









查询操作
- 1
- 2
- 1
- 2
底层的实现
mapreduce
常见的聚合操作
count计数
- 1
- 2
- 3
- 1
- 2
- 3
sum求和
sum(可转成数字的值) 返回bigint
avg求平均值
avg(可转成数字的值)返回double
distinct不同值个数
count(distinct col)
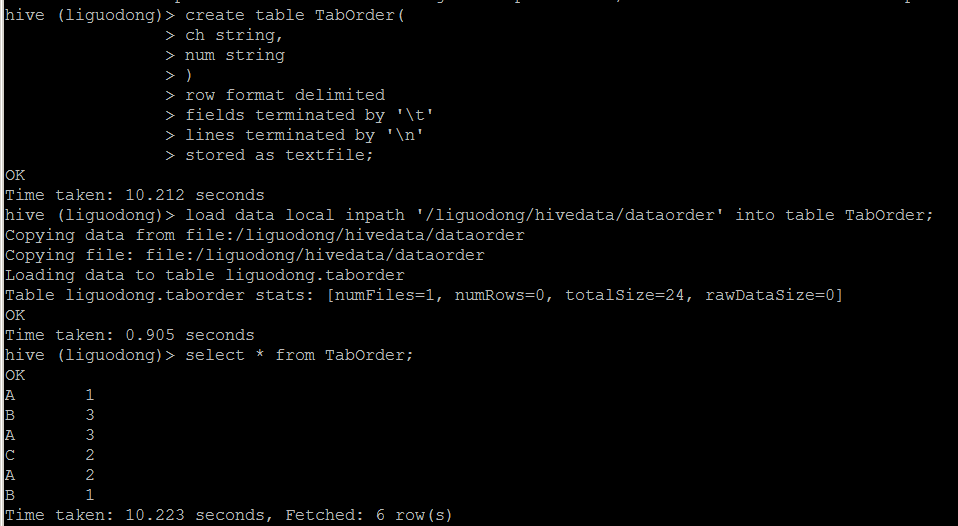
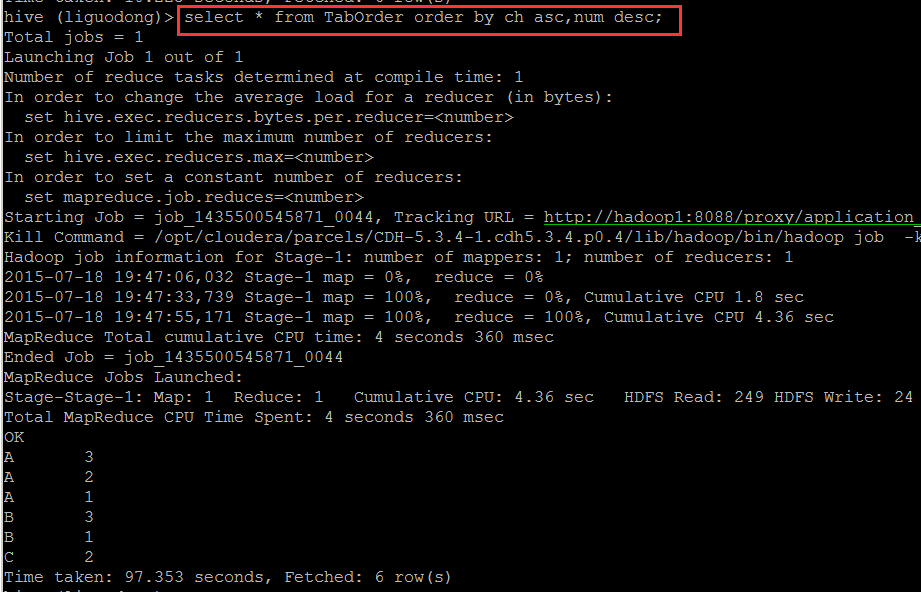
order by
按照某些字段排序
样例
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
注意
order by后面可以有多列进行排序,默认按字典排序
order by为全局排序
order by需要reduce操作,且只有一个reduce,与配置无关。数据量很大时,慎用。
执行流程
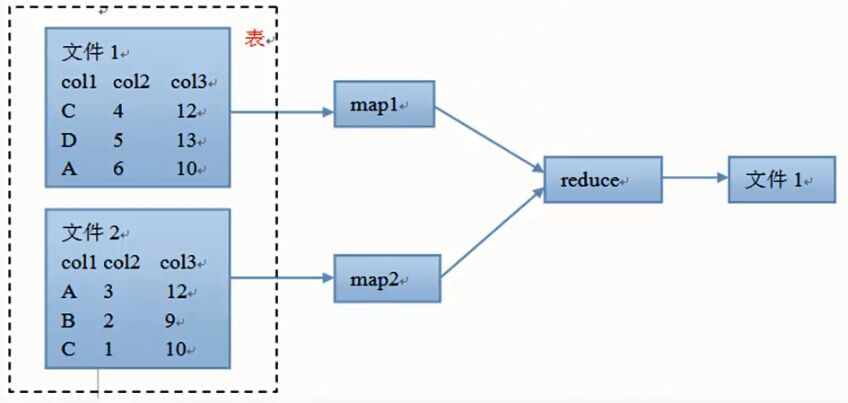
从表中读取数据,执行where条件,以col1,col2列的值做成组合key,其他列值作为value,然后在把数据传到同一个reduce中,根据需要的排序方式进行。
group by
按照某些字段的值进行分组,有相同值放到一起。
样例
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
注意
select后面非聚合列,必须出现在group by中
select后面除了普通列就是一些聚合操作
group by后面也可以跟表达式,比如substr(col)
特性
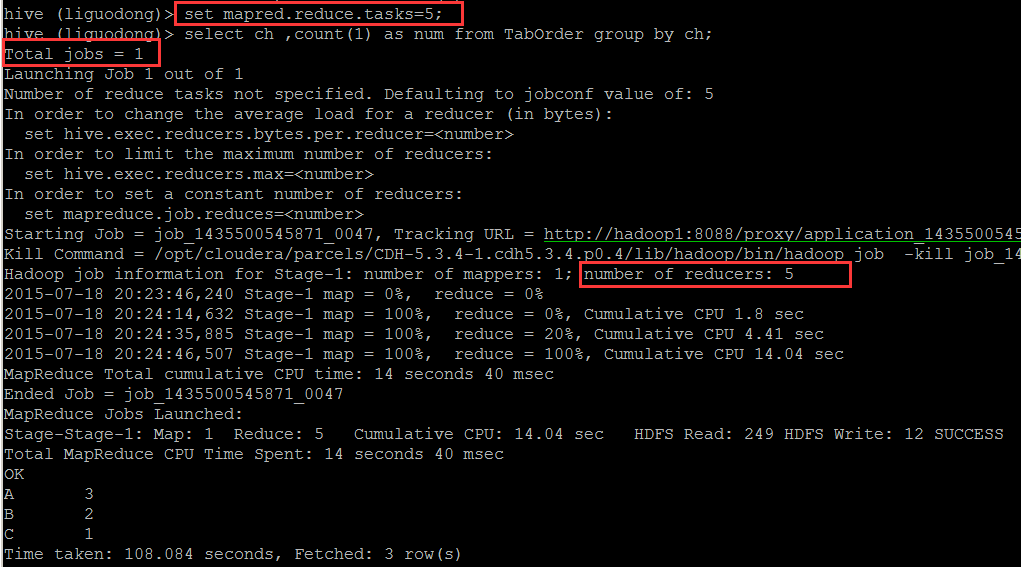
