







原理
Mixup 通过将两个或多个样本及其对应的标签进行线性插值组合,生成新的训练样本和标签。其核心思想是利用样本之间的线性组合来扩充数据集,使模型能够学习到更多样的特征和模式。具体来说,对于两个样本及其对应的独热编码标签,按照一定比例进行加权混合,从而得到一个新的样本和标签。
操作步骤
-
从训练集中随机选取两个样本及其对应的标签 :假设我们有训练集样本 x₁ 和 x₂,以及它们对应的标签 y₁ 和 y₂。
-
采样混合比例 λ :从 Beta 分布中采样一个混合比例 λ,Beta 分布由超参数 α 控制。一般情况下,λ 和 1−λ 分别作为两个样本的权重。
-
生成新的样本和标签 :根据混合比例 λ 对两个样本及其标签进行线性插值得到新的样本和标签。具体公式如下:
-
新样本: x = λx₁ + (1−λ)x₂
-
新标签: y = λy₁ + (1−λ)y₂
-
假设有两张图片,一张为鸟类,一张为小熊猫:

按照权重将其混合后如下:

参数解释
-
混合比例 λ :控制两个样本在混合过程中的权重,λ 从 Beta 分布中采样,通常在 0 到 1 之间。Beta 分布的超参数 α 决定了 λ 的分布情况。当 α=1 时,λ 在 0 到 1 之间均匀分布;当 α>1 时,λ 更倾向于接近 0.5;当 α<1 时,λ 更可能接近 0 或 1。
-
样本 x₁ 和 x₂ :从训练集中随机选取的两个样本,可以是图像、文本、语音等不同类型的数据。
-
标签 y₁ 和 y₂ :对应样本 x₁ 和 x₂ 的标签,通常为独热编码形式。
举例
假设我们有一个图像分类任务,训练集中有两张猫的图像和两张狗的图像,它们的标签分别是猫和狗的独热编码。
-
随机选取两张图像 x₁(猫)和 x₂(狗)。
-
假设从 Beta 分布中采样得到 λ=0.7。
-
生成新样本 :将两张图像的像素值按 0.7 和 0.3 的比例加权混合,得到一张新的图像 x = 0.7x₁ + 0.3x₂。这张新图像将同时包含猫和狗的部分特征。
-
生成新标签 :将两张图像的标签按相同的比例加权混合,得到新的标签 y = 0.7y₁ + 0.3y₂。如果猫的标签是 [1,0],狗的标签是 [0,1],则新标签为 [0.7,0.3]。
通过python实现猫狗图像数据增强
import numpy as np
def mixup_data(x, y, alpha=0.2):
"""
生成 Mixup 数据增强的数据。
参数:
x: NumPy 数组,形状为 (batch_size, ...),表示训练样本集。
y: NumPy 数组,形状为 (batch_size, num_classes),表示训练样本的标签,独热编码形式。
alpha: 控制 Beta 分布的超参数,用于采样混合比例 λ。
返回:
新的混合样本 x_mix 和对应的标签 y_mix。
"""
# 生成随机的索引,用于选择第二个样本进行混合
indices = np.random.permutation(len(x))
