







目录
简略
分布式系统中不同于单机系统不能使用NTP(网络时间协议(Network Time Protocol))来获取时间,所以我们需要一个特别的方式来获取分布式系统中的时间,mvcc也是使用time保证读写相互不影响
Logical Time
使用 接收到的消息内的时间和自己的时间中最新的那个。
各个节点发送消息时附带自己的时间Ci,对方收到之后和自己的时间Cj 比对,选择大的时间更新为自己的时间Cj = max{Cj,Ci}.
Vector Clock
接收到的消息有所有节点的“时间戳”集合,每个时间戳都比本地的集合对应节点的大,就用对方的,都比本地的节点小就用自己的,不是全部都大或者都小就裁决。
VectorClock一个集合内包含所有节点的“时间戳”:{Node1:0,Node2:2,Node3:3.......}(这个时间戳并不是物理意义上的时间而是由程序赋予的逻辑计数(count)),收发消息时比对和更新自身VectorClock:
a:本机:{0,0,1} 消息:{0,1,2}。消息的每个节点的count都大于等于本机的,那么舍弃本机,同步消息
b:本机:{0,1,2} 消息:{0,1,1}。消息的每个节点的count都小于等于本机的,那么舍弃消息,保留本机
c:本机:{0,3,1} 消息:{0,1,2}。出现冲突,有的大,有的小,无法判断出来到底谁是最新版本。就要进行冲突仲裁。
True Time
需要专用硬件支持
Google Spanner里面,通过引入True Time来解决了分布式时间问题。Spanner通过使用GPS + Atomic Clock来对集群的机器进行校时,精度误差范围能控制在ms级别. 需要专用硬件支持
Hybrid Logic Clock(HLC/混合逻辑时钟)
HLC存储两部分信息:本地时钟(物理部分)l,计数器(逻辑部分)c
本地时钟部分l=集群节点的本地时钟的最大值(每次进行事务通信时更新这部分信息)
计数器部分c=每次事件或者消息通信时++(累加),类似逻辑时钟里每次事件都++(累加)。
HLC比较大小时,先用比较l部分,如果l相等再看c是否为零。
详细
摘抄自:分布式系统中的时间 - https://www.jianshu.com/p/18f063573aae
Logical Time
本质是通过事件发生的顺序,通过相互通信更新自己的时间,即通过a->b 根据通信得到C(a) > C(b);
每个进程Pi维护一个本地计数器Ci,相当于logical clocks,按照以下的规则更新Ci
1 每次执行一个事件(例如通过网络发送消息,或者将消息交给应用层,或者其它的一些内部事件)之前,将Ci加1
2 当Pi发送消息m给Pj的时候,在消息m上附着上Ci
3 当接收进程Pj接收到Pi的发送的消息时,更新自己的Cj = max{Cj,Ci}
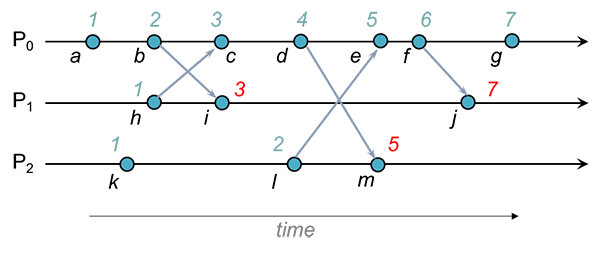
未解决问题:我们不能通过C(a) > C(b) 得出a->b,不能使用真实时间进行事务查询
Vector Clock
VectorClock是一种用向量来表示偏序关系的逻辑时钟,从数据结构上可以理解为一个集合内包含所有节点的“时间戳”,当然这个时间戳并不是物理意义上的时间(也有些实践会同时加入timestamps以解决冲突问题),而是由程序赋予的逻辑计数(count),{Node1:0,Node2:2,Node3:3.......},如果我们已经统一了向量内的位置对应的node,那么时钟可以直接用一个{0,2,3}来表示。
对于每一个分布式存储的对象副本都有这样一个时间戳,那么存在一下几种关系:
a:本机:{0,0,1} 消息:{0,1,2}。消息的每个节点的count都大于等于本机的,那么舍弃本机,同步消息
b:本机:{0,1,2} 消息:{0,1,1}。消息的每个节点的count都小于等于本机的,那么舍弃消息,保留本机
c:本机:{0,3,1} 消息:{0,1,2}。出现冲突,有的大,有的小,无法判断出来到底谁是最新版本。就要进行冲突仲裁。
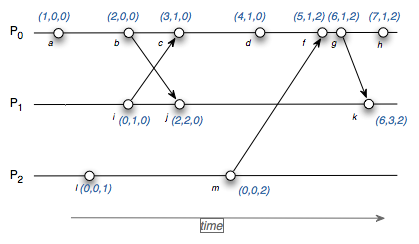