使用了reduce操作,受限于reduce数量,设置reduce参数mapred.reduce.tasks
输出文件个数与reduce数相同,文件大小与reduce处理的数据量有关。
问题
网络负载过重
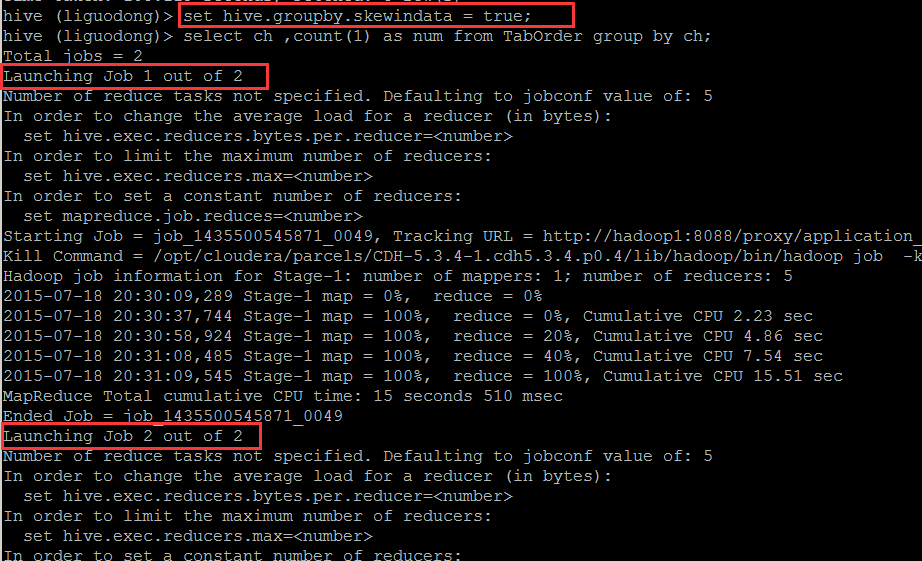
数据倾斜,优化参数Hive.groupby.skewindata为true,会启动一个优化程序,避免数据倾斜。
执行流程
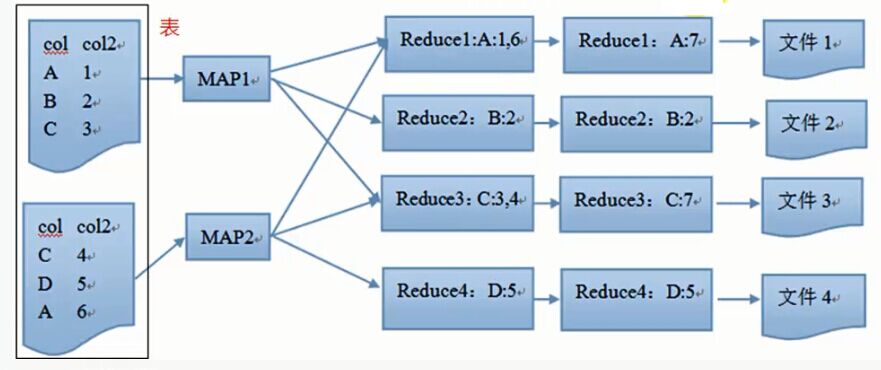
从表中读取数据,执行where条件,以col1列分组,把col列的内容作为key,其他列值作为value,上传到reduce,在reduce端执行聚合操作和having过滤。
eg:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Join表连接
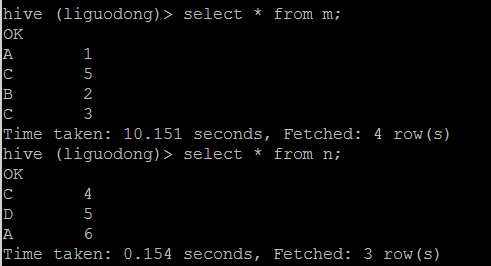
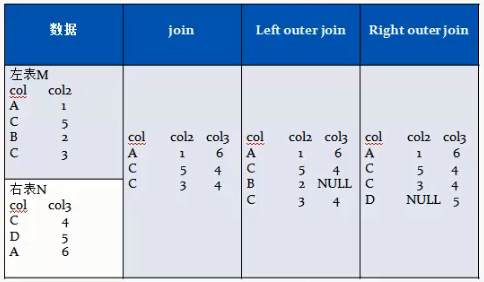
两个表m,n之间按照on条件连接,m中的一条记录和n中的一条记录组成一条新记录。
join等值连接(内连接),只有某个值在m和n中同时存在时。
left outer join左外连接,左边表中的值无论是否在b中存在时,都输出;右边表中的值,只有在左边表中存在时才输出。
right outer join和left outer join相反。
left semi join类似exists。即查找a表中的数据,是否在b表中存在,找出存在的数据。
mapjoin:在map端完成join操作,不需要用reduce,基于内存做join,属于优化操作。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