# 从 Beta 分布中采样混合比例 λ,形状为 (batch_size,)
lam = np.random.beta(alpha, alpha, len(x))
# 将 λ 调整为 (batch_size, 1, 1, 1) 的形状,以便与图像数据相乘
lam = lam.reshape((len(x), ) + (1,) * (x.ndim - 1))
# 混合样本
x_mix = lam * x + (1 - lam) * x[indices]
# 混合标签
y_mix = lam.reshape(-1, 1) * y + (1 - lam.reshape(-1, 1)) * y[indices]
return x_mix, y_mix
# 示例用法
if __name__ == "__main__":
# 示例:猫狗分类,假设我们有 4 个样本
# 假设样本为 28x28x3 的彩色图像,标签为独热编码
x = np.random.rand(4, 28, 28, 3) # 随机生成的图像数据
y = np.array([[1, 0], [0, 1], [1, 0], [0, 1]]) # 猫狗的标签,猫用 [1,0],狗用 [0,1]
# 使用 Mixup 数据增强
x_mix, y_mix = mixup_data(x, y, alpha=0.2)
# 输出混合后的样本和标签查看
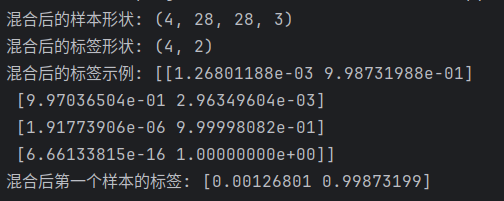
print("混合后的样本形状:", x_mix.shape)
print("混合后的标签形状:", y_mix.shape)
print("混合后的标签示例:", y_mix)
# 打印其中一个混合样本的标签,观察混合情况
print("混合后第一个样本的标签:", y_mix[0])结果如下:
上面的代码主要演示了图像和标签的混合方法,在实际模型训练中,一般不对标签进行混合。而是把损失函数也修改成了线性组合的形式。可以自行推导一下,对于交叉熵损失CE,这种方法和计算之后再计算一个单独的损失函数是等效的。而这种写法可以直接使用torch.nn.CrossEntropyLoss()(因为它仅支持整数型的y),所以非常方便。代码如下:
criterion = nn.CrossEntropyLoss()
for x, y in train_loader:
x, y = x.cuda(), y.cuda()
# Mixup inputs.
lam = np.random.beta(alpha, alpha)
index = torch.randperm(x.size(0)).cuda()
mixed_x = lam * x + (1 - lam) * x[index, :]
# Mixup loss.
pred = model(mixed_x)
loss = lam * criterion(pred, y) + (1 - lam) * criterion(pred, y[index])
