






【语料准备】
训练语料
wget http://idiom.ucsd.edu/~rlevy/teaching/2015winter/lign165/lectures/lecture13/toy-example/corpus.txt测试语料
wget http://idiom.ucsd.edu/~rlevy/teaching/2015winter/lign165/lectures/lecture13/toy-example/test_corpus.txt训练语料内容
$ cat corpus.txtdogs chase cats
dogs bark
cats meow
dogs chase birds
cats chase birds
dogs chase the cats
the birds chirp
【计数文件生成】 此步在实际应用中不需要
ngram-count -text corpus.txt -order 2 -write1 corpus_1gram.count -write2 corpus_2gram.count将计数文件分别输出到1-gram文件和2-gram文件
【模型文件生成】
ngram-count -text corpus.txt -debug 2 -order 2 -addsmooth 0 -lm corpus.lm这里使用-addsmooth 0 参数,使模型不进行平滑处理
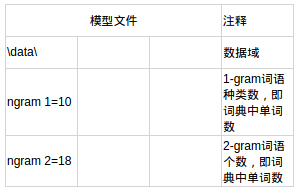
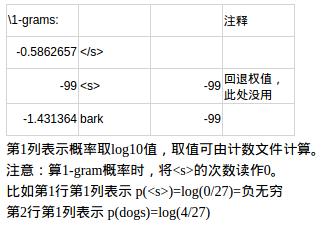
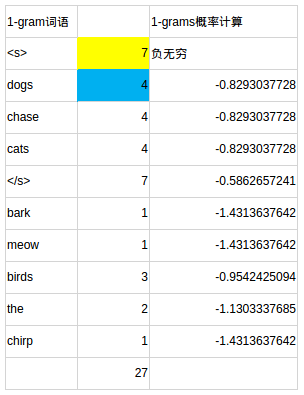
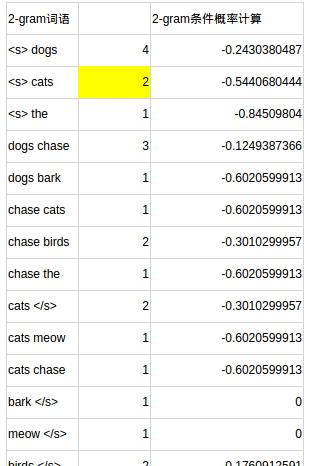
对模型文件的分析 此处省略了一些数据,详见excel
第1部分
第2部分
第3部分

【计算测试文件困惑度】
ngram -lm corpus.lm -ppl test_corpus.txt -debug 2
其中:每一行代表可以从lm文件中查到的条件概率,第1列概率表示,第2列说明是几元条件概率,第3列概率值,第4列为概率值取对数。
logprob为整个句子的概率,它是由所有行概率值相加得到的。
ppl为困惑度,它是由公式10^-logprob/(#sen+#words)计算得到的。
以第1句话为例:ppl=10^-(-1.44716)/(1+4)=1.94729。
ppl1为困惑度,它是由公式 10^-logprob/#words计算得到的。
以第1句话为例:ppl1=10^-(-1.44716)/4=2.30033。














 3158
3158











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









