










Introduction
Working with unstructured text data is hard especially when you are trying to build an intelligent system which interprets and understands free flowing natural language just like humans. You need to be able to process and transform noisy, unstructured textual data into some structured, vectorized formats which can be understood by any machine learning algorithm. Principles from Natural Language Processing, Machine Learning or Deep Learning all of which fall under the broad umbrella of Artificial Intelligence are effective tools of the trade. Based on my previous posts, an important point to remember here is that any machine learning algorithm is based on principles of statistics, math and optimization. Hence they are not intelligent enough to start processing text in their raw, native form. We covered some traditional strategies for extracting meaningful features from text data in Part-3: Traditional Methods for Text Data. I encourage you to check out the same for a brief refresher. In this article, we will be looking at more advanced feature engineering strategies which often leverage deep learning models. More specifically we will be covering the Word2Vec, GloVe and FastTextmodels.
Motivation
We have discussed time and again including in our previous article that Feature Engineering is the secret sauce to creating superior and better performing machine learning models. Always remember that even with the advent of automated feature engineering capabilities, you would still need to understand the core concepts behind applying the techniques. Otherwise they would just be black box models which you wouldn’t know how to tweak and tune for the problem you are trying to solve.
Shortcomings of traditional models
Traditional (count-based) feature engineering strategies for textual data involve models belonging to a family of models popularly known as the Bag of Words model. This includes term frequencies, TF-IDF (term frequency-inverse document frequency), N-grams and so on. While they are effective methods for extracting features from text, due to the inherent nature of the model being just a bag of unstructured words, we lose additional information like the semantics, structure, sequence and context around nearby words in each text document. This forms as enough motivation for us to explore more sophisticated models which can capture this information and give us features which are vector representation of words, popularly known as embeddings.
The need for word embeddings
While this does make some sense, why should we be motivated enough to learn and build these word embeddings? With regard to speech or image recognition systems, all the information is already present in the form of rich dense feature vectors embedded in high-dimensional datasets like audio spectrograms and image pixel intensities. However when it comes to raw text data, especially count based models like Bag of Words, we are dealing with individual words which may have their own identifiers and do not capture the semantic relationship amongst words. This leads to huge sparse word vectors for textual data and thus if we do not have enough data, we may end up getting poor models or even overfitting the data due to the curse of dimensionality.
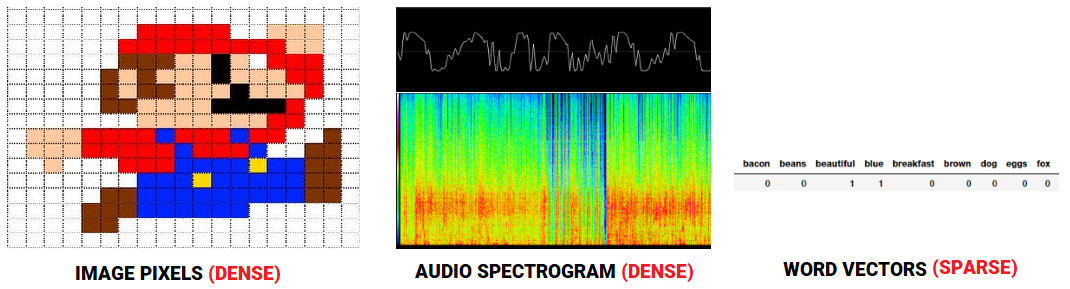
Comparing feature representations for audio, image and text
To overcome the shortcomings of losing out semantics and feature sparsity in bag of words model based features, we need to make use of Vector Space Models (VSMs) in such a way that we can embed word vectors in this continuous vector space based on semantic and contextual similarity. In fact the distributional hypothesis in the field of distributional semantics tells us that words which occur and are used in the same context, are semantically similar to one another and have similar meanings. In simple terms, ‘a word is characterized by the company it keeps’. One of the famous papers talking about these semantic word vectors and various types in detail is ‘Don’t count, predict! A systematic comparison of context-counting vs. context-predicting semantic vectors’ by Baroni et al. We won’t go into extensive depth but in short, there are two main types of methods for contextual word vectors. Count-based methods like Latent Semantic Analysis (LSA) which can be used to compute some statistical measures of how often words occur with their neighboring words in a corpus and then building out dense word vectors for each word from these measures. Predictive methods like Neural Network based language models try to predict words from its neighboring words looking at word sequences in the corpus and in the process it learns distributed representations giving us dense word embeddings. We will be focusing on these predictive methods in this article.
