







线性判别分析
线性判别分析又称为Fisher判别分析,因为其最早是由Fisher提出来处理二分类问题。线性判别分析的思想非常的简单,其就是要确定一条直线,当所有样本点投影到该条直线上的时候,能够保证同类样本的投影点尽可能集中,而不同类的样本的投影点则相聚较远。当有一个新样本来的时候,可以将该样本投影到这条直线上并归类到最近的类别中心所在类。
假设我们现在样本点归属于两个类A和B,这两类样本的均值向量分别为
μA
和
μB
,方差分别为
ΣA
和
ΣB
,又假设我们现在已经确定了一条直线
y=ωTx
,那么这两类样本到直线投影点的中心分别为
ωTμA
和
ωTμB
,两类样本的协方差分别为
ωTΣAω
和
ωTΣBω
。直线与样本的关系如下图所示:
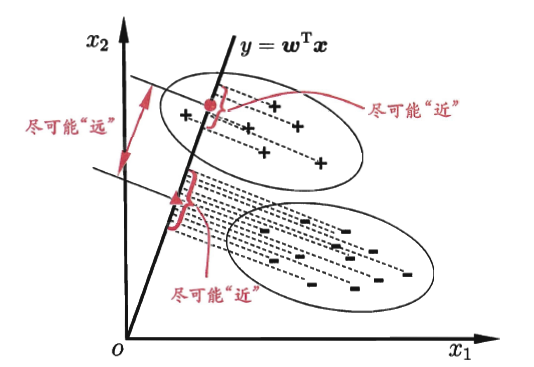
我们可以看到我们希望所寻找的直线能够使得同类样本在直线上的投影尽可能的近,而不同类样本之间的距离尽可能的远。对于同类样本,我们利用协方差来衡量样本投影点之间的密集程度,而不同类样本,则是利用另个列别中心的距离来衡量。故我们可以得到想要最大化的目标是
令 Sb=(μA−μB)(μA−μB)T , Sω=ΣA+ΣB ,其中 Sb 称为类间散度矩阵, Sω 称为类内散度矩阵。这样我们的优化目标就可以转为
这样我们就得到一个拉格朗日函数
这里说明两点:
- (μA−μB)Tω 为一个常数;
- 因为 ω 可以任意的放大或缩小,因此我们可以直接将等号两边的 λ 和 λω 约掉,相当于将参数 ω 放大了 λωλ 倍
这样我们就可以得到最优的参数解,如果矩阵
Sω
的逆,通常会利用奇异值分解(SVD)来求得。
对于多分类问题,我们也可以使用类似的思想来进行训练,类内散度矩阵不变,即我们依然要让各个类投影到直线上的点尽可能的聚集在一起,而类间散度矩阵则需要改变,因为此时是多个类的样本的投影,而原有的类间散度矩阵衡量的是两个类之间的距离。令
μ
为所有样本的样本均值,而
μi
则表示第
i
类样本的样本均值,此时我们可以定义另一种类间散度矩阵















 571
571

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