optimizer.zero_grad()
loss.backward()
optimizer.step()通过这种方式,Mixup 数据增强技术可以生成大量新的训练样本,扩充数据集的规模,使模型在训练过程中能够学习到样本之间的过渡特征和信息,从而提高模型的泛化能力和鲁棒性。Mixup 扩展方法
Mixup的扩展方法
mixup数据增强方法的问世给深度学习训练开辟了一个新的方向,迅速涌现了大批改进和应用,以下是一些常见的基于mixup改进的数据增强方法。
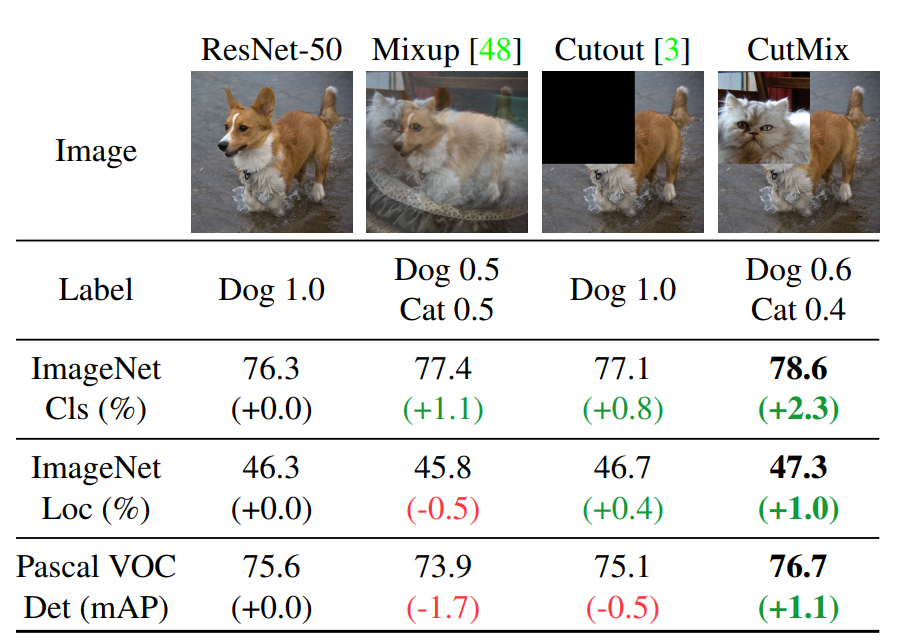
Cutmix
Cutmix 是一种结合了 Mixup 和 Cutout 的数据增强技术。它从一个图像中随机切割出一个矩形区域,并用另一个图像的相应区域替换它。
原理:
-
随机选择一对图像及其对应的标签。
-
在一张图像上随机裁剪出一个矩形框。
-
将另一张图像的相应区域复制到裁剪后的区域。
-
根据裁剪区域的比例调整标签。标签的处理和mixUp是一样的,都是按照新样本中两个原样本的比例确定新的混合标签的比例。

通过python实现cutmix方法:
import numpy as np
import tensorflow as tf
def cutmix(image, label, image2, label2, alpha=0.2):
"""
实现 Cutmix 数据增强。
参数:
image: 第一个输入图像。
label: 第一个输入图像的标签。
image2: 第二个输入图像。
label2: 第二个输入图像的标签。
alpha: 控制混合程度的超参数。
返回:
mixed_image: 混合后的图像。
mixed_label: 混合后的标签。
"""
# 获取图像尺寸
img_size = image.shape[0]
# 生成混合比例
lam = np.random.beta(alpha, alpha)
# 随机选择裁剪区域的大小
cut_size = int(np.sqrt(1. - lam) * img_size)
# 随机选择裁剪区域的左上角坐标
cx = np.random.randint(0, img_size)
cy = np.random.randint(0, img_size)
# 计算裁剪区域的边界坐标
bbx1 = np.clip(cx - cut_size // 2, 0, img_size)
bby1 = np.clip(cy - cut_size // 2, 0, img_size)
bbx2 = np.clip(cx + cut_size // 2, 0, img_size)
bby2 = np.clip(cy + cut_size // 2, 0, img_size)
# 创建混合图像
mixed_image = image.copy()
mixed_image[bbx1:bbx2, bby1:bby2] = image2[bbx1:bbx2, bby1:bby2]
