







这里主要分析WebContentProcess中加载页面的过程,主要针对HTTP请求的处理。
主要结构
WebKit2从接受到loadURL开始,就会准备尝试加载网络数据。不同平台用于处理HTTP请求的网络模块不同,可以简单得描述为下面这个块图:
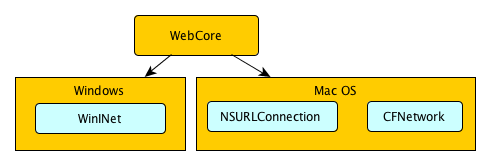
*Mac OS平台上现在默认使用的是NSURLConnection.
*NSURLConnection的使用方式可以参考这里 (关键是它的delegate工作方式):
整个数据加载的核心类是以WebCore的ResourceHandle为核心的,ResourceLoader是对外的服务接口。先看内部关系:
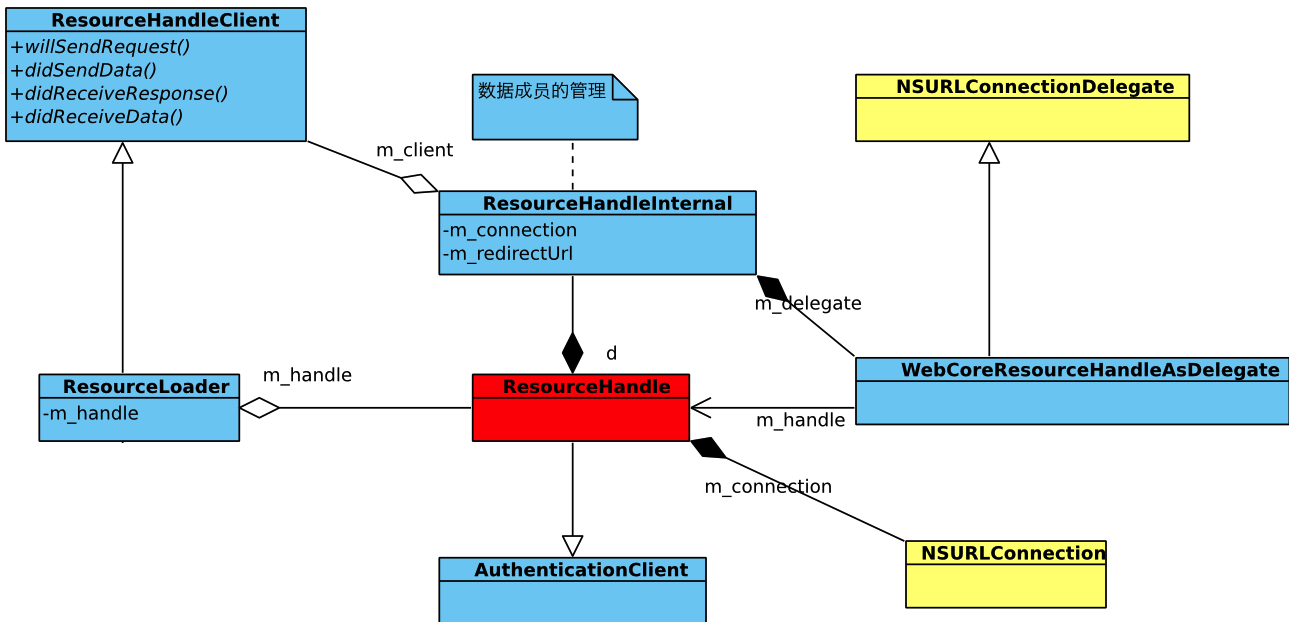
从左至右,ResourceLoader实现了ResourceHandleClient接口做为ResourceHandle的调用者。 