






点击下面卡片,关注我呀,每天给你送来AI技术干货!
炼丹笔记干货
作者:一元,四品炼丹师
来自:来自炼丹笔记
U-BERT: Pre-training User Representations for Improved Recommendation(AAAI21)
简 介

目前非常多的公司都有专门的团队做用户画像相关的组,在我们的实践中也发现用户画像的好坏对于我们的推荐系统影响是很大的。而如何得到一个好的用户表示也是推荐系统中一个非常重要的问题。现在用户的表示通常是从行为数据中进行学习的,比如点击交互和评论。然而,对于一些不是非常流行的领域,行为数据的稀疏使我们难以学习到精确的用户表示。为了解决这个问题,一个想法是:
利用内容丰富的域来补充用户表示。
受BERT在自然语言处理中的成功经验的启发,我们提出了一种新的基于预训练和微调的U-BERT方法。与典型的BERT应用不同,U-BERT是为推荐而定制的,并利用不同的框架进行预训练和微调。在预训练阶段,U-BERT专注于内容丰富的领域,并引入了一个用户编码器和一个评论编码器来模拟用户的行为。提出了两种预训练策略来学习用户的一般表征;在微调阶段,U-BERT主要关注目标内容不足的域。除了从预训练阶段继承的用户和review编码器之外,U-BERT还引入了一个商品编码器来对商品表示进行建模。此外,还提出了一个评论匹配层来捕获用户评论和项目评论之间更多的语义交互。最后,U-BERT结合用户表示、项目表示和交互信息来提高推荐性能。
模型



1.启发
受下图的影响,同一个用户选择同一组词(以红色突出显示)来表达对两个不同领域的商品的正向意见。如果我们能够模拟他在汽车领域的评论习惯,并将其应用到玩具领域,我们就能更好地预测他对玩具的评价,并推荐更合适的产品。

受到该启发,本文采用BERT技术,并在此基础上进行改进。在预训练和微调阶段,用户的ID集合是一样的,商品的ID集合因为领域的差异一般没有交叉,所以U-BERT在预训练和微调阶段引入了两个不同的框架。详细的参考模型部分。


2.问题定义
我们令 , 分别表示用户集合以及商品集合。用户 关于 写的评价表示为 ,用户 在其它不同的域写的评论表示为 , 和 是类似的,除了它们的item集合不一样。
给定两个评论集合 和 ,用户的集合 和item集合 ,我们的目标是使用所有的输入训练一个模型 ,该模型可以对所有的新的user-item对进行rating的预估来决定是否将item推荐给用户。
Pretraining模型框架

