







聚类分析:
将数据所研究对象进行分类的统计方法,事先不知道类别的个数和结构。分析对象之间的相似性(similarity)或相异性(dissimilarity),这种相似或相异性看成是一种距离远近的度量,距离近的归为一类,不同类之间的对象距离较远。
根据分类对象不同分为Q型聚类分析和R型聚类分析。Q型聚类分析是对样本进行聚类,R型聚类分析是对变量进行聚类分析。
距离:
-
绝对值距离:

-
Euclide距离(欧式距离):

-
Minkowski距离:当各变量的单位不同或测量值范围相关很大时,应先对各变量数据作标准化处理,再用标准化后的数据进行计算。

-
Chebyshev(切比雪夫)距离:

-
Mahalanobis距离(马式距离):S为样式方差矩阵,好处是考虑了各变量之间的相关性,且与变量单位无关,缺陷是S难以确定。

-
Lance和Williams距离:x > 0, I = 1,2,...,n, j = 1,2,...,p

-
定性变量样式间距离:
设样本
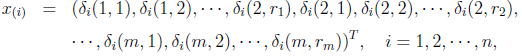
其中n为样本个数,m为项目个数,r(k)为第k个项目的类目数
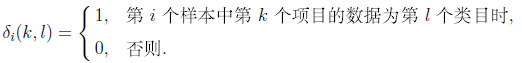
称其为第k个项目之l类在第I个样本中的反应。
记m1为两个样本在m个项目所有类目中1-1配对的总数,m0为0-0配对的总数,m2为不配对的总数,则两个样本之间的距离定义为
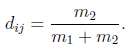
数据中心化和标准化变换:
-
中心化变换:变换后数据的均值为0,方差阵不变。

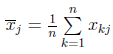
-
标准化变换:变换后每个变量的样本均值为0,标准差为1,标准化后的数据与变量的量纲无关。
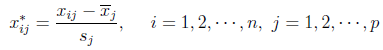
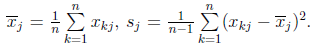
-
极差标准化变换:变换后每个变量的样本均值为0,极差为1,且|x| < 1,变换后数据是无量纲的量。
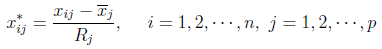
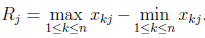
-
极差正规化变换:变换后数据0<= x <= 1,极差为1,无量纲量。
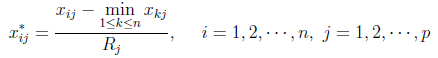
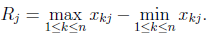
相似系数:
对变量进行分类时,常用相似系数来度量变量之间的相似程度。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