ResourceHandle也将内部数据使用PIMPL(参考:WebKit中的两个小设计)包装起来。在实际实现时,也是在不同平台实现了相应的ResourceHandle。在Mac OS下,则使用NSURLConnection进行通讯处理,WebCoreResourceHandleAsDelegate则是NSURLConnection的代理类(实现NSURLConnectionDelegate),用来做为具体加载操作行为的处理操作,包括HTTP Request的发送控制及相应的错误处理等。
再以ResourceLoader向WebCore调用方向看,下面为相关类图:
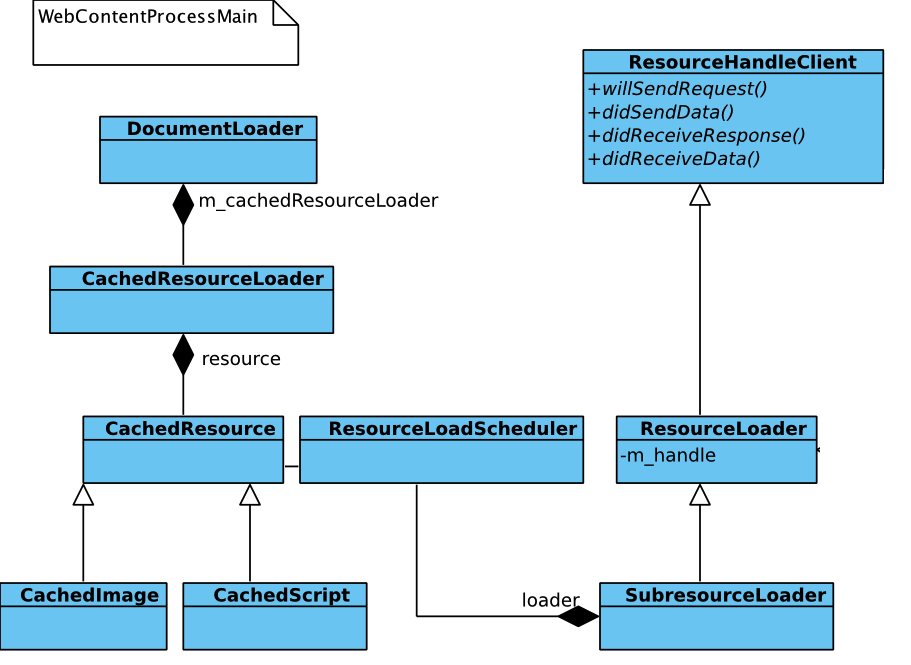
ResourceLoadScheduler & SubresourceLoader & ResourceLoader构成WebCore对加载逻辑的实现。有了个Scheduler就表示一定有一个队列管理的机制:

其中m_requestsPending就是一个队列, 调用者通过scheduleSubresourceLoad()添加新的请求,并由servePendingRequests()负责处理队列中的任务。
有意思的是它的队列:
typedef Deque<RefPtr<ResourceLoader> >RequestQueue;
RequestQueue m_requestsPending[ResourceLoadPriorityHighest +1];
typedef HashSet<RefPtr<ResourceLoader> > RequestMap;
RequestMap m_requestsLoading;
Deque顾名思义,是一个双向列表,列表中每个元素是一个ResourceLoader。在执行过程中只要从队列中取出ResourceLoader就会触发相应的加载过程。
这里面有一个明确的1对1的关系(一个HTTP资源对应一个ResourceLoader)。
通过m_requestsPending是以数组形式的定义也可以看得出来,按不同的优先级分出了不同的Request Queue。下面的m_requestsLoading记录的是当servePendingRequesg()处理时,将某个request激活后添加进去,表示当现正在加载的request。
加载的过程
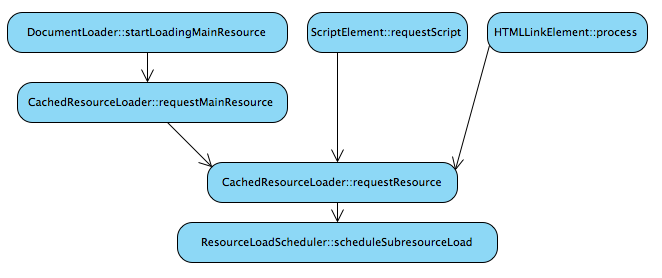
加载的过程,相对WebKit官网的一份资料(How WebKit Loads a Web Page), 已经有了一些变化。关键是合并了主资源与子资源流程,可以用下图对比一下:
*其中ScriptElement和HTMLLinkElement所请求的都是之前定义的Sub Resources.
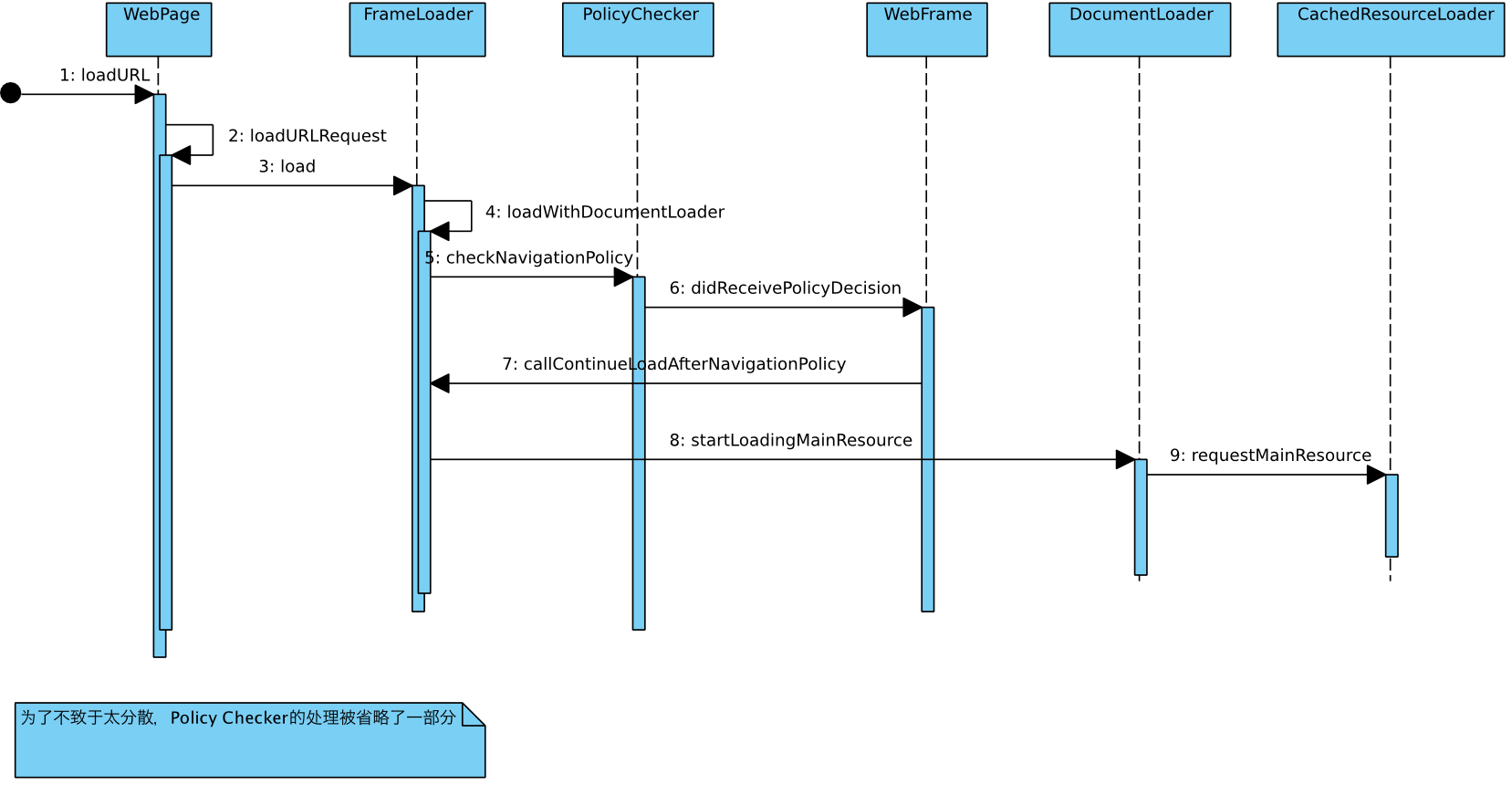
附上几张序列图来看一些细节:
1. 从WebPage加载说起
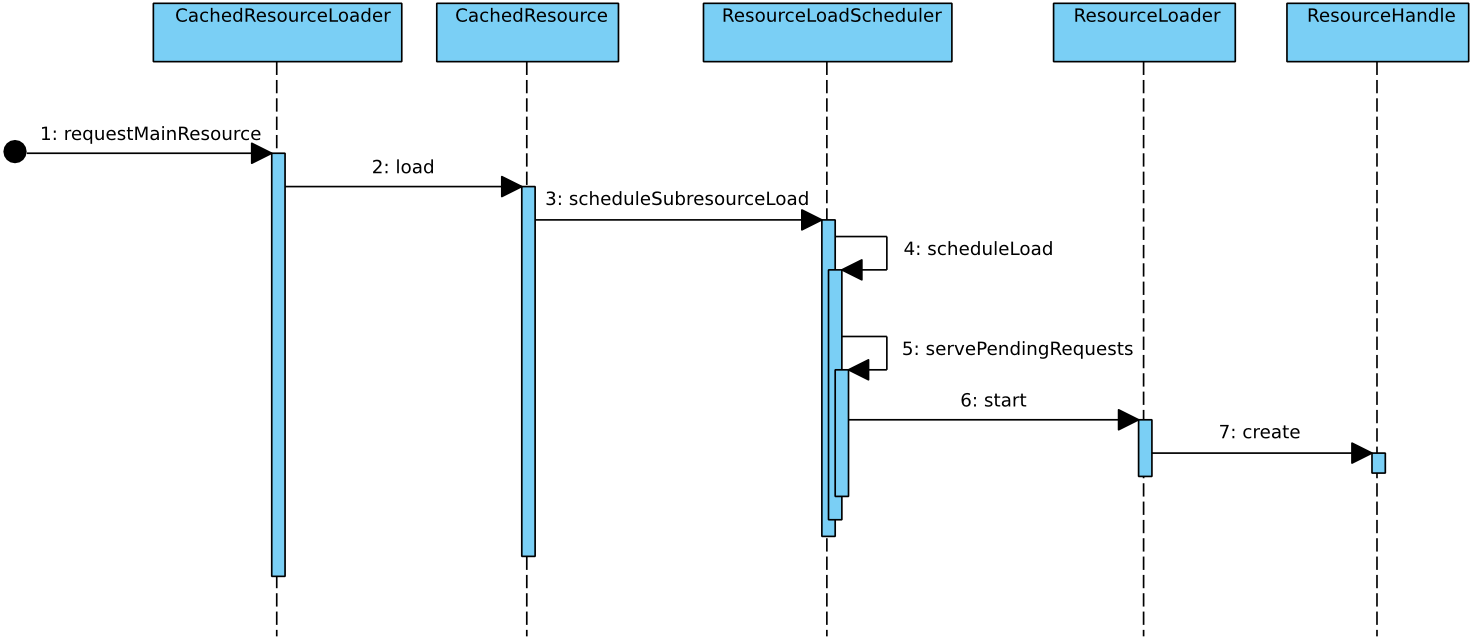
