






什么是LlamaIndex
LlamaIndex是一个用于LLM应用程序的数据框架,用于注入、结构化,并访问私有或特定领域的数据。
入门教程
简单使用
# Linux
export OPENAI_API_KEY=xxx
windows
set OPENAI_API_KEY=xxx
# 代码中加入
API_SECRET_KEY = "xxx"
BASE_URL = "xxx"
os.environ["OPENAI_API_KEY"] = API_SECRET_KEY
os.environ["OPENAI_API_BASE"] = BASE_URL
from llama_index_core import VectorStoreIndex, SimpleDirectoryReader
#加载数据并构建索引
documnets = SimoleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
#查询数据
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(response)
由于每次运行都需要构建所以比较费时,可以保存第一次的索引
#检查索引是否存在
PERSIST_DIR = "./storage"
if not os.path.exists(PERSIST_DIR):
#在这里重新加载数据并构建索引
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
index.storage_context.persist(persist_dir=PERSIST_DIR)
else:
#从存储中加载索引
storage_context = StorageContext.from_defaults(persist_dir=PERSIST_DIR)
index = load_index_from_storage(storage_context)
#查询数据
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(response)
检索增强生成 (RAG)
原理
LlamaIndex 帮助构建 LLM 驱动的,基于个人或私域数据的应用。RAG(Retrieval Augmented Generation) 是 LlamaIndex 应用的核心概念。
RAG 中,您的数据被加载并准备用于查询或“索引”。用户查询作用于索引,索引将数据筛选到最相关的上下文。然后,此上下文和您的查询会随着提示一起转到 LLM,LLM 会提供响应。

文档分块
from llama_index.core import Settings
Settings.chunk_size = 512
from llama_index.core.node_parser import SentenceSplitter
index = VectorStoreIndex.from_documents(
documents,transfromations=[SentnceSplitter(chunk_size=512)]
)
不同向量存储
pip install llama_index_vector_stores_chroma
import chromadb
from llama_index.vector_stores.chroma import ChromaVectorStore
from llama_index.core import StorageContext
chroma_client = chromadb.PersistentClient() #建立交互客户端
chroma_collction = chroma_client.create_collection("quickstart") #创建一个集合j
vector_store = ChromaVectorStore(chroma_collection=chroma_collction) #实例化集合
storage_context = StorageContext.from_defaults(vector_store=vector_store) #完成配置存储上下文
from llama_index.core import VectorStoreIndex,SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(
documents, storage_context=storage_context
)
query_engine = index.as_query_engine()
response = query_engine.query("what did the author do growing up?")
peint(response)
查询检索上下文
from llama_index_core import VectorStoreIndex, SimpleDirectoryReader
documnets = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
#检索器配置为返回前 5 个最相似的文档
query_engine = index.as_query_engine(similarity_top_k=5)
response = query_engine.query("what did the author do growing up?")
peint(response)
使用不同LLM
from llama_index_core import Settings
from llama_index.llms.ollama import Ollama
Settings.llm = Ollama(model="mistral", request_timeout=60.0)
index.as_query_engine(llm=Ollama(model="mistral",request_timeout=60.0))
不同的响应模式
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine(response_mode="tree_summarize")
response = query_engine.query("What did the author do growing up?")
print(response)
流式输出响应
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine(streaming=True)
response = query_engine.query("What did the author do growing up?")
response.print_response_stream()
聊天机器人
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_chat_engine()
response = query_engine.chat("What did the author do growing up?")
print(response)
response = query_engine.chat("Oh interesting, tell me more.")
