







目录
运行basic_demo/web_demo_gradio.py 报错:
lallma3
llama好用 结合llamaindex做RAG
本地部署lallma3 16g显存ok
本地部署Llama3教程,断网也能用啦!_llama3 本地部署-CSDN博客
ChatGLM3
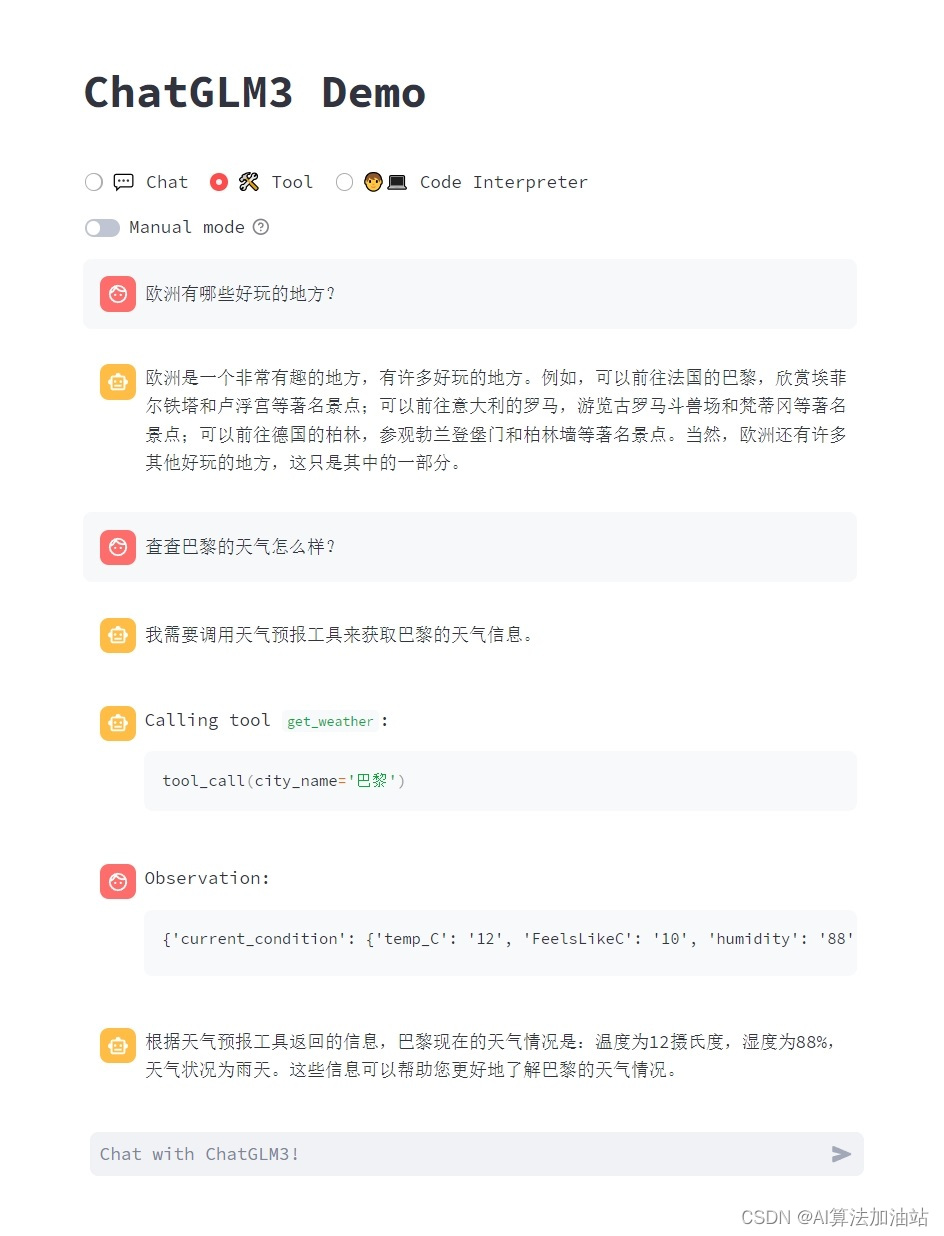
GitHub - THUDM/ChatGLM3: ChatGLM3 series: Open Bilingual Chat LLMs | 开源双语对话语言模型
依赖项
pip install -U langchain-community
pip install -U langchain
pip install -U arxiv
pip install ffmpy
pip install peft
显卡不够报错解决
pip install transformers accelerate -U
运行basic_demo/web_demo_gradio.py 报错:
OSError: Incorrect path_or_model_id: 'THUDM\chatglm3-6b'. Please provide either the path to a local folder or the repo_id of a model on the Hub.\
解决方法:
pip install transformers accelerate -U
MODEL_PATH = os.environ.get('MODEL_PATH', 'THUDM/chatglm3-6b')
MODEL_PATH = r'F:\project\llm\THUDM---chatglm3-6b'
TOKENIZER_PATH = os.environ.get("TOKENIZER_PATH", MODEL_PATH)多卡运行报错:
ImportError: Using `low_cpu_mem_usage=True` or a `device_map` requires Accelerate: `pip install accelerate`
解决方法:
pip install transformers accelerate -U
然后修改代码:
# tokenizer = AutoTokenizer.from_pretrained(TOKENIZER_PATH, trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained(TOKENIZER_PATH,trust_remote_code=True, low_cpu_mem_usage=True)
model = AutoModel.from_pretrained(MODEL_PATH, low_cpu_mem_usage=True,trust_remote_code=True).eval()
# model = AutoModel.from_pretrained(MODEL_PATH, low_cpu_mem_usage=True,trust_remote_code=True, device_map="auto").eval()
多卡运行:
conda activate py310
streamlit run F:\project\llm\ChatGLM3-new\basic_demo\web_demo_streamlit.py
langchain
5 分钟内搭建一个免费问答机器人:Milvus + LangChain-腾讯云开发者社区-腾讯云
chatglm大模型
基于本地知识的问答机器人langchain-ChatGLM 大语言模型实现方法详解_python_脚本之家

















 3576
3576

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