Feature Engineering Strategies
Let’s look at some of these advanced strategies for handling text data and extracting meaningful features from the same, which can be used in downstream machine learning systems. Do note that you can access all the code used in this article in my GitHub repository also for future reference. We’ll start by loading up some basic dependencies and settings.
import pandas as pd import numpy as np import re import nltk import matplotlib.pyplot as plt
pd.options.display.max_colwidth = 200 %matplotlib inline
We will now take a few corpora of documents on which we will perform all our analyses. For one of the corpora, we will reuse our corpus from our previous article, Part-3: Traditional Methods for Text Data. We mention the code as follows for ease of understanding.

Our sample text corpus
Our toy corpus consists of documents belonging to several categories. Another corpus we will use in this article is the The King James Version of the Bibleavailable freely from Project Gutenberg through the corpus module in nltk. We will load this up shortly, in the next section. Before we talk about feature engineering, we need to pre-process and normalize this text.
Text pre-processing
There can be multiple ways of cleaning and pre-processing textual data. The most important techniques which are used heavily in Natural Language Processing (NLP) pipelines have been highlighted in detail in the ‘Text pre-processing’ section in Part 3 of this series. Since the focus of this article is on feature engineering, just like our previous article, we will re-use our simple text pre-processor which focuses on removing special characters, extra whitespaces, digits, stopwords and lower casing the text corpus.
Once we have our basic pre-processing pipeline ready, let’s first apply the same to our toy corpus.
norm_corpus = normalize_corpus(corpus) norm_corpus
Output
------
array(['sky blue beautiful', 'love blue beautiful sky',
'quick brown fox jumps lazy dog',
'kings breakfast sausages ham bacon eggs toast beans',
'love green eggs ham sausages bacon',
'brown fox quick blue dog lazy',
'sky blue sky beautiful today',
'dog lazy brown fox quick'],
dtype='<U51')
Let’s now load up our other corpus based on The King James Version of the Bible using nltk and pre-process the text.
The following output shows the total number of lines in our corpus and how the pre-processing works on the textual content.
Output ------
Total lines: 30103 Sample line: ['1', ':', '6', 'And', 'God', 'said', ',', 'Let', 'there', 'be', 'a', 'firmament', 'in', 'the', 'midst', 'of', 'the', 'waters', ',', 'and', 'let', 'it', 'divide', 'the', 'waters', 'from', 'the', 'waters', '.'] Processed line: god said let firmament midst waters let divide waters waters
Let’s look at some of the popular word embedding models now and engineering features from our corpora!
The Word2Vec Model
This model was created by Google in 2013 and is a predictive deep learning based model to compute and generate high quality, distributed and continuous dense vector representations of words, which capture contextual and semantic similarity. Essentially these are unsupervised models which can take in massive textual corpora, create a vocabulary of possible words and generate dense word embeddings for each word in the vector space representing that vocabulary. Usually you can specify the size of the word embedding vectors and the total number of vectors are essentially the size of the vocabulary. This makes the dimensionality of this dense vector space much lower than the high-dimensional sparse vector space built using traditional Bag of Words models.
There are two different model architectures which can be leveraged by Word2Vec to create these word embedding representations. These include,
- The Continuous Bag of Words (CBOW) Model
- The Skip-gram Model
There were originally introduced by Mikolov et al. and I recommend interested readers to read up on the original papers around these models which include, ‘Distributed Representations of Words and Phrases and their Compositionality’ by Mikolov et al. and ‘Efficient Estimation of Word Representations in Vector Space’ by Mikolov et al. to gain some good in-depth perspective.