print(response)
核心概念
RAG
RAG,也称为检索增强生成,是利用个人或私域数据增强LLM的一种范式,它包含两个阶段:
1.索引
构建知识库
2.查询
从知识库检索相关上下文信息,以辅助LLM回答问题。
索引阶段
LlamaIndex 通过提供 Data connectors(数据连接器) 和 Indexes (索引) 帮助开发者构建知识库。
该阶段会用到如下工具或组件:
- Data connectors
数据连接器。它负责将来自不同数据源的不同格式的数据注入,并转换为LlamaIndex支持的文档(Document)表现形势,其中包含了文本和元数据。
- Documents/Nodes
Document是LlamaIndex中容器的概念,它可以包含任何数据源,包括PDF文档、API响应、数据库的数据。
Node是LlamaIndex中数据的最小单元,代表了一个Document的分块。它还包含了元数据以及与其他Node的关系信息。这使得更精确的检索变为可能。
- Data indexs
LlamaIndex 提供便利的工具,帮助开发者为注入的数据建立索引,使得未来的检索简单而高效。
最常用的索引是向量存储索引 - VectorStoreIndex。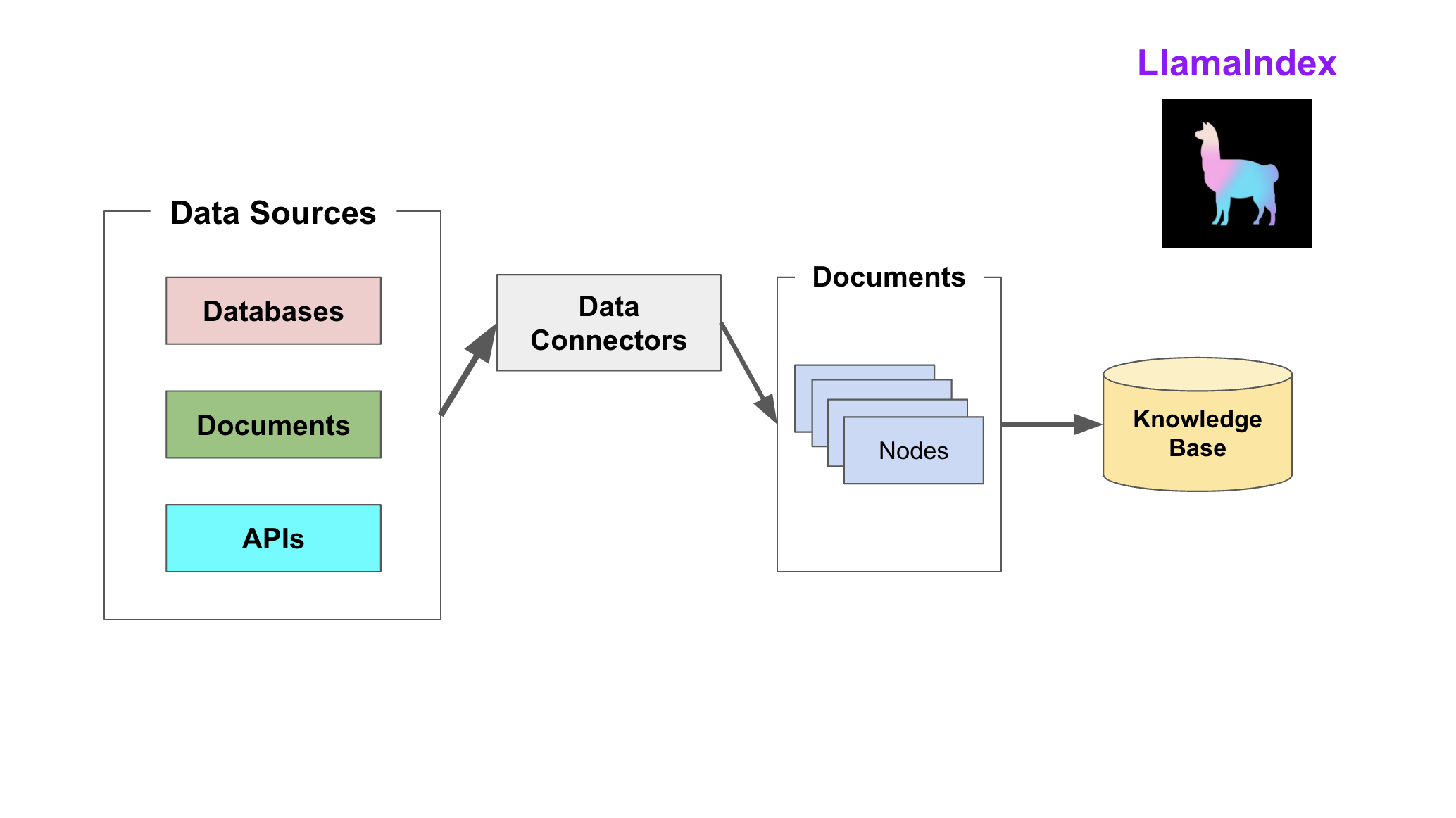
查询阶段
在查询阶段,RAG 管道根据的用户查询,检索最相关的上下文,并将其与查询一起,传递给 LLM,以合成响应。这使 LLM 能够获得不在其原始训练数据中的最新知识,同时也减少了虚构内容。该阶段的关键挑战在于检索、编排和基于知识库的推理。
LlamaIndex 提供可组合的模块,帮助开发者构建和集成 RAG 管道,用于问答、聊天机器人或作为代理的一部分。这些构建块可以根据排名偏好进行定制,并组合起来,以结构化的方式基于多个知识库进行推理。
该阶段的构建块包括:
- Retrievers检索器。它定义如何高效地从知识库,基于查询,检索相关上下文信息。
- Node PostprocessorsNode后处理器。它对一系列文档节点(Node)实施转换,过滤,或排名。
- Response Synthesizers响应合成器。它基于用户的查询,和一组检索到的文本块(形成上下文),利用 LLM 生成响应。
RAG管道包括:
- Query Engines查询引擎 - 端到端的管道,允许用户基于知识库,以自然语言提问,并获得回答,以及相关的上下文。
- Chat Engines聊天引擎 - 端到端的管道,允许用户基于知识库进行对话(多次交互,会话历史)。
- Agents代理。它是一种由 LLM 驱动的自动化决策器。代理可以像查询引擎或聊天引擎一样使用。主要区别在于,代理动态地决定最佳的动作序列,而不是遵循预定的逻辑。这为其提供了处理更复杂任务的额外灵活性。
