 next action 都是通过 arg max 操作来选出来的,于是我们可以代入 arg max 操作,可以得到下式: R t + 1 + γ Q ( S t + 1 , A ′ ) = R t + 1 + γ Q ( S t + 1 , arg max Q ( S t + 1 , a ′ ) ) = R t + 1 + γ max a ′ Q ( S t + 1 , a ′ ) \begin{aligned} R_{t+1}+\gamma Q\left(S_{t+1}, A^{\prime}\right) &=R_{t+1}+\gamma Q\left(S_{t+1},\arg \max ~Q\left(S_{t+1}, a^{\prime}\right)\right) \\ &=R_{t+1}+\gamma \max _{a^{\prime}} Q\left(S_{t+1}, a^{\prime}\right) \end{aligned} Rt+1+γQ(St+1,A′)=Rt+1+γQ(St+1,argmax Q(St+1,a′))=Rt+1+γa′maxQ(St+1,a′)
接着我们可以把 Q-learning update 写成 incremental learning 的形式,TD target 就变成 max 的值,即 Q ( S t , A t ) ← Q ( S t , A t ) + α [ R t + 1 + γ max a Q ( S t + 1 , a ) − Q ( S t , A t ) ] Q\left(S_{t}, A_{t}\right) \leftarrow Q\left(S_{t}, A_{t}\right)+\alpha\left[R_{t+1}+\gamma \max _{a} Q\left(S_{t+1}, a\right)-Q\left(S_{t}, A_{t}\right)\right] Q(St,At)←Q(St,At)+α[Rt+1+γamaxQ(St+1,a)−Q(St,At)]
再通过对比的方式来进一步理解 Q-learning。Q-learning 是 off-policy 的时序差分学习方法,Sarsa 是 on-policy 的时序差分学习方法。
- Sarsa 在更新 Q 表格的时候,它用到的 A’ 。我要获取下一个 Q 值的时候,A’ 是下一个 step 一定会执行的 action。这个 action 有可能是 ε \varepsilon ε-greedy 方法 sample 出来的值,也有可能是 max Q 对应的 action,也有可能是随机动作,但这是它实际执行的那个动作。
- 但是 Q-learning 在更新 Q 表格的时候,它用到这个的 Q 值 Q ( S ′ , a ) Q(S',a) Q(S′,a) 对应的那个 action ,它不一定是下一个 step 会执行的实际的 action,因为你下一个实际会执行的那个 action 可能会探索。
- Q-learning 默认的 next action 不是通过 behavior policy 来选取的,Q-learning 直接看 Q-table,取它的 max 的这个值,它是默认 A’ 为最优策略选的动作,所以 Q-learning 在学习的时候,不需要传入 A’,即 A t + 1 A_{t+1} At+1 的值。
事实上,Q-learning 算法被提出的时间更早,Sarsa 算法是 Q-learning 算法的改进。
Sarsa 和 Q-learning 的更新公式都是一样的,区别只在 target 计算的这一部分,
- Sarsa 是 R t + 1 + γ Q ( S t + 1 , A t + 1 ) R_{t+1}+\gamma Q(S_{t+1}, A_{t+1}) Rt+1+γQ(St+1,At+1);
- Q-learning 是 R t + 1 + γ max a Q ( S t + 1 , a ) R_{t+1}+\gamma \underset{a}{\max} Q\left(S_{t+1}, a\right) Rt+1+γamaxQ(St+1,a) 。
Sarsa 是用自己的策略产生了 S,A,R,S’,A’ 这一条轨迹。然后拿着 Q ( S t + 1 , A t + 1 ) Q(S_{t+1},A_{t+1}) Q(St+1,At+1) 去更新原本的 Q 值 Q ( S t , A t ) Q(S_t,A_t) Q(St,At) 。
但是 Q-learning 并不需要知道我实际上选择哪一个 action ,它默认下一个动作就是 Q 最大的那个动作。Q-learning 知道实际上 behavior policy 可能会有 10% 的概率去选择别的动作,但 Q-learning 并不担心受到探索的影响,它默认了就按照最优的策略来去优化目标策略,所以它可以更大胆地去寻找最优的路径,它会表现得比 Sarsa 大胆非常多。
对 Q-learning 进行逐步地拆解的话,跟 Sarsa 唯一一点不一样就是并不需要提前知道 A 2 A_2 A2 ,我就能更新 Q ( S 1 , A 1 ) Q(S_1,A_1) Q(S1,A1) 。在训练一个 episode 这个流程图当中,Q-learning 在 learn 之前它也不需要去拿到 next action A ′ A' A′,它只需要前面四个 ( S , A , R , S ′ ) (S,A,R,S') (S,A,R,S′) ,这跟 Sarsa 很不一样。
On-policy vs. Off-policy
总结一下 on-policy 和 off-policy 的区别。
- Sarsa 是一个典型的 on-policy 策略,它只用了一个 policy π 。如果 policy 采用 ε \varepsilon ε-greedy 算法的话,它需要兼顾探索,为了兼顾探索和利用,它训练的时候会显得有点胆小。它在解决悬崖问题的时候,会尽可能地离悬崖边上远远的,确保说哪怕自己不小心探索了一点,也还是在安全区域内。此外,因为采用的是 ε \varepsilon ε-greedy 算法,策略会不断改变( ε \varepsilon ε 会不断变小),所以策略不稳定。
- Q-learning 是一个典型的 off-policy 的策略,它有两种策略:target policy 和 behavior policy。它分离了目标策略跟行为策略。Q-learning 就可以大胆地用 behavior policy 去探索得到的经验轨迹来去优化目标策略,从而更有可能去探索到最优的策略。Behavior policy 可以采用 ε \varepsilon ε-greedy 算法,但 target policy 采用的是 greedy 算法,直接根据 behavior policy 采集到的数据来采用最优策略,所以 Q-learning 不需要兼顾探索。
- 比较 Q-learning 和 Sarsa 的更新公式可以发现,Sarsa 并没有选取最大值的 max 操作,因此,
- Q-learning 是一个非常激进的算法,希望每一步都获得最大的利益;
- 而 Sarsa 则相对非常保守,会选择一条相对安全的迭代路线。
Summary

上一篇:强化学习RL学习笔记6-马尔可夫决策过程(MDP)(3)
下一篇:强化学习RL学习笔记8-策略梯度(Policy Gradient)


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