The Continuous Bag of Words (CBOW) Model
The CBOW model architecture tries to predict the current target word (the center word) based on the source context words (surrounding words). Considering a simple sentence, “the quick brown fox jumps over the lazy dog”, this can be pairs of (context_window, target_word) where if we consider a context window of size 2, we have examples like ([quick, fox], brown), ([the, brown], quick), ([the, dog], lazy) and so on. Thus the model tries to predict the target_word based on the context_window words.
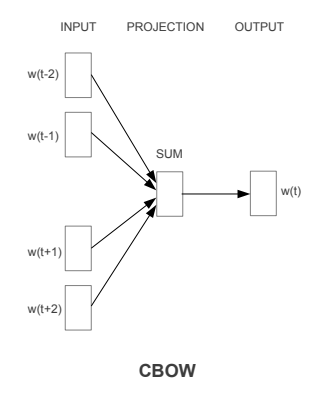
The CBOW model architecture (Source: https://arxiv.org/pdf/1301.3781.pdf Mikolov el al.)
While the Word2Vec family of models are unsupervised, what this means is that you can just give it a corpus without additional labels or information and it can construct dense word embeddings from the corpus. But you will still need to leverage a supervised, classification methodology once you have this corpus to get to these embeddings. But we will do that from within the corpus itself, without any auxiliary information. We can model this CBOW architecture now as a deep learning classification model such that we take in the context words as our input, X and try to predict the target word, Y. In fact building this architecture is simpler than the skip-gram model where we try to predict a whole bunch of context words from a source target word.
Implementing the Continuous Bag of Words (CBOW) Model
While it’s excellent to use robust frameworks which have the Word2Vec model like gensim, let’s try and implement this from scratch to gain some perspective on how things really work behind the scenes. We will leverage our Bible corpus contained in the norm_bible variable for training our model. The implementation will focus on four parts
- Build the corpus vocabulary
- Build a CBOW (context, target) generator
- Build the CBOW model architecture
- Train the Model
- Get Word Embeddings
Without further delay, let’s get started!
Build the corpus vocabulary
To start off, we will first build our corpus vocabulary where we extract out each unique word from our vocabulary and map a unique numeric identifier to it.
Output ------
Vocabulary Size: 12425
Vocabulary Sample: [('perceived', 1460), ('flagon', 7287), ('gardener', 11641), ('named', 973), ('remain', 732), ('sticketh', 10622), ('abstinence', 11848), ('rufus', 8190), ('adversary', 2018), ('jehoiachin', 3189)]
Thus you can see that we have created a vocabulary of unique words in our corpus and also ways to map a word to its unique identifier and vice versa. The PAD term is typically used to pad context words to a fixed length if needed.
Build a CBOW (context, target) generator
We need pairs which consist of a target centre word and surround context words. In our implementation, a target word is of length 1 and surrounding context is of length 2 x window_size where we take window_size words before and after the target word in our corpus. This will become clearer with the following example.
Context (X): ['old','testament','james','bible'] -> Target (Y): king Context (X): ['first','book','called','genesis'] -> Target(Y): moses Context(X):['beginning','god','heaven','earth'] -> Target(Y):created Context (X):['earth','without','void','darkness'] -> Target(Y): form Context (X): ['without','form','darkness','upon'] -> Target(Y): void Context (X): ['form', 'void', 'upon', 'face'] -> Target(Y): darkness Context (X): ['void', 'darkness', 'face', 'deep'] -> Target(Y): upon Context (X): ['spirit', 'god', 'upon', 'face'] -> Target (Y): moved Context (X): ['god', 'moved', 'face', 'waters'] -> Target (Y): upon Context (X): ['god', 'said', 'light', 'light'] -> Target (Y): let Context (X): ['god', 'saw', 'good', 'god'] -> Target (Y): light
The preceding output should give you some more perspective of how X forms our context words and we are trying to predict the target center word Y based on this context. For example, if the original text was ‘in the beginning god created heaven and earth’ which after pre-processing and removal of stopwords became ‘beginning god created heaven earth’ and for us, what we are trying to achieve is that. Given [beginning, god, heaven, earth] as the context, what the target center word is, which is ‘created’ in this case.