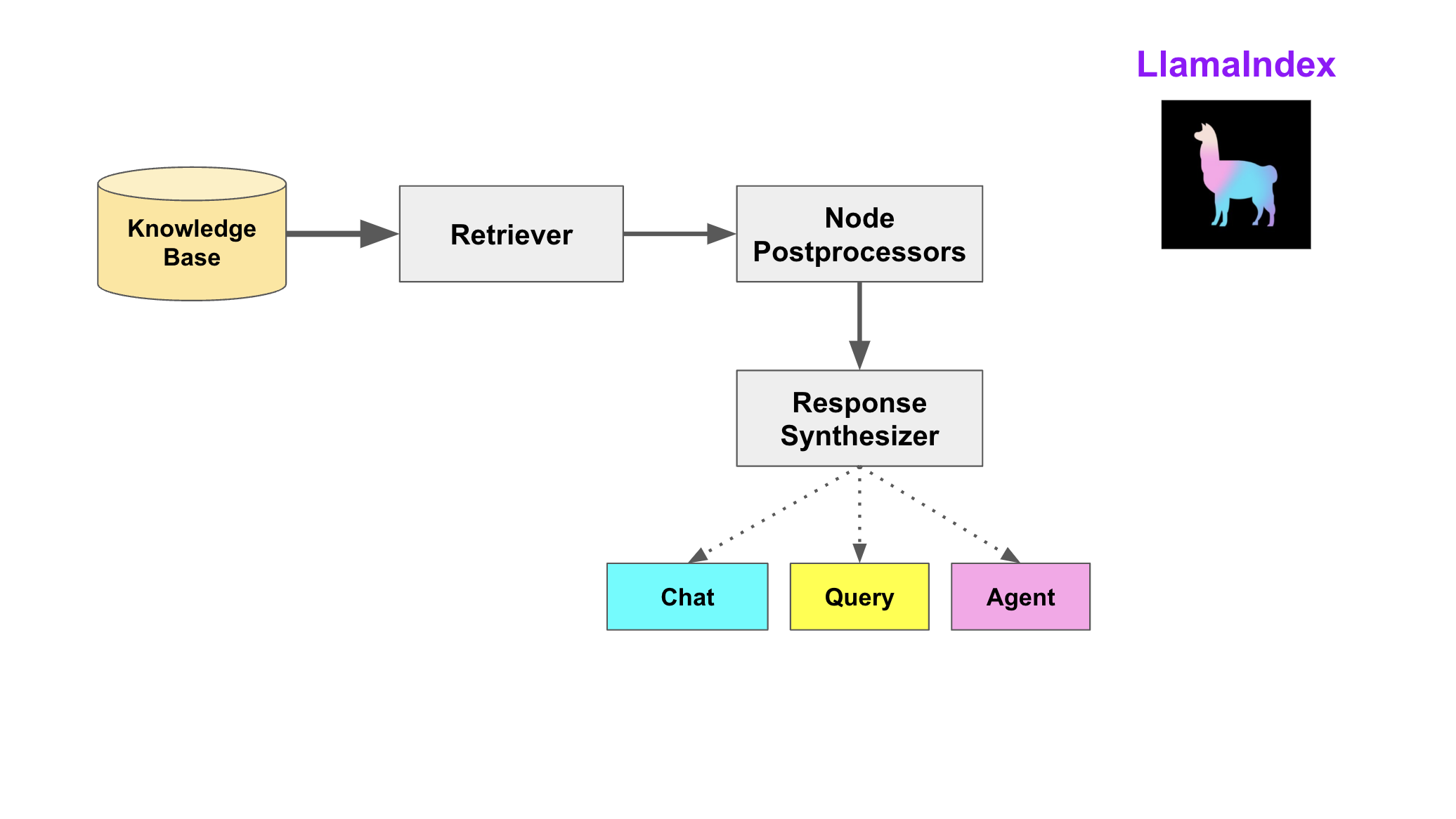
Q&A模式
语义搜索
LlamaIndex 最基本的示例用法是通过语义搜索。
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documnets)
query_engine = index.as_query_engine()
response = query_engine.query("what did the author do growing up?")
print(response)
综述
摘要查询需要 LLM 遍历许多(如果不是大多数)文档才能合成答案。 例如,摘要查询可能如下所示:
- “这本文本集的摘要是什么?”
- “给我总结一下X在公司的经历。”
通常,摘要索引适用于此用例。默认情况下,摘要索引会遍历所有数据。
从经验上讲,设置也会导致更好的汇总结果。response_mode=“tree_summarize”
index = SummaryIndex.from_documents(documents)
query_engine = index.as_query_engine(response_mode="tree_summarize")
response = query_engine.query("摘要查询")
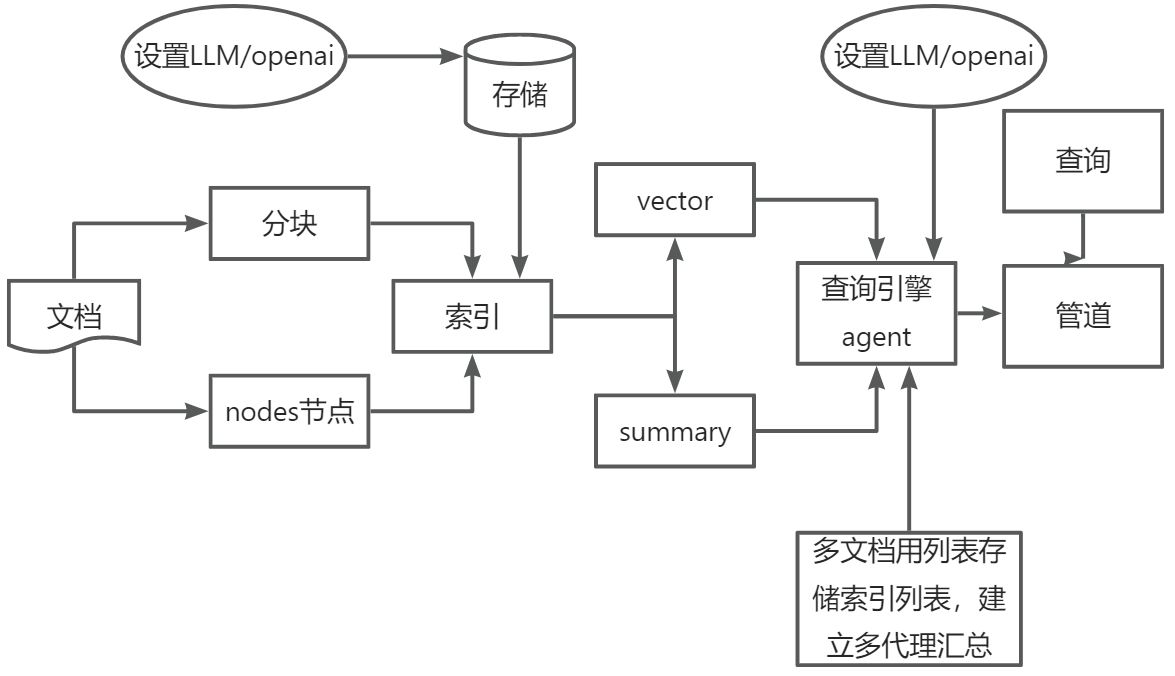
代码解读
import chromadb
from llama_index.vector_stores.chroma import ChromaVectorStore
from llama_index.core import StorageContext,SummaryIndex
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.core import Settings
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core import SimpleNodeParser,QueryEngineTool,ToolMetadata,OpenAIAgent,FnRetrieverOpenAIAgent
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.core import ObjectIndex, SimpleToolNodeMapping
#设置模型
Settings.llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1)
Settings.embed_model = OpenAIEmbedding()
#创建向量存储
chroma_client = chromadb.PersistentClient() # 建立交互客户端