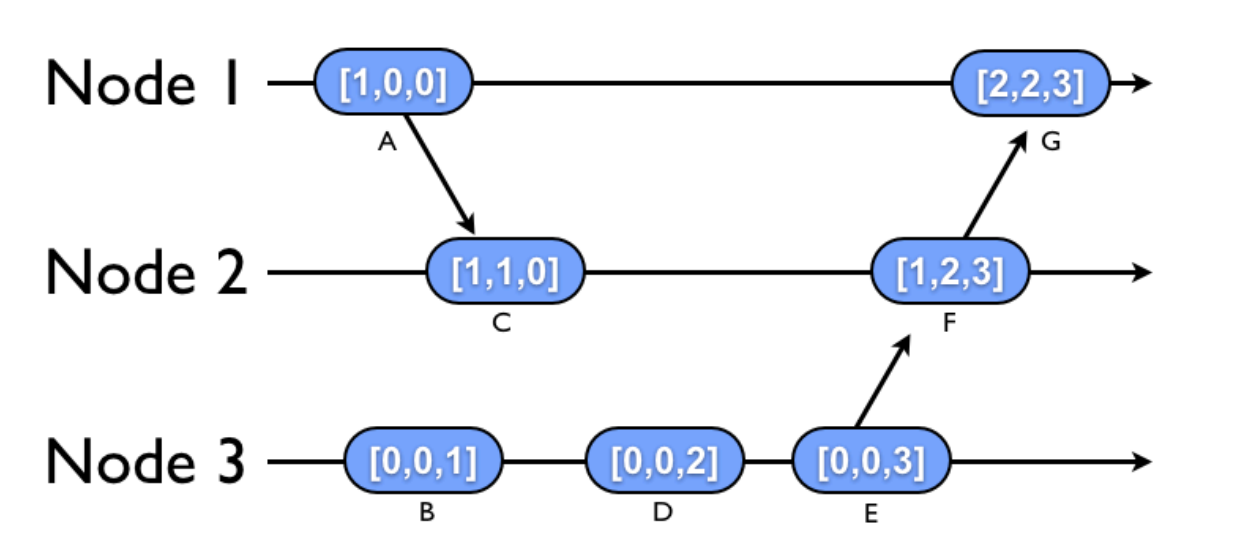
ps:vector clock类似于quorum协议,更新的时候将本机vector clock与事务vector clock进行对比,根据规则进行更新
未解决问题:不能使用真实时间进行事务查询
True Time
前面我们说了,NTP是有误差的,而且NTP还可能出现时间回退的情况,所以我们不能直接依赖NTP来确定一个事件发生的时间。在Google Spanner里面,通过引入True Time来解决了分布式时间问题。Spanner通过使用GPS + Atomic Clock来对集群的机器进行校时,精度误差范围能控制在ms级别,通过提供一套TrueTime API给外面使用。
TrueTime API很简单,只有三个函数:
MethodReturn
TT.now()TTinterval: [earliest, latest]
TT.after(t)true if t has definitely passed
TT.before(t)true if t has definitely not arrived
首先now得到当前的一个时间区间,spanner不能得到精确的一个时间点,只能得到一段区间,但这个区间误差范围很小,也就是ms级别,我们用ε来表示,也就是[t - ε, t + ε]这个范围,
假设事件a发生绝对时间为tt.a,那么我们只能知道tt.a.earliest <= tt.a <= tt.a.latest, 所以对于另一个事件b,只要tt.b.earliest > tt.a.latest,我们就能确定b一定是在a之后发生的,也就是说,我们需要等待大概2ε的事件才能去提交b,这个就是spanner里面说的commit wait time,保证误差时间消除掉。
未解决问题:需要专用硬件支持
Hybrid Logic Clock
混合逻辑时钟HLC存储两部分信息,一部分取值来源于本地时钟(物理部分)l,另一部分取值来自于计数器(逻辑部分)c。
来源于物理的部分,里面保存的其实是当前所有参与节点的本地时钟的最大值(每次进行事务通信时更新这部分信息),另一部分则是每次事件或者消息通信时++(累加),类似逻辑时钟里每次事件都++(累加)。
HLC将这两部分称为l和c。混合逻辑时钟比较大小时,先用比较l部分,如果相等再看c是否为零。
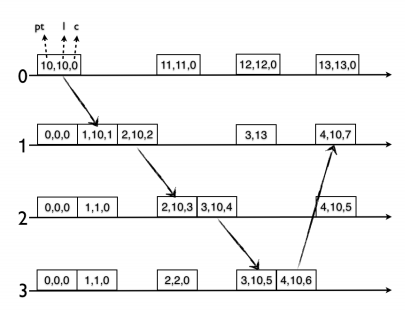
混合逻辑时钟HLC的算法描述如下:
本地事件或者发送消息时:
如果本地时钟(pt)大于当前的混合逻辑时钟的l,则将l更新成本地时钟,将c清零。
否则,l保持不变,将c加1。
if pt.j > l.j {
l.j = pt.j
c.j = 0
} else {
l.j = l.j
c.j := c.j
}
return l.j c.j
收到消息时,l 等于(当前的逻辑时钟的l、机器的本地时钟pt、收到消息里面带的l)三者中的最大值。
如果l部分是更新为本地时钟了,则将c清零。(保证HLC最大,如果本地时钟最大则重置HLC.c=0)
否则,c取较大的那个l对应到的c加1。
l'.j = l.j;
l.j = max(l'.j, l.m, pt.j);
if l.j = l'.j = m.j then c.j = max(c.j, c.m) + 1
else if l.j = l'.j then c.j = c.j + 1
else if l.j = l.m then c.j = c.m + 1
else c.j = 0
return l.j c.j
各节点相互通信的最终结果是,节点的“本地时钟”的物理部分,最终记录的是所有参与者中最大的本地时钟。这里有一个问题是由于HLC是一个 相对的时间所以当集群中有一台机器时间快了的话,所有时间都提前了,另外这个时间不是一个True Time,这样 导致snapshot读的时间和整体系统运行时间不一致