Build the CBOW model architecture
We now leverage keras on top of tensorflow to build our deep learning architecture for the CBOW model. For this our inputs will be our context words which are passed to an embedding layer (initialized with random weights). The word embeddings are propagated to a lambda layer where we average out the word embeddings (hence called CBOW because we don’t really consider the order or sequence in the context words when averaged)and then we pass this averaged context embedding to a dense softmax layer which predicts our target word. We match this with the actual target word, compute the loss by leveraging the categorical_crossentropy loss and perform backpropagation with each epoch to update the embedding layer in the process. Following code shows us our model architecture.
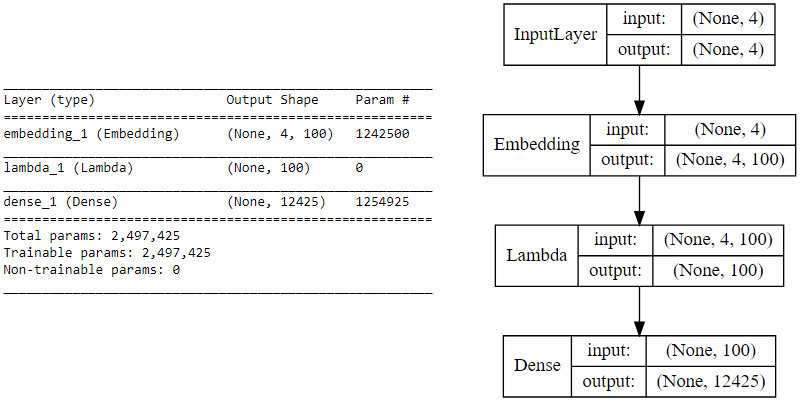
CBOW model summary and architecture
In case you still have difficulty in visualizing the above deep learning model, I would recommend you to read through the papers I mentioned earlier. I will try to summarize the core concepts of this model in simple terms. We have input context words of dimensions (2 x window_size), we will pass them to an embedding layer of size (vocab_size x embed_size) which will give us dense word embeddings for each of these context words (1 x embed_size for each word). Next up we use a lambda layer to average out these embeddings and get an average dense embedding (1 x embed_size) which is sent to the dense softmax layer which outputs the most likely target word. We compare this with the actual target word, compute the loss, backpropagate the errors to adjust the weights (in the embedding layer) and repeat this process for all (context, target) pairs for multiple epochs. The following figure tries to explain the same.
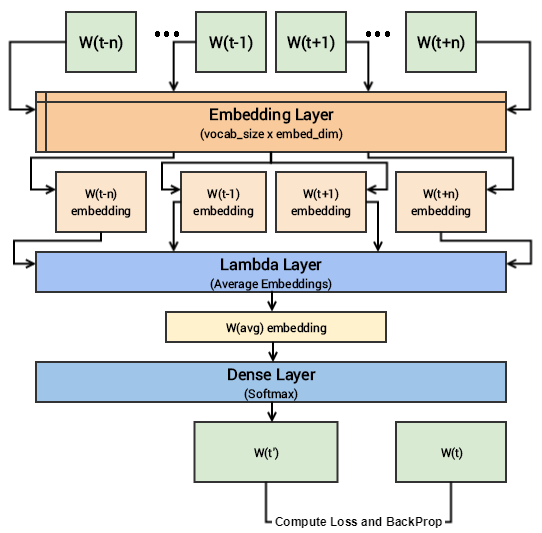
Visual depiction of the CBOW deep learning model
We are now ready to train this model on our corpus using our data generator to feed in (context, target_word) pairs.
Train the Model
Running the model on our complete corpus takes a fair bit of time, so I just ran it for 5 epochs. You can leverage the following code and increase it for more epochs if necessary.
