







一、背景
基于知识的人脸检测方法:
模板匹配、人脸特征、形状与边缘、纹理特性、颜色特征、形状与边缘
基于统计的人脸检测方法:
主成分分析与特征脸、神经网络方法、支持向量机、隐马尔可夫模型、Adaboost算法
Haar分类器 = Haar-like特征 + 积分图方法 + AdaBoost +级联;
二、Haar like特征
在使用haar like特征做人脸识别时的3类的haar原型特征:
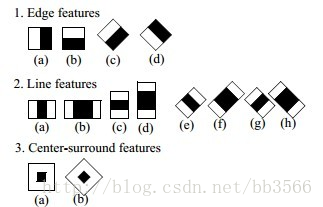
将feature放到图像上,黑色矩形像素值的和减去白色矩形像素值的和得到一个特征值(此处需要积分图的概念(Integral Image)积分图就是只遍历一次图像就可以求出图像中所有区域像素和的快速算法,大大的提高了图像特征值计算的效率。),该特征值就是haar特征,使用该特征值计算弱分类器的。
PAC(Probably Approximately Correct) --> Boosting算法 -->
三、弱分类器
弱分类器的构成:窗口图像x, 特征f,指示不等号方向的p和阈值theta。
在分类的应用中,每个非叶子节点都表示一种判断,每个路径代表一种判断的输出,每个叶子节点代表一种类别,并作为最终判断的结果。
最重要的就是如何决定每个结点判断的输出,要比较输入图片的特征值和弱分类器中特征,一定需要一个阈值,当输入图片的特征值大于该阈值时才判定其为人脸。
训练最优弱分类器的过程实际上就是在寻找合适的分类器阈值,使该分类器对所有样本的判读误差最低。
具体操作过程如下:
1)对于每个特征 f,计算所有训练样本的特征值,并将其排序。
扫描一遍排好序的特征值,对排好序的表中的每个元素,计算下面四个值:
全部人脸样本的权重的和t1;
全部非人脸样本的权重的和t0;
在此元素之前的人脸样本的权重的和s1;
在此元素之前的非人脸样本的权重的和s0;
2)最终求得每个元素的分类误差
该阈值将当前元素前(含)的元素分为人脸(或非人脸),而将当前元素后的元素分为非人脸(或者人脸)。可以认为分类误差为: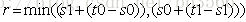
四、强分类器
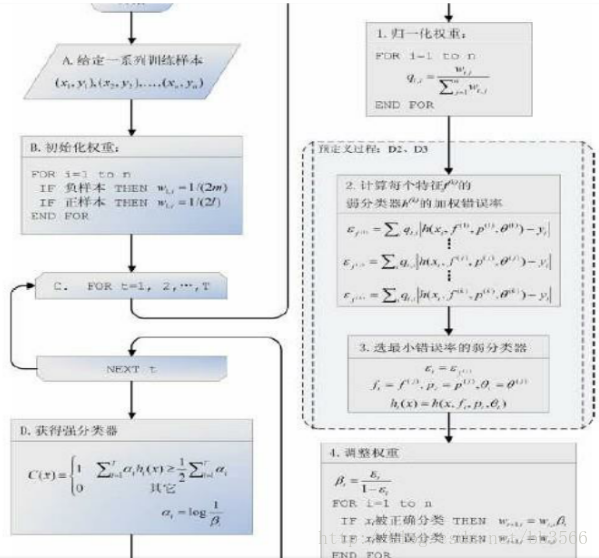
需要T轮的迭代,具体操作如下:
1. 给定训练样本集S,共N个样本,其中X和Y分别对应于正样本和负样本; T为训练的最大循环次数;
2. 初始化样本权重为1/N ,即为训练样本的初始概率分布;
3. 第一次迭代训练N个样本,计算加权你错误率,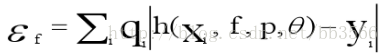
4. 提高上一轮中被误判的样本的权重;

5. 将新的样本和上次本分错的样本放在一起进行新一轮的训练。
6. 循环执行4-5步骤,T轮后得到T个最优弱分类器。
7.组合T个最优弱分类器得到强分类器,组合方式如下:



让所有弱分类器投票,再对投票结果按照弱分类器的错误率加权求和,将投票加权求和的结果与平均投票结果比较得出最终的结果。
检出率f:被正确检测所出的人脸数/人脸样本总数
误识率d:被误判为人脸的样本数/全部非人脸的样本数

检出率和误判率随着阈值的减小而增大。(阈值为0,all样本将会被判断为人脸,100%的检出率和误判率)
增加分类器的数目可以减小误判
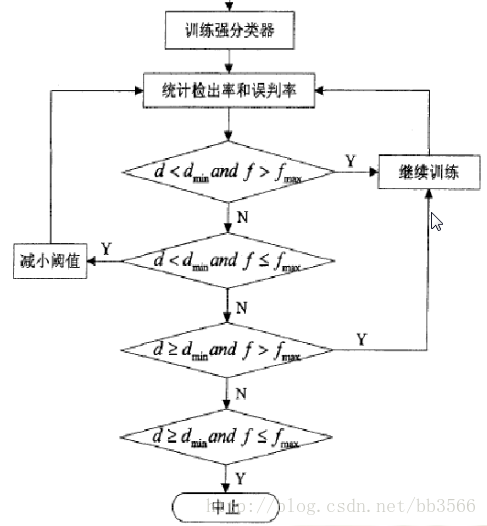
算法过程:
五、级联分类器

级联强分类器的策略是,将若干个强分类器由简单到复杂排列,希望经过训练使每个强分类器都有较高检测率,而误识率可以放低,比如几乎99%的人脸可以通过,但50%的非人脸也可以通过,这样如果有20个强分类器级联,那么他们的总识别率为0.99^20=81%,错误接受率也仅为0.5^20=0.0001%。这样的效果就可以满足现实的需要
级联分类器在训练时要考虑如下平衡,一是弱分类器的个数和计算时间的平衡,二是强分类器检测率和误识率之间的平衡。

六、adaboost 检测部分
训练级联分类器的目的就是为了检测的时候更加准确,涉及到Haar分类器的另一个体系,检测体系,检测体系是以现实中的一幅大图片作为输入,然后对图片中进行多区域,多尺度的检测,所谓多区域,是要对图片划分多块,对每个块进行检测。由于训练的时候用的照片一般都是20*20左右的小图片,所以对于大的人脸,还需要进行多尺度的检测。
多尺度检测机制一般有两种策略,一种是不改变搜索窗口的大小,而不断缩放图片,这种方法显然需要对每个缩放后的图片进行区域特征值的运算,效率不高,而另一种方法,是不断初始化搜索窗口size为训练时的图片大小,不断扩大搜索窗口,进行搜索,解决了第一种方法的弱势。在区域放大的过程中会出现同一个人脸被多次检测,这需要进行区域的合并
图像缩放法(图像金字塔,要考虑相邻图像缩小级别;过大:漏检;过小:冗余计算),检测窗口放大法(需要重新调整计算Haar特征值)

其他策略:
考虑到视频中人脸检测的特殊性,上一帧人脸的位置信息对下一帧的检测有很高的指导价值,所以采有帧间约束的方法,减少了人脸搜索的区域,并且动态调整Haar检测函数的参数,得到了较高的效率。
参考引用:
http://www.cnblogs.com/ello/archive/2012/04/28/2475419.html















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









