







一、数据挖掘通用框架
估计器:用于分类、聚类和回归分析。
转换器:用于数据预处理和数据转换。
流水线:组合数据挖掘流程,便于再次使用。
二、scikit-learn估计器
支持向量机SVM、随机森林、神经网络等,本节用近邻算法估计器分类。主要包括fit()和predict()函数。用fit方法在训练集上完成模型的创建,用predict方法在测试集上评估效果。
近邻算法:为了对新个体进行分类,查找训练集,找到与新个体最相似的那些个体,看看这些个体大多属于哪个类别,就把新个体分到哪个类别。
k近邻算法:给定测试样本,基于某种距离度量找出训练集中与其最靠近的k个训练样本,然后基于这k个"邻居"的信息来进行预测。
三、近邻算法估计器分类的代码实现
数据集加载并处理
ionosphere数据集下载链接:http://archive.ics.uci.edu/ml/datasets/Ionosphere。
将特征读入数组x中,类别读入数组y中(351行34列)
import os
import numpy as np
import csv
data_filename = os.path.join('.\data', 'ionosphere.data')
x = np.zeros((351, 34), dtype='float')
y = np.zeros((351,), dtype='bool')
with open(data_filename, 'r') as input_file:
reader = csv.reader(input_file)
for i, row in enumerate(reader):
data = [float(datum) for datum in row[:-1]]
x[i] = data
y[i] = row[-1] == 'g'创建训练集和测试集
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=14)导入k近邻分类器
from sklearn.neighbors import KNeighborsClassifier
estimator = KNeighborsClassifier()用训练集训练数据
# K近邻估计器分析训练集中的数据,比较待分类的新数据点和训练集中的数据,找到新数据点的近邻
estimator.fit(x_train, y_train)测试集测试
y_predicted = estimator.predict(x_test)
accuracy = np.mean(y_test == y_predicted) * 100
print("The accuracy is {0:1f}%".format(accuracy))测试结果截图

提升分类精度
(1)通过交叉验证提升分类精度
cross_val_score : sklearn.model_selection.cross_val_score,默认折数为5,得到K折验证中每一折的得分,K个得分取平均值就是模型的平均性能。
from sklearn.model_selection import cross_val_score
scores = cross_val_score(estimator, x, y, scoring='accuracy')
average_score = np.mean(scores) * 100
print("The accuracy is {0:1f}%".format(average_score))
(2)通过调整参数提升分类精度
近邻算法有多个参数,最重要的就是选取多少个近邻作为预测依据。scikit-learn管这个参数叫n_neighbors。观察1-20的n_neighbors所带来的结果之间的差异。
from matplotlib import pyplot as plt
avg_scores = []
all_scores = []
paramter_neighbors = list(range(1, 21))
for neighbors in paramter_neighbors:
estimator = KNeighborsClassifier(n_neighbors=neighbors)
scores = cross_val_score(estimator, x, y, scoring='accuracy')
avg_scores.append(np.mean(scores))
all_scores.append(scores)
# 用图表来表示n_neighbors的不同取值和分类正确率之间的关系
plt.plot(paramter_neighbors, avg_scores, '-o')
plt.show()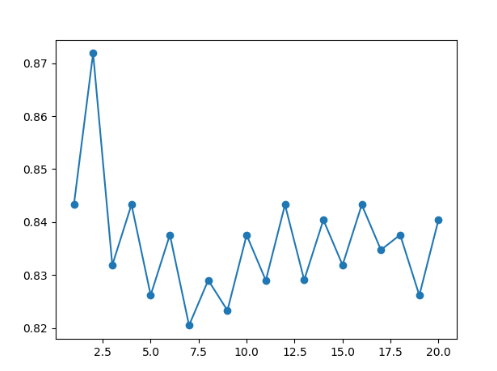
四、scikit-learn转换器Transformer
用来处理数值型特征和抽取特征。
sklearn.preprocessing.MinMaxScaler:基于特征的规范化,以把每个特征的值域规范化为0到1之间。
sklearn.preprocessing.Normalizer:为使每条数据各特征值的和为1。
sklearn.preprocessing.StandardScaler:使各特征的均值为0,方差为1,常用作规范化的基准。
sklearn.preprocessing.Binarizer:将数值型特征的二值化,大于阈值的为1,反之为0。
# 破坏后的数据集准确率从原来未破坏的86.4% 降到 73.8%
x_broken = np.array(x)
x_broken[:, ::2] /= 10
estimator = KNeighborsClassifier()
original_score = cross_val_score(estimator, x, y, scoring='accuracy')
print("The original score is {0:1f}%".format(np.mean(original_score)*100))
broken_score = cross_val_score(estimator, x_broken, y, scoring='accuracy')
print("The broken score is {0:1f}%".format(np.mean(broken_score)*100))
# 经过转换后的数据集准确率又回到了82.9%
from sklearn.preprocessing import MinMaxScaler
x_transform = MinMaxScaler().fit_transform(x_broken)
estimator = KNeighborsClassifier()
transform_score = cross_val_score(estimator, x_transform, y, scoring='accuracy')
print('The transform score is {0:1f}%'.format(np.mean(transform_score)*100))
五、流水线结构
流水线的输入为一连串的数据挖掘步骤,其中最后一步必须是估计器,前几步是转换器。
输入的数据集经过转换器的处理后,输出的结果作为下一步的输入。最后,用位于流水线最后一步的估计器对数据进行分类。
创建流水线
(1) 用MinMaxScaler将特征取值范围规范到0~1。
(2) 指定KNeighborsClassifier分类器。
每一步都用元组(‘名称’,步骤)来表示,现在来创建流水线 ,sklearn.Pipline.Pipeline。
from sklearn.pipeline import Pipeline
scaling_pipline = Pipeline([('scale', MinMaxScaler()), ('predict', KNeighborsClassifier())])2.运用流水线
transformed_scores = cross_val_score(scaling_pipline, x_broken, y, scoring='accuracy')
print("The pipeline scored an average accuracy for is {0:.2f}%".format(np.mean(transformed_scores) * 100))
六、小结
用scikit-learn库提供的几个方法,创建了运行和评估数据挖掘模型的标准工作流。
介绍了近邻算法。
通过解决不同特征值域影响分类效果的问题,讲解了预处理方法,主要用到了转换器对象和MinMaxScaler类。















 738
738











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