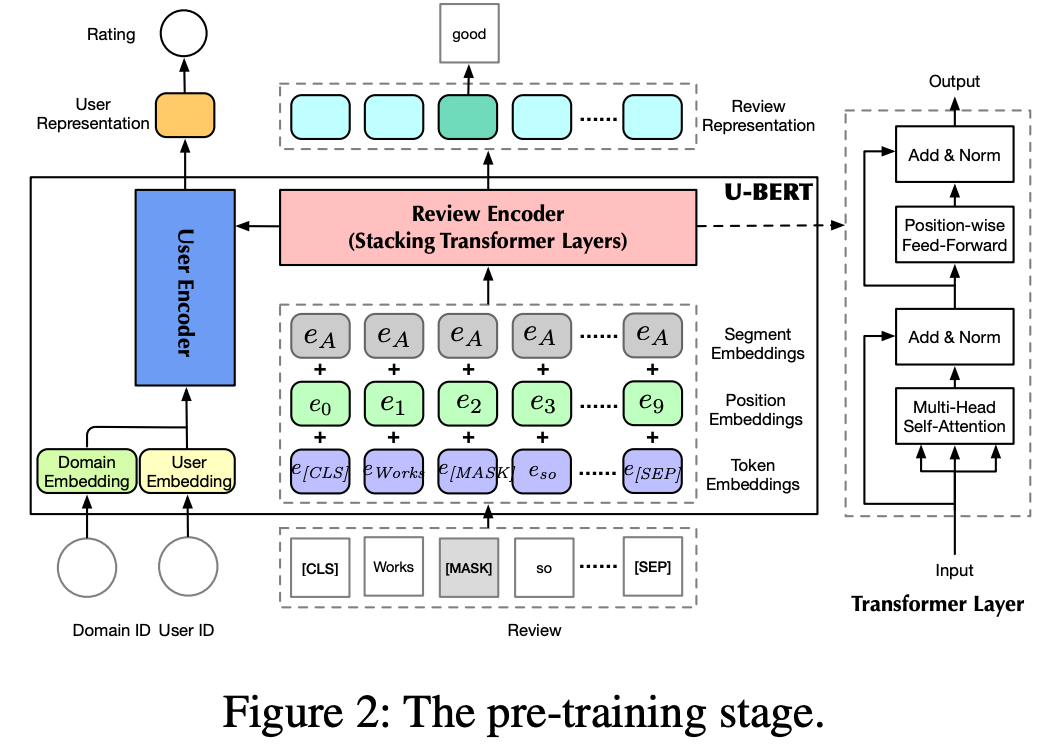
U-BERT使用原始的BERT作为主干,并进行了一些修改以适应推荐任务。U-BERT可以联合建模评论文本和用户。
1.输入层
三个不同的输入,分为为:
用户评论的文本;
用户的ID;
对应域的ID;
其中对于每个评论的文本 ,我们加入 来表示开始和结束,我们将每个词 祝那话为一个 维度的项链, ,其中 是词典 是word embedding的维度。于是我们可以得到输入: , 表示评估文本 的长度。对于每个用户 ,我们也有 ,对于域 ,我们用 进行表示。
2.Review Encoder
Review Encoder是一个多层的Transformer。我们用 表示 层的Transformer层, 表示review encoder的输入。
3.User Encoder
该模块希望将评论的语义信息进行集成并得到一个评论感知的用户表示,它主要由三个模块组成。
3.1.embedding fusion层
为了拟合不同域的评论,我们先对域embedding进行fuse得到特定域的用户emebdding。
3.2.词层面的集成层
不同的词有不同的信息,表示用户的观点也不一样。比如“great”表示的意思会大于“the”,
其中, 是一个可训练的参数。
3.3.fusion层
将review感知的表示s^u \bar{u}$进行fusion得到我们最终的用户表示,即:


Pretraining
该阶段的目标是:
教U-BERT如何将评论信息和用户信息进行融合;
学习更加泛华的用户表示;
此处我们用两种任务来达到这两个目标。
任务1:隐藏的意见Token预测
BERT原始的MLM任务目的是学习语言知识,我们首先随机mask一些单词,然后再对其进行重构,此处我们做了两个微小的改动来学习用户评论的喜好。
当预测masked的单词的时候,除了句子上下文表示外,我们还加入了额外的用户表示来学习用户固有的偏好;
这边我们没有随机mask词,而是选择意见词进行mask和重构,这些意见词在同一用户撰写的不同领域评论中共享,并暗示个人评论偏好。
是被mask的,我们使用bidirectional的上下文表示以及用户表示来重构它。
任务2:观点打分预测
有两种形式的观念表示,用户评论一个商品时有两种意见表达形式:
粗粒度综合评分;
评论文本中的细粒度和各种观点标记;
尽管这两种形式都包含用户偏好信息,它们存在较大差距。虽然使用相同的意见词,不同的用户可能会因为不同的评分偏差而倾向于给出不同的最终评分。例如,用户 在给出等级5时可能更喜欢使用“有趣”,但是用户 在表示“有趣”时可能更喜欢给出等级4。其次,由于表达方式的多样性,相同的最终评级可能对应不同的意见词组合。直觉上,差距来自于用户评论偏好的多样性。因此,通过在用户的其他领域评论中链接两种形式的观点,我们可以捕获他的一般评论偏好,这有助于补充特定域中的用户表示.
最终我们再使用fusion之后的用户表示来进行预测。
其中 .
预训练的loss
Fine-tuning模型框架