Epoch: 1 Loss: 4257900.60084 Epoch: 2 Loss: 4256209.59646 Epoch: 3 Loss: 4247990.90456 Epoch: 4 Loss: 4225663.18927 Epoch: 5 Loss: 4104501.48929
Note: Running this model is computationally expensive and works better if trained using a GPU. I trained this on an AWS
p2.x instance with a Tesla K80 GPU and it took me close to 1.5 hours for just 5 epochs!
Once this model is trained, similar words should have similar weights based off the embedding layer and we can test out the same.
Get Word Embeddings
To get word embeddings for our entire vocabulary, we can extract out the same from our embedding layer by leveraging the following code. We don’t take the embedding at position 0 since it belongs to the padding (PAD) term which is not really a word of interest.
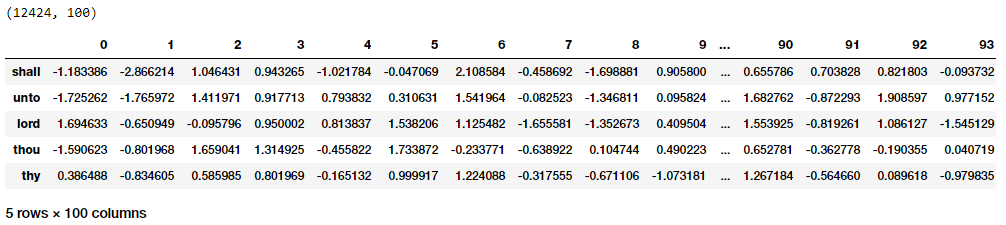
Word Embeddings for our vocabulary based on the CBOW model
Thus you can clearly see that each word has a dense embedding of size (1x100) as depicted in the preceding output. Let’s try and find out some contextually similar words for specific words of interest based on these embeddings. For this, we build out a pairwise distance matrix amongst all the words in our vocabulary based on the dense embedding vectors and then find out the n-nearest neighbors of each word of interest based on the shortest (euclidean) distance.
(12424, 12424)
{'egypt': ['destroy', 'none', 'whole', 'jacob', 'sea'],
'famine': ['wickedness', 'sore', 'countries', 'cease', 'portion'],
'god': ['therefore', 'heard', 'may', 'behold', 'heaven'],
'gospel': ['church', 'fowls', 'churches', 'preached', 'doctrine'],
'jesus': ['law', 'heard', 'world', 'many', 'dead'],
'john': ['dream', 'bones', 'held', 'present', 'alive'],
'moses': ['pharaoh', 'gate', 'jews', 'departed', 'lifted'],
'noah': ['abram', 'plagues', 'hananiah', 'korah', 'sarah']}
You can clearly see that some of these make sense contextually (god, heaven), (gospel, church) and so on and some may not. Training for more epochs usually ends up giving better results. We will now explore the skip-gram architecture which often gives better results as compared to CBOW.
The Skip-gram Model
The Skip-gram model architecture usually tries to achieve the reverse of what the CBOW model does. It tries to predict the source context words (surrounding words) given a target word (the center word). Considering our simple sentence from earlier, “the quick brown fox jumps over the lazy dog”. If we used the CBOW model, we get pairs of (context_window, target_word)where if we consider a context window of size 2, we have examples like ([quick, fox], brown), ([the, brown], quick), ([the, dog], lazy) and so on. Now considering that the skip-gram model’s aim is to predict the context from the target word, the model typically inverts the contexts and targets, and tries to predict each context word from its target word. Hence the task becomes to predict the context [quick, fox] given target word ‘brown’ or [the, brown] given target word ‘quick’ and so on. Thus the model tries to predict the context_window words based on the target_word.
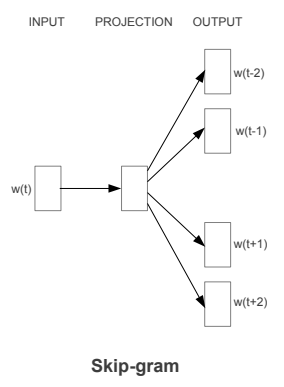
The Skip-gram model architecture (Source: https://arxiv.org/pdf/1301.3781.pdf Mikolov el al.)