# 创建混合标签
mixed_label = label * lam + label2 * (1. - lam)
return mixed_image, mixed_label
# 示例用法
if __name__ == "__main__":
# 假设我们有两个猫狗分类图像和对应的独热编码标签
image1 = np.random.rand(28, 28, 3) # 随机生成的猫图像
label1 = np.array([1, 0]) # 猫的标签
image2 = np.random.rand(28, 28, 3) # 随机生成的狗图像
label2 = np.array([0, 1]) # 狗的标签
# 使用 Cutmix 数据增强
mixed_image, mixed_label = cutmix(image1, label1, image2, label2, alpha=0.2)
# 输出混合后的图像和标签查看
print("混合后的标签:", mixed_label)Manifold Mixup
Manifold Mixup 是对 Mixup 的扩展,它不仅在输入层进行混合,还在网络的中间层进行混合。
原理:
-
在网络的中间层随机选择两个特征图。
-
对这两个特征图进行线性插值。
-
将混合后的特征图继续向前传播,计算损失。
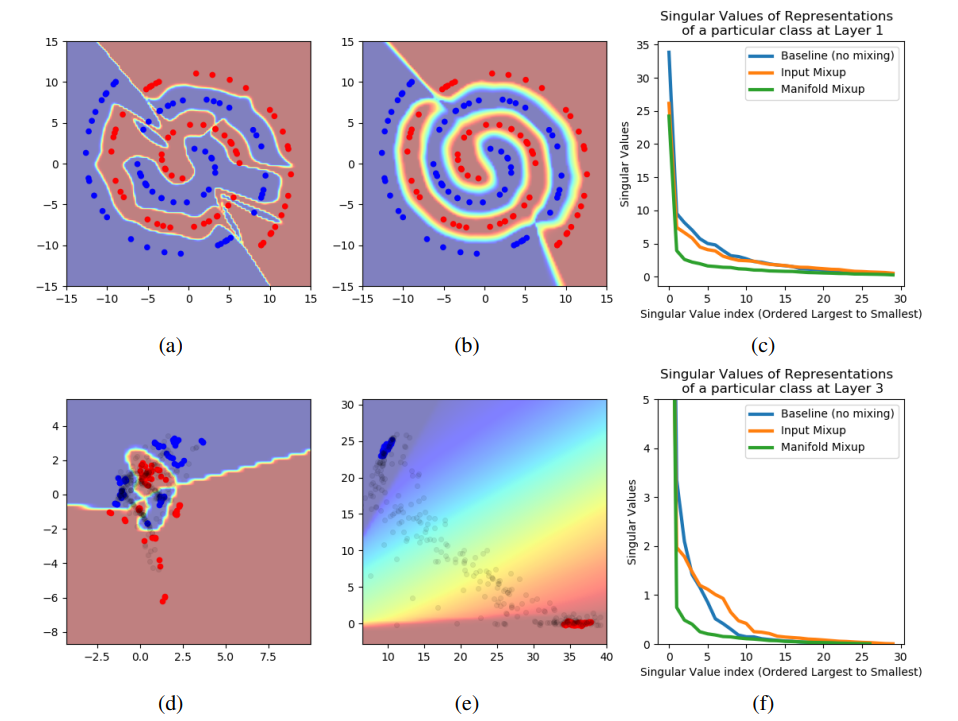
作者对图中的解释如下:在一个在2D螺旋数据集上训练的网络上进行的实验,该网络在中间部分具有2D瓶颈隐藏表示。与常规训练相比,流形mixup对学习有三种影响。首先,它使决策边界更加平滑(从a到b)。其次,它改善了隐藏表示的排列,并鼓励更大范围的低置信度预测区域(从d到e)。黑点是从输入空间范围中均匀采样的输入的隐藏表示。第三,它使表示更加平坦(c在第1层,f在第3层)。其他经过充分研究的层正则化器(输入mixup、权重衰减、dropout、批量归一化以及向隐藏表示添加噪声)并未实现这些效果。
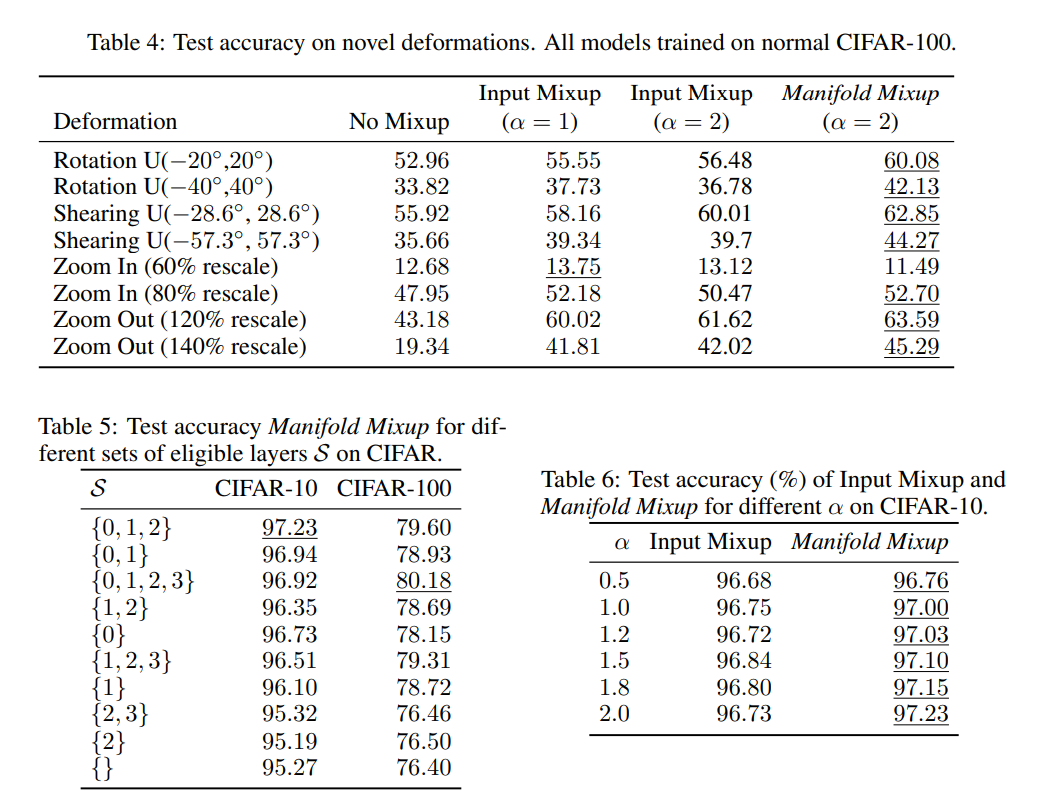
实验结果上相较于mixup也有小范围的提升
这篇论文的理论解释部分比较深奥,看个大概即可,通过python的演示方法如下:
import tensorflow as tf
from tensorflow.keras.layers import Conv2D, Dense, Flatten, Input, Lambda
from tensorflow.keras.models import Model
def manifold_mixup_layer(inputs):
"""
实现 Manifold Mixup 的层。
参数:
inputs: 包含两个特征图的列表。
返回:
混合后的特征图。
"""
x1, x2 = inputs
# 生成混合比例
lam = tf.random.uniform([], 0., 1.)