读取数据执行where条件,按col列分组,把col列的内容作为key,其他列作为value,传到reduce,在reduce端执行连接操作和where过滤。
eg:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
数据输出对比
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
MapJoin
mapjoin(map side join)
在map端把小表加载到内存中,然后读取大表,和内存中的小表完成连接操作。其中使用了分布式缓存技术。
优点
不消耗集群的reduce资源(reduce相对紧缺)。
减少了reduce操作,加快程序执行。
降低网络负载。
缺点
占用部分内存,所以加载到内存中的表不能过大,因为每个计算节点都会加载一次。
生成较多的小文件。
执行流程
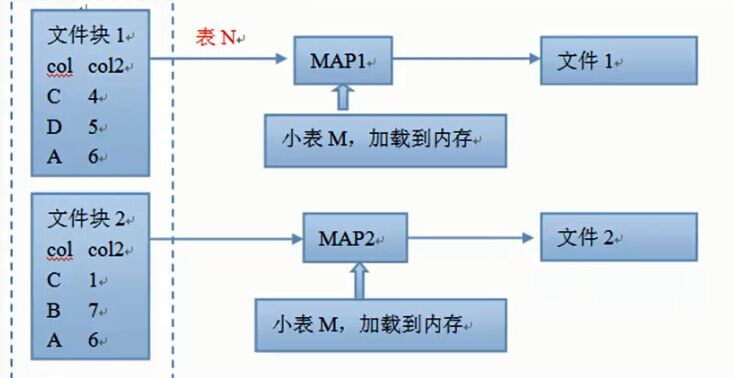
从大表读取数据,执行where条件。把小表加载到内存中,每读取大表中的一条数据,都要和内存中的小表数据进行比较。
第一种方式,自动方式
配置以下参数
hive**自动**根据sql,选择使用common join或者map join
- 1
- 2
- 1
- 2
第二种方式,手动指定
- 1
- 2
- 1
- 2
注意:/*+mapjoin(n)*/不能省略,只需替换表名n值即可。
简单总结一下,map join的使用场景:
1、关联操作中有一张表非常小
2、不等值的链接操作
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
比较二则的比较时间。
Hive分桶JOIN