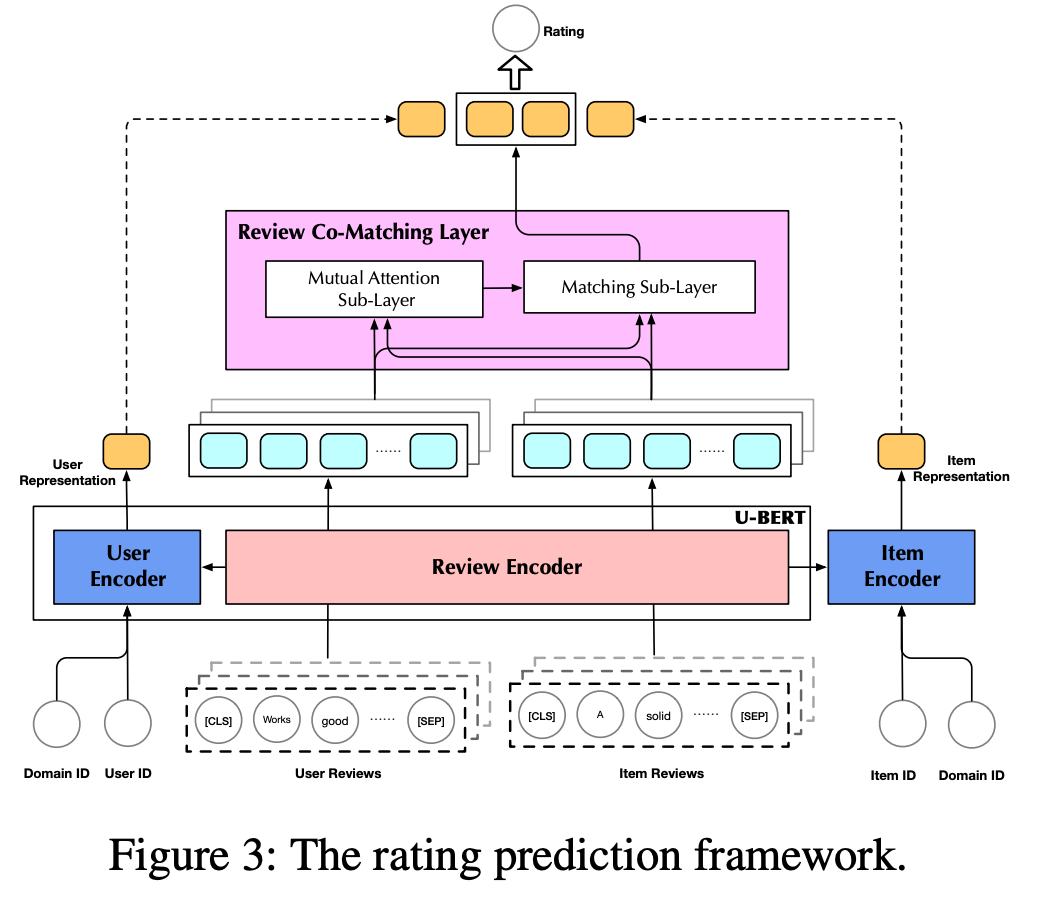
以预训练的U-BERT为骨干的rating预测框架。由于此阶段的输入与训练前阶段的输入略有不同,因此我们对U-BERT进行了一些调整,以适应rating预测任务。
1.输入层
该阶段的输入由五块组成:
域ID;
用户ID;
用户的评论;
商品的ID;
商品的评论。
此处我们使用pretraining阶段的embedding,于是我们可以得到用户embedding, ,用户评论的表示 商品的评论表示 , 和 分别表示用户和商品的评论个数。
2.Review Encoder
因为Transformer很难处理太长的序列,我们将用户/商品的大量评论一个个的使用review ENcoder进行编码,对于用户的第
个评论,最终的上下文表示为:
3.User和Item的Encoder
我们现将所有用户的评论语义信息表示为完整的评论表示,
同时使用
得到特定域的用户表示。
类似地,商品的encoder和用户的encoder有相同的结构。
4.Review Co-Matching层
1.Mutual Attention Sub-Layer
我们使用 对其评论,
2.Matching Sub-Layer
引入匹配层来捕捉原始表示和参与表示之间的语义相似性.
最终我们使用row-wise的max-pooling对matching的信息进行fusion得到用户评论和商品评论的最终表示。
5.预测层
我们使用评论感知的用户和商品表示 以及 来对评分结果进行预测:
6.模型训练Loss
其中 表示特定域的评论语料库。
实验