# 混合特征图
mixed = lam * x1 + (1. - lam) * x2
return mixed
# 示例用法:构建一个简单的 CNN 模型并应用 Manifold Mixup
if __name__ == "__main__":
input_shape = (28, 28, 3)
num_classes = 2
# 输入层
inputs = Input(shape=input_shape)
# 第一个卷积层
x1 = Conv2D(32, (3, 3), activation='relu')(inputs)
# 第二个卷积层
x2 = Conv2D(64, (3, 3), activation='relu')(x1)
# 应用 Manifold Mixup
mixed = Lambda(manifold_mixup_layer)([x1, x2])
# 展平层
x = Flatten()(mixed)
# 全连接层
x = Dense(128, activation='relu')(x)
# 输出层
outputs = Dense(num_classes, activation='softmax')(x)
# 构建模型
model = Model(inputs=inputs, outputs=outputs)
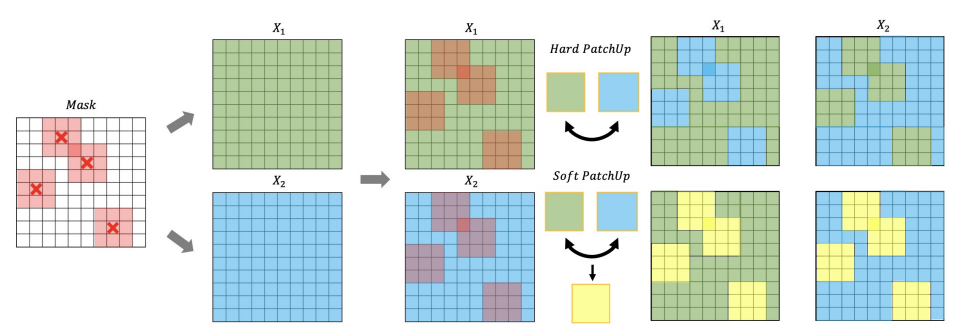
model.summary()PatchUp
PatchUp 也称为 Patch-level Mixup,是 mixup 的改进方法之一,它结合了 manifold mixup 和 cutMix 的思路,在中间隐层输出进行剪裁,对两个不同样本的中间隐层剪裁块进行互换或插值。实验发现互换法在识别精度上更好,插值法在对抗攻击的鲁棒性上更好。
原理
-
PatchUp 方法首先在中间隐层对两个不同样本的特征图进行剪裁。
-
然后,将剪裁后的特征块进行互换或插值。
-
最后,将混合后的特征图继续向前传播,计算损失。
import torch
import torch.nn as nn
import torch.nn.functional as F
class PatchUp(nn.Module):
def __init__(self, alpha=1.0, beta=1.0, patch_size=16):
super().__init__()
self.alpha = alpha
self.beta = beta
self.patch_size = patch_size
def forward(self, x1, x2, labels1, labels2):
# 生成混合比例
lam = torch.distributions.beta.Beta(self.alpha, self.beta).sample()
# 计算剪裁区域的大小
crop_size = int(self.patch_size * lam)
# 在特征图上随机选择剪裁区域
h_start = torch.randint(0, x1.shape[2] - crop_size, (1,)).item()
w_start = torch.randint(0, x1.shape[3] - crop_size, (1,)).item()
# 剪裁特征块
patch1 = x1[:, :, h_start:h_start+crop_size, w_start:w_start+crop_size]
patch2 = x2[:, :, h_start:h_start+crop_size, w_start:w_start+crop_size]