chroma_collction = chroma_client.create_collection("quickstart1") # 创建一个集合
vector_store = ChromaVectorStore(chroma_collection=chroma_collction) # 实例化集合
storage_context = StorageContext.from_defaults(vector_store=vector_store) # 完成配置存储上下文
#分块pdf并建立索引
documents = SimpleDirectoryReader("data").load_data()
Settings.chunk_size = 512
index = VectorStoreIndex.from_documents(
documents, transfromations=[SentenceSplitter(chunk_size=512)],storage_context=storage_context
)
#创建节点解析器
node_parser = SimpleNodeParser.from_defaults(chunk_size=512)
nodes = node_parser.get_nodes_from_documents(documents)
#创建摘要索引
summary_index = SummaryIndex(nodes)
vector_query_engine = index.as_query_engine()
summary_query_engine = summary_index.as_query_engine()
#创建查询引擎工具
query_engine_tools = [
QueryEngineTool(
query_engine=vector_query_engine,
metadata=ToolMetadata(
name="vector_tool",
description=(
"这是一个关于电子银行承兑汇票的票据回单"
),
),
),
QueryEngineTool(
query_engine=summary_query_engine,
metadata=ToolMetadata(
name="summary_tool",
description=(
"这是一个关于电子银行承兑汇票的票据回单"
),
),
),
]
function_llm = OpenAI(model="gpt-4")
agent = OpenAIAgent.from_tools(
query_engine_tools,
llm=function_llm,
verbose=True,
system_prompt=f"""\
你是专门为回答有关问题而设计的代理。