2. ResoureLoader的处理
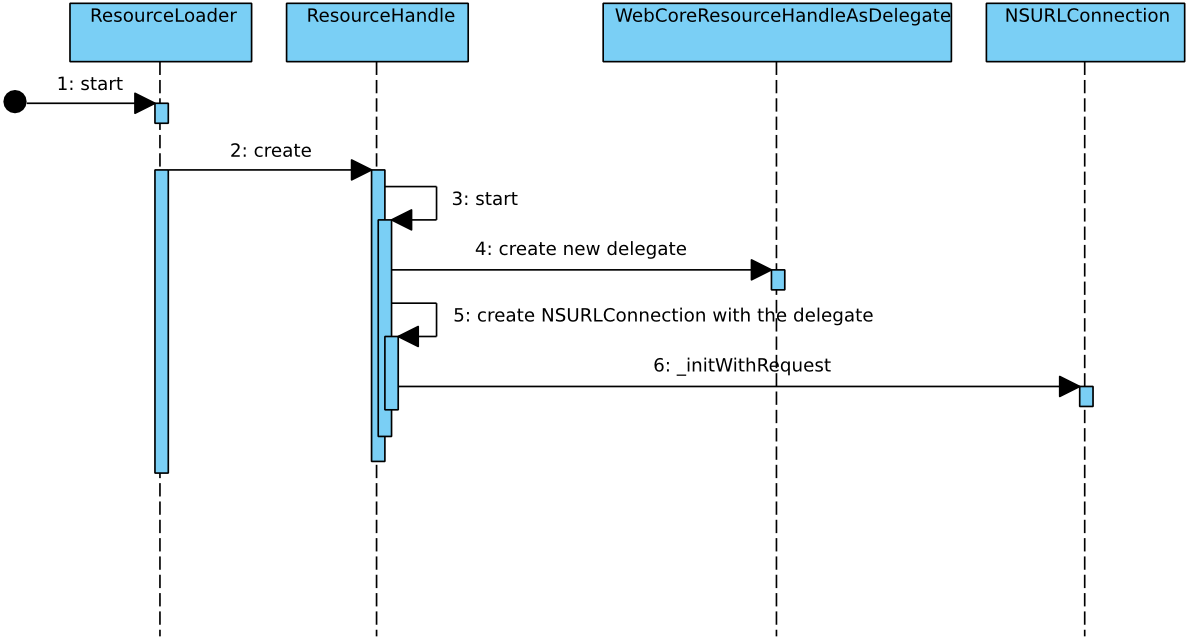
3. ResourceHandle的处理
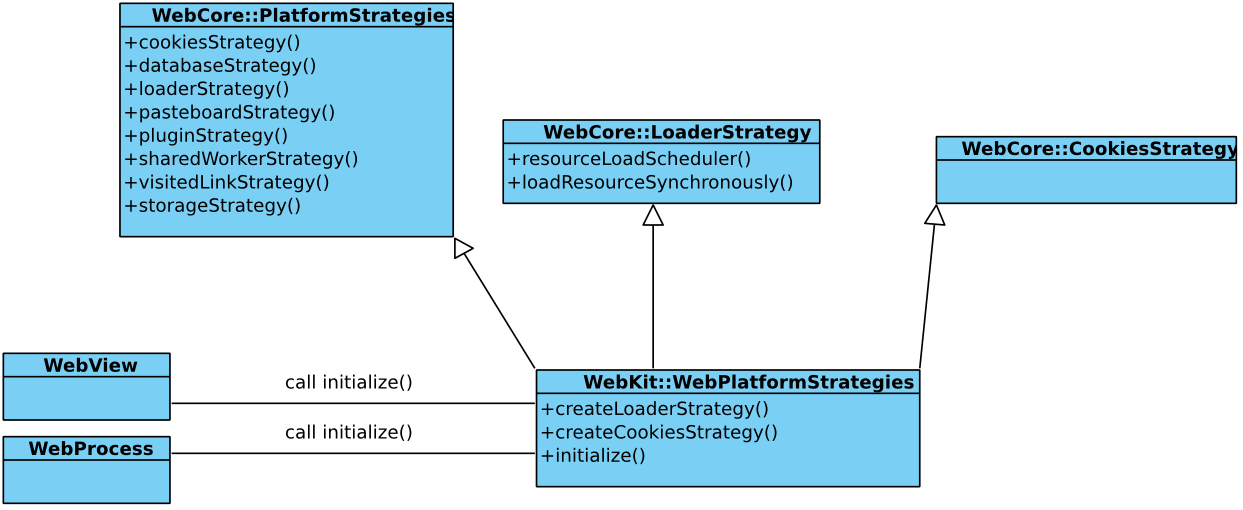
加载对应的策略机制
WebKit为了提高一些操作的灵活性,引入了策略管理的机制。 以ResourceLoader为例,也就是下图中的loaderStrategy, 会决定使用哪一个ResourceLoadScheduler来管理下载任务,再由WebKit中的WebPlatformStrategies来做具体的决策选择。其控制过程灵活的使用了回调机制,细节另外再讨论。
首先可以这样理解WebKit的加载逻辑,涉及三个主要的组件, 其中HTTP stack为各个平台下使用的HTTP协议模块,WebCore Loaders则依据页面加载及解析过程对加载不同HTML Element的控制,Loading Controller则具体实现了资源加载的行为控制:

虽然从WebKit整体结构上这样理解不太严谨的,但单纯站在加载的角度来看,却有利于理解加载流程。因为HTTP Stack依赖平台实现,这里从中间的Loading Controller说起。
Loading Controller提供了两个重要的接口类,一个是供WebCore调用以加载各个资源的类CachedResourceLoader, 另一个是对接HTTP模块的ResourceHandle。

1. 加载不同的资源
不同的资源的加载其差异在于数据的处理方式不同,比如主文档要提交到Document Parser里去进行解析,图片则要显示出来,但它们的网络加载流程是相同的,所以它们有不同的CachedResourceClient实现,复用了SubresourceLoader的加载流程。
下图可以看到DcoumentLoader及ScriptElement如何关联到CachedResource:

开始加载资源包含两个重要过程:一是创建CachedResource, 二是调用CachedResource::addClient注册CachedResourceClient实例。
下图是ScriptElement的加载序列图:

CachedResourceHandle可以视为CachedResource的一个封装,提供给WebCore Loaders使用。
CachedResourceHandle是一个模板类
template <class R> class CachedResourceHandle
CachedResourceLoader为不同类型的资源提供了不同的接口函数,比如Script对应的加载函数:
CachedResourceHandle<CachedScript> CachedResourceLoader::requestScript(CachedResourceRequest& request)
{
return static_cast<CachedScript*>( requestResource(CachedResource::Script, request).get() );
}
当收到数据时,从CachedResource派生出来的子类,会通过data函数及时获得已加载的数据,再通过注册的clients完成相应的操作。
上一篇已经提到加载的发起流程,下面是收到数据后,HTTP Stack回调的过程:

*出错时,则调用到CachedResource::error()
下图是主文档(CachedRawResource)收到数据后的处理流程(DocumentLoader就是CachedRawResource的client):

以下是CachedRawResource::data的代码片段:
if (incrementalDataLength) {
CachedResourceClientWalker<CachedRawResourceClient> w(m_clients);
while (CachedRawResourceClient* c = w.next())
c->dataReceived(this, incrementalData, incrementalDataLength);
}
2. ResourceHandle的跨平台
关于WebKit的跨平台机制,可以参考<<WebKit模块化分析>>中"兼容并蓄 - WebKit的跨平台方案"。
ResourceHandle,ResourceHandleInternal及NetworkingContext都定义在platform/network目录下. ReourceHandle针对不同平台有部分函数有不同的实现,实现的单元文件在platform/network目录下具体平台port的子目录下。