# 互换特征块
mixed_x1 = x1.clone()
mixed_x1[:, :, h_start:h_start+crop_size, w_start:w_start+crop_size] = patch2
mixed_x2 = x2.clone()
mixed_x2[:, :, h_start:h_start+crop_size, w_start:w_start+crop_size] = patch1
# 混合标签
mixed_labels = labels1 * lam + labels2 * (1. - lam)
return mixed_x1, mixed_x2, mixed_labels
# 示例用法
patchup = PatchUp(alpha=2.0, beta=2.0, patch_size=16)
x1 = torch.randn(1, 3, 32, 32) # 假设为第一个样本的特征图
x2 = torch.randn(1, 3, 32, 32) # 假设为第二个样本的特征图
labels1 = torch.tensor([1, 0]) # 第一个样本的标签
labels2 = torch.tensor([0, 1]) # 第二个样本的标签
mixed_x1, mixed_x2, mixed_labels = patchup(x1, x2, labels1, labels2)PuzzleMix
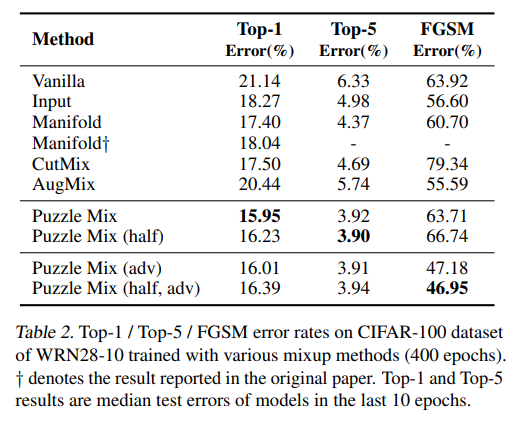
PuzzleMix 是一种结合显著性检测和局部统计信息来优化 Mixup 技术的方法,通过这种方式增强模型的对抗性和鲁棒性。
原理
-
PuzzleMix 借鉴了 manifold mixup 的理念,但在特征图的基础上结合了显著性检测。
-
通过分析特征图的显著性,选择性地混合不同样本的特征,以优化 Mixup 效果。

cutMix合成的图片可能剪裁块正好来自于源图片的非重要区域或者正好把目标图片的重要区域遮挡,这明显和生成的标签不符。因此puzzle Mix首先计算各样本的显著性区域,仅剪裁显著性区域,又进一步加入了一些复杂精细的优化操作,从试验数据看效果很不错。

代码实现如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
class PuzzleMix(nn.Module):
def __init__(self, alpha=1.0, beta=1.0, tau=0.5):
super().__init__()
self.alpha = alpha
self.beta = beta
self.tau = tau
def forward(self, x1, x2, labels1, labels2):
# 生成混合比例
lam = torch.distributions.beta.Beta(self.alpha, self.beta).sample()
# 计算显著性权重
weights1 = torch.sigmoid(x1).mean(dim=1, keepdim=True)
weights2 = torch.sigmoid(x2).mean(dim=1, keepdim=True)
# 根据显著性权重选择性混合
mixed_x = torch.where(weights1 > self.tau, x1, x2)
# 混合标签
mixed_labels = labels1 * lam + labels2 * (1. - lam)