在回答问题时,您必须使用至少一种工具;不依赖于先验知识。\
""",
)
all_tools = []
wiki_summary = (
"你是专门为回答有关问题而设计的代理。"
"在回答问题时,您必须使用至少一种工具;不依赖于先验知识。\n"
)
doc_tool = QueryEngineTool(
query_engine=agent,
metadata=ToolMetadata(
name="bank_tool",
description=wiki_summary,
),
)
all_tools.append(doc_tool)
tool_mapping = SimpleToolNodeMapping.from_objects(all_tools)
obj_index = ObjectIndex.from_objects(
all_tools,
tool_mapping,
VectorStoreIndex,
)
top_agent = FnRetrieverOpenAIAgent.from_retriever(
obj_index.as_retriever(similarity_top_k=3),
system_prompt=""" \
你是一个被设计用来回答关于一组给定城市的查询的代理。
请始终使用提供的工具来回答问题。不依赖于先验知识。\
""",
verbose=True,
)
# 定义了一个“简单”的RAG管道,它将所有文档转储到单个矢量索引集合中。设置top_k = 4
base_index = VectorStoreIndex(nodes)
base_query_engine = base_index.as_query_engine(similarity_top_k=4)
#对比单个文档的QA /摘要到多个文档的QA /摘要
response = top_agent.query("给我讲讲波士顿的艺术和文化吧")
print(response)
response = base_query_engine.query(
"给我讲讲波士顿的艺术和文化吧"
)
print(str(response))
# 定义了一个“复杂”的RAG管道,它将文档分块并建立索引,然后使用OpenAI模型进行回答。设置top_k = 4
query_engine = index.as_query_engine(response_mode="tree_summarize",agent=agent)
response = query_engine.query("这是一个关于什么的么文件?")
print(response)
















 2826
2826











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