对于每一个表(table)或者分区,Hive可以进一步组织成桶,也就是说桶是更为细粒度的数据范围划分。
Hive是针对某一列进行分桶。
Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中。
好处
获得更高的查询处理效率。
使取样(sampling)更高效。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
分桶的使用
- 1
- 1
bucket join
- 1
- 2
- 3
- 1
- 2
- 3
连接两个在(包含连接列)相同列上划分了桶的表,可以使用Map端连接(Map side join)高效的实现。比如JOIN操作。
对于JOIN操作两个表有一个相同的列,如果对这两个表都进行了捅操作。那么将保存相同列值的桶进行JOIN操作就可以,可以大大减少JOIN的数据量。
对于map端连接的情况,两个表以相同方式划分桶。处理左边表内某个桶的mapper知道右边表内相匹配的行在对应的桶内。因此,mapper只需要获取那个桶(这只是右边表内存储数据的·小部分)即可进行连接。
这一优化方法并不一定要求两个表必须桶的个数相同,两个表的桶个数是倍数关系也可以。
distribute by、sort by
distribute 分散数据
distribute by col – 按照col列把数据分散到不同的reduce。
Sort排序
sort by col – 按照col列把数据排序
- 1
- 2
- 3
- 1
- 2
- 3
两者结合出现,确保每个reduce的输出都是有序的。
distribute by与group by对比
都是按key值划分数据
都使用reduce操作
**唯一不同的是**distribute by只是单纯的分散数据,而group by把相同key的数据聚集到一起,后续必须是聚合操作。
order by与sort by 对比