return mixed_x, mixed_labels
# 示例用法
puzzlemix = PuzzleMix(alpha=1.0, beta=1.0, tau=0.5)
x1 = torch.randn(1, 3, 32, 32) # 假设为第一个样本的特征图
x2 = torch.randn(1, 3, 32, 32) # 假设为第二个样本的特征图
labels1 = torch.tensor([1, 0]) # 第一个样本的标签
labels2 = torch.tensor([0, 1]) # 第二个样本的标签
mixed_x, mixed_labels = puzzlemix(x1, x2, labels1, labels2)注意,PatchUp 和 PuzzleMix 的官方实现需要修改网络本身,不能即插即用。上述代码示例仅为简化后的实现,实际应用中可能需要根据具体网络和任务进行调整。
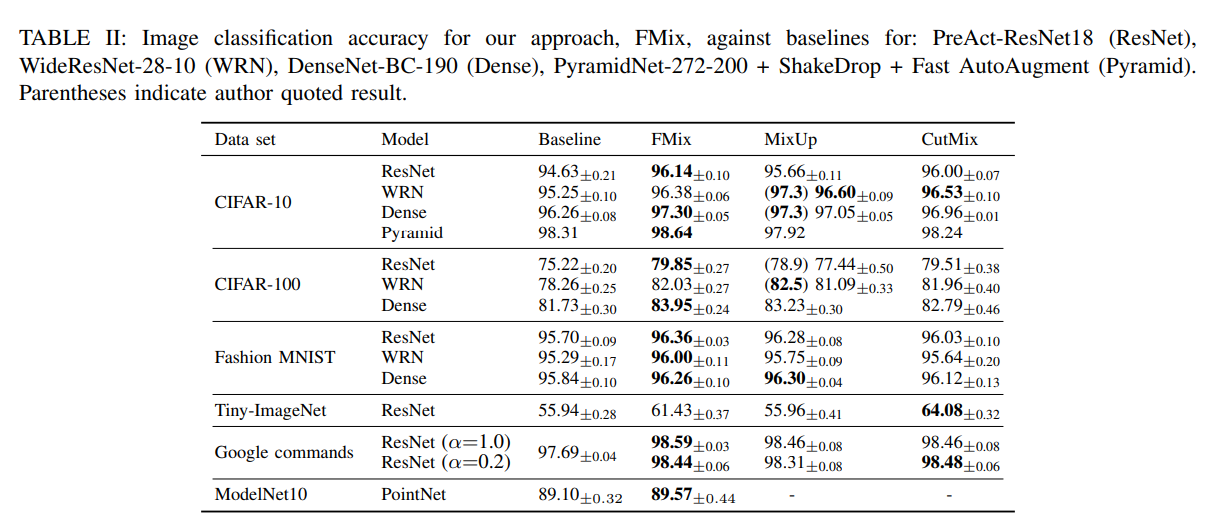
FMix
FMix 是一种基于傅里叶变换的 Mixup 方法。
原理:
-
对图像进行傅里叶变换。
-
在频域中混合两个图像的频谱。
-
对混合后的频谱进行逆傅里叶变换,得到混合图像。

代码实现:
import numpy as np
import tensorflow as tf
def fmix(image, image2, alpha=0.2):
"""
实现 FMix 数据增强。
参数:
image: 第一个输入图像。
image2: 第二个输入图像。
alpha: 控制混合程度的超参数。
返回:
mixed_image: 混合后的图像。
"""
# 将图像转换为频域
fft_image = tf.signal.fft2d(tf.cast(image, tf.complex64))
fft_image2 = tf.signal.fft2d(tf.cast(image2, tf.complex64))
# 生成混合比例
lam = np.random.beta(alpha, alpha)
# 创建一个随机的频谱混合 mask
mask = np.random.binomial(1, lam, size=image.shape[:2])
# 混合频谱
mixed_fft = mask[..., np.newaxis] * fft_image + (1 - mask[..., np.newaxis]) * fft_image2
# 将混合后的频谱转换回空间域
mixed_image = tf.cast(tf.math.abs(tf.signal.ifft2d(mixed_fft)), tf.float32)
return mixed_image
# 示例用法
if __name__ == "__main__":
# 假设我们有两个猫狗分类图像
image1 = np.random.rand(28, 28, 3) # 随机生成的猫图像
image2 = np.random.rand(28, 28, 3) # 随机生成的狗图像
# 使用 FMix 数据增强
mixed_image = fmix(image1, image2, alpha=0.2)
# 输出混合后的图像查看
print("混合后的图像形状:", mixed_image.shape)

















 1050
1050

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