*在使用的HTTP Stack中,除curl等平台实现外,WebKit源代码还提到了SOUP, 这也是一个为GNOME应用提供HTTP支持的库,简介如下:
Soup uses GObjects and the glib main loop, and is designed to work well with Gtk/GNOME applications. This enables GNOME applications to access HTTP servers on the network in a completely asynchronous fashion, very similar to the Gtk+ programming model (a synchronous operation mode is also supported for those who want it).
首先可以这样理解WebKit的加载逻辑,涉及三个主要的组件, 其中HTTP stack为各个平台下使用的HTTP协议模块,WebCore Loaders则依据页面加载及解析过程对加载不同HTML Element的控制,Loading Controller则具体实现了资源加载的行为控制:
虽然从WebKit整体结构上这样理解不太严谨的,但单纯站在加载的角度来看,却有利于理解加载流程。因为HTTP Stack依赖平台实现,这里从中间的Loading Controller说起。
Loading Controller提供了两个重要的接口类,一个是供WebCore调用以加载各个资源的类CachedResourceLoader, 另一个是对接HTTP模块的ResourceHandle。
1. 加载不同的资源
不同的资源的加载其差异在于数据的处理方式不同,比如主文档要提交到Document Parser里去进行解析,图片则要显示出来,但它们的网络加载流程是相同的,所以它们有不同的CachedResourceClient实现,复用了SubresourceLoader的加载流程。
下图可以看到DcoumentLoader及ScriptElement如何关联到CachedResource:
开始加载资源包含两个重要过程:一是创建CachedResource, 二是调用CachedResource::addClient注册CachedResourceClient实例。
下图是ScriptElement的加载序列图:
CachedResourceHandle可以视为CachedResource的一个封装,提供给WebCore Loaders使用。
CachedResourceHandle是一个模板类
template <class R> class CachedResourceHandle
CachedResourceLoader为不同类型的资源提供了不同的接口函数,比如Script对应的加载函数:
CachedResourceHandle<CachedScript> CachedResourceLoader::requestScript(CachedResourceRequest& request)
{
return static_cast<CachedScript*>( requestResource(CachedResource::Script, request).get() );
}
当收到数据时,从CachedResource派生出来的子类,会通过data函数及时获得已加载的数据,再通过注册的clients完成相应的操作。
上一篇已经提到加载的发起流程,下面是收到数据后,HTTP Stack回调的过程:
*出错时,则调用到CachedResource::error()
下图是主文档(CachedRawResource)收到数据后的处理流程(DocumentLoader就是CachedRawResource的client):
以下是CachedRawResource::data的代码片段:
if (incrementalDataLength) {
CachedResourceClientWalker<CachedRawResourceClient> w(m_clients);
while (CachedRawResourceClient* c = w.next())
c->dataReceived(this, incrementalData, incrementalDataLength);
}
2. ResourceHandle的跨平台
关于WebKit的跨平台机制,可以参考<<WebKit模块化分析>>中"兼容并蓄 - WebKit的跨平台方案"。
ResourceHandle,ResourceHandleInternal及NetworkingContext都定义在platform/network目录下. ReourceHandle针对不同平台有部分函数有不同的实现,实现的单元文件在platform/network目录下具体平台port的子目录下。
*在使用的HTTP Stack中,除curl等平台实现外,WebKit源代码还提到了SOUP, 这也是一个为GNOME应用提供HTTP支持的库,简介如下:
Soup uses GObjects and the glib main loop, and is designed to work well with Gtk/GNOME applications. This enables GNOME applications to access HTTP servers on the network in a completely asynchronous fashion, very similar to the Gtk+ programming model (a synchronous operation mode is also supported for those who want it).
关于页面加载,RFC2616(HTTP 1.1)做了很多的定义,WebKit的流程也是遵循这些定义的实现。这部分的实现主要放在之前提出的WebCore Loaders和HTTP Stack中。
比如Chrome Net Stack(里面包含了HTTP Stack的实现)中实现了HTTP Cache, 而Android浏览器则是在HTTP Client中实现了HTTP Cache。 关于缓存,会专门在新篇中学习一下。另外在加载中的策略控制已经在第一篇中提到了,其它的还有错误处理、跳转等。
下面补充几个场景下的流程。没有做进一步的总结,只是简单将流程列出来。
1.错误控制
错误由HTTP Stack中抛出来,依次调用到CachedResource::error进行处理。这里要说明的是WebCoreResourceHandleAsDelegate本身只对应到ResourceHandle的,在错误处理调用则使用m_handle->client()的形式访问到了ResourceLoader。

2.跳转
关于跳转,实际完全在HTTP Stack中完成的,只是会在跳转前通过willSendRequest的方式通知到DocumentLoader。

3. Subframe
关于iframe,或是plugin之类的sub frame, 在加载时也是走DocumentLoader::startLoadingMainResource()的流程,不同的是它的发起者是SubframeLoader。它并不是继承自CachedResourceClient, 而是封装了一些上层的加载逻辑。

后续会根据HTTP 1.1协议中关于页面加载的定义展开一些WebKit的实现,特别是缓存的处理。















 318
318

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