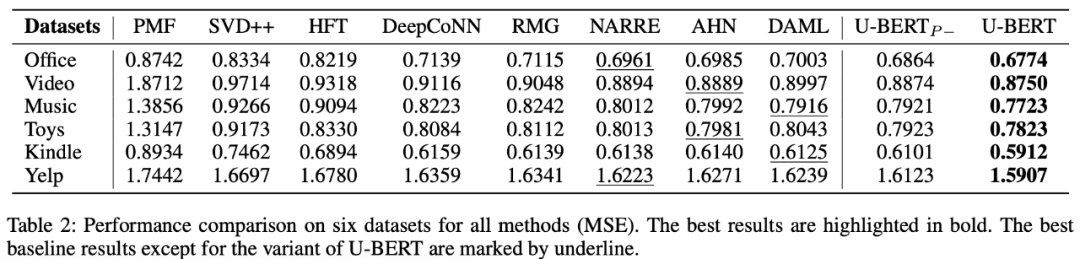

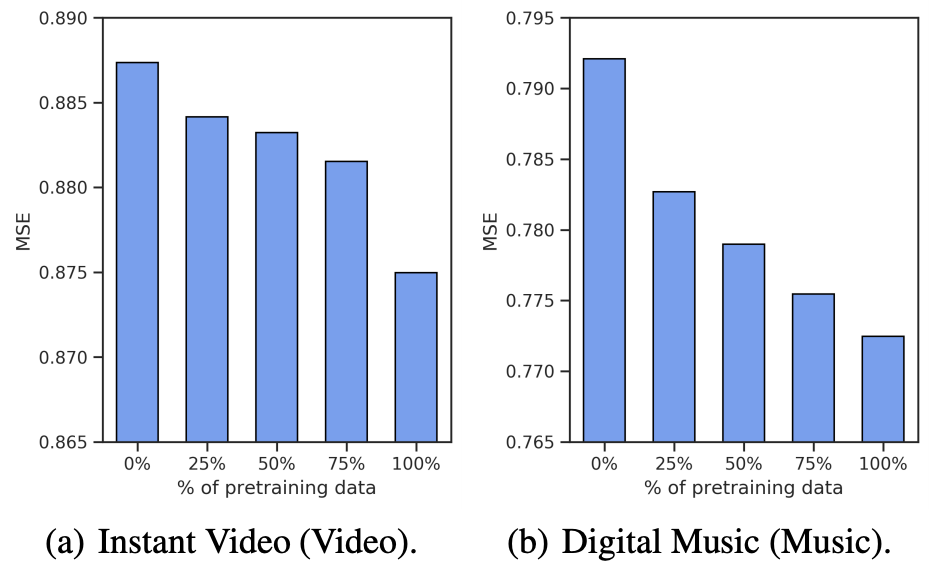
U-BERT相较于所有的其它方法都取得了最好的效果;
task1和2一起使用的效果是最好的;
Pre-training阶段使用的数据越多效果往往越好;
小结

本文提出了一种专为推荐定制的的U-BERT,它基于预训练和微调的用户表示学习和项目推荐模型U-BERT。在预训练阶段,U-BERT利用两个自我监督任务以及其他领域丰富的评论对用户进行建模;在微调阶段,U-BERT利用学习到的用户知识,通过加入新的item编码器和评论匹配层来改进推荐。在所有的6个数据集上,U-BERT都取得了非常大的提升。
参考文献

U-BERT: Pre-training User Representations for Improved Recommendation
说个正事哈
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心 。
。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
点击上面卡片,关注我呀,每天推送AI技术干货~
整理不易,还望给个在看!















 1476
1476











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