那么HLC怎么实现snapshot 读呢?我们将HLC作为数据的version,假设e和f事件发生成同一节点上,l.e < l.f ,我们引入一个虚拟事件g,l.e+1 <= l.g <= l.f ,并且 c.g = 0,这样的虚拟事件肯定是能找到的,并且引入一个虚构事件并不影响真实事件发生的先后关系。注意了!这个虚拟事件的时钟其实是可以跟全局的节点比较时序的(l.g, 0) ! 也就意味着,我们可以拿一个本地时钟去确定一个快照了!我们读取HLC<=HLC.g的数据即可
快照是只要happens before我的,我一定能够看到。混合逻辑时钟通过保留了物理时钟部分,使得拿到'全局'的时间戳成为可能,而逻辑时钟里面happens before的因果关系仍然可以保留。
Timestamp Oracle(与Tidb 使用raft来实现时间一致,保证性能呢最够好,保证能读到数据即可,使用raft同步一写多读的话性能上会更好点)
无论上面的Ture Time还是Hybrid Logic Time,都是为了在分布式情况下获取全局唯一时间,如果我们整个系统不复杂,而且没有spanner那种跨全球的需求,有时候一台中心授时服务没准就可以了。
在GooglePercolator系统这,他们就提到使用了一个timestamp oracle(TSO)的服务来提供统一的授时服务,为啥叫oracle,我猜想可能底层用的就是oracle数据库。。。
使用TSO的好处在于因为只有一个中心授时,所以我们一定能确定所有时间的时间,但TSO需要关注几个问题:
网络延时,因为所有的事件都需要从TSO获取时间,所以TSO的场景通常都是小集群,不能是那种全球级别的数据库。
性能,TSO是一个非常高频的操作,但鉴于它只干一件事情,就是授时,通常一个TSO每秒都能支持1m+ 以上的QPS,而这个对很多应用来说是绰绰有余的。
容错,TSO是一个单点,所以不得不考虑容错,而这个现在基于zookeeper,etcd也不是特别困难的事情。
所以,如果我们没法实现TrueTime,同时又觉得HLC太复杂,但又想获取全局时间,TSO没准是一个很好的选择,因为它足够简单高效。
TSO方案
作者:羊吃白菜
链接:https://www.jianshu.com/p/18f063573aae
Hybrid Logical Clock (HLC) (sergeiturukin.com)
References
- http://www.cse.buffalo.edu/tech-reports/2014-04.pdf
- Distributed systems for fun and profit
- CS 417 Documents
- pt, for physical time
- l, logical, holds maximumptheard so far
- c, captures causality
附录
1 分布式系统不能使用NTP的原因
NTP是网络时间协议(Network Time Protocol)的缩写,这是一种网络协议,用于同步计算机的时钟与世界统一的时间。通常,单个计算机或网络内的多台计算机可以使用NTP服务器来校准其系统时钟,保持与统一时间(例如,UTC,协调世界时)的一致性,减少时间误差。
但是,在分布式系统中,仅仅依赖NTP来同步时间可能不足够,因为:
1. 分布式系统跨越广泛的地理位置,网络延迟和变化可以造成同步的不精确。
2. NTP无法确保绝对的时钟同步一致性,通常会有毫秒级别的误差,这对于需要高精度时钟同步的分布式系统可能是不可接受的。
3. 分布式系统中的某些算法和应用可能需要比NTP更强的时间协调机制,比如逻辑时钟或向量时钟,它们能够提供系统事件的顺序一致性而不仅仅是时间同步。
因此,虽然NTP可以在分布式系统中提供基本的时钟同步,但它可能不足以满足所有分布式系统所需的精确时间同步要求。复杂的分布式系统可能会采用额外的协议和技术,如真实时间时钟(RTCs)、时钟同步算法(比如Google的TrueTime API),以及各种容错机制来更准确地同步各个节点的时钟。

















 381
381

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