order by是全局排序
sort by只是确保每个reduce上面输出的数据有序。如果只有一个reduce时,和order by作用一样。
执行流程
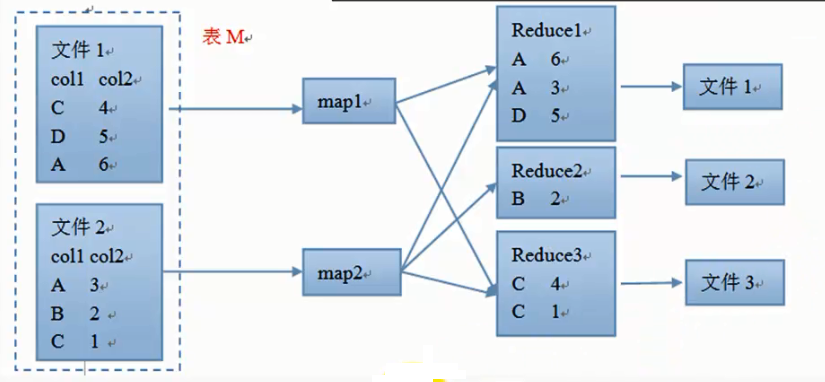
从表中读取数据,执行where条件。
设置reduce数为3,以distribute by列的值作为key,其他列值作为value,然后把数据根据key值传到不同的reduce,然后按sort by字段进行排序。
应用场景
map输出的文件大小不均
reduce输出文件大小不均
小文件过多
文件超大
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
cluster by
把有相同值的数据聚集到一起,并排序。
效果等价于distribute by col sort by col
cluster by col <==> distribute by col sort by col
union all
多个表的数据合并成一个表,hive不支持union
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
执行流程
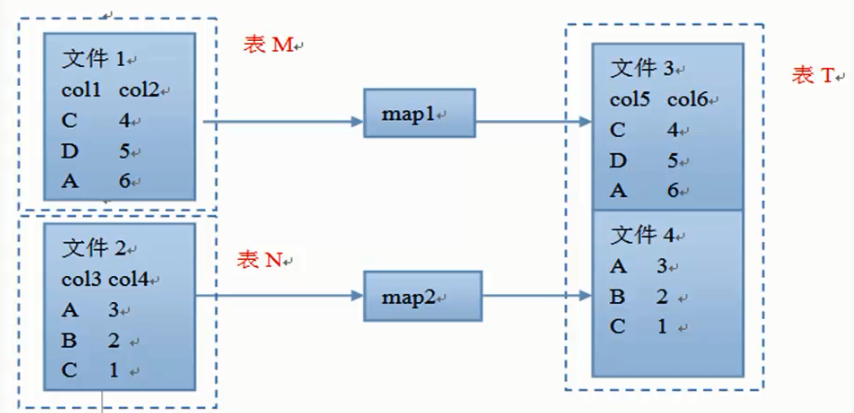
从表中读取数据,执行where条件。合并到同一个表中。
union all必须满足如下要求
字段名字一样
字段类型一样
字段个数一样
子表不能有别名
如果需要从合并之后的表中查询数据,那么合并的表必须要有别名















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