Just like we discussed in the CBOW model, we need to model this Skip-gram architecture now as a deep learning classification model such that we take in the target word as our input and try to predict the context words.This becomes slightly complex since we have multiple words in our context. We simplify this further by breaking down each (target, context_words) pair into (target, context) pairs such that each context consists of only one word. Hence our dataset from earlier gets transformed into pairs like (brown, quick), (brown, fox), (quick, the), (quick, brown) and so on. But how to supervise or train the model to know what is contextual and what is not?
For this, we feed our skip-gram model pairs of (X, Y) where X is our input and Y is our label. We do this by using [(target, context), 1] pairs as positive input samples where target is our word of interest and context is a context word occurring near the target word and the positive label 1 indicates this is a contextually relevant pair. We also feed in [(target, random), 0] pairs as negative input samples where target is again our word of interest but random is just a randomly selected word from our vocabulary which has no context or association with our target word. Hence the negative label 0indicates this is a contextually irrelevant pair. We do this so that the model can then learn which pairs of words are contextually relevant and which are not and generate similar embeddings for semantically similar words.
Implementing the Skip-gram Model
Let’s now try and implement this model from scratch to gain some perspective on how things work behind the scenes and also so that we can compare it with our implementation of the CBOW model. We will leverage our Bible corpus as usual which is contained in the norm_bible variable for training our model. The implementation will focus on five parts
- Build the corpus vocabulary
- Build a skip-gram [(target, context), relevancy] generator
- Build the skip-gram model architecture
- Train the Model
- Get Word Embeddings
Let’s get cracking and build our skip-gram Word2Vec model!
Build the corpus vocabulary
To start off, we will follow the standard process of building our corpus vocabulary where we extract out each unique word from our vocabulary and assign a unique identifier, similar to what we did in the CBOW model. We also maintain mappings to transform words to their unique identifiers and vice-versa.
Vocabulary Size: 12425
Vocabulary Sample: [('perceived', 1460), ('flagon', 7287), ('gardener', 11641), ('named', 973), ('remain', 732), ('sticketh', 10622), ('abstinence', 11848), ('rufus', 8190), ('adversary', 2018), ('jehoiachin', 3189)]
Just like we wanted, each unique word from the corpus is a part of our vocabulary now with a unique numeric identifier.
Build a skip-gram [(target, context), relevancy] generator
It’s now time to build out our skip-gram generator which will give us pair of words and their relevance like we discussed earlier. Luckily, keras has a nifty skipgrams utility which can be used and we don’t have to manually implement this generator like we did in CBOW.
Note: The functionskipgrams(…)is present inkeras.preprocessing.sequence
This function transforms a sequence of word indexes (list of integers) into tuples of words of the form:
- (word, word in the same window), with label 1 (positive samples).
- (word, random word from the vocabulary), with label 0 (negative samples).
(james (1154), king (13)) -> 1 (king (13), james (1154)) -> 1 (james (1154), perform (1249)) -> 0 (bible (5766), dismissed (6274)) -> 0 (king (13), alter (5275)) -> 0 (james (1154), bible (5766)) -> 1 (king (13), bible (5766)) -> 1 (bible (5766), king (13)) -> 1 (king (13), compassion (1279)) -> 0 (james (1154), foreskins (4844)) -> 0
Thus you can see we have successfully generated our required skip-grams and based on the sample skip-grams in the preceding output, you can clearly see what is relevant and what is irrelevant based on the label (0 or 1).
Build the skip-gram model architecture
We now leverage keras on top of tensorflow to build our deep learning architecture for the skip-gram model. For this our inputs will be our target word and context or random word pair. Each of which are passed to an embedding layer (initialized with random weights) of it’s own. Once we obtain the word embeddings for the target and the context word, we pass it to a merge layer where we compute the dot product of these two vectors. Then we pass on this dot product value to a dense sigmoid layer which predicts either a 1 or a 0 depending on if the pair of words are contextually relevant or just random words (Y’). We match this with the actual relevance label (Y), compute the loss by leveraging the mean_squared_error loss and perform backpropagation with each epoch to update the embedding layer in the process. Following code shows us our model architecture.
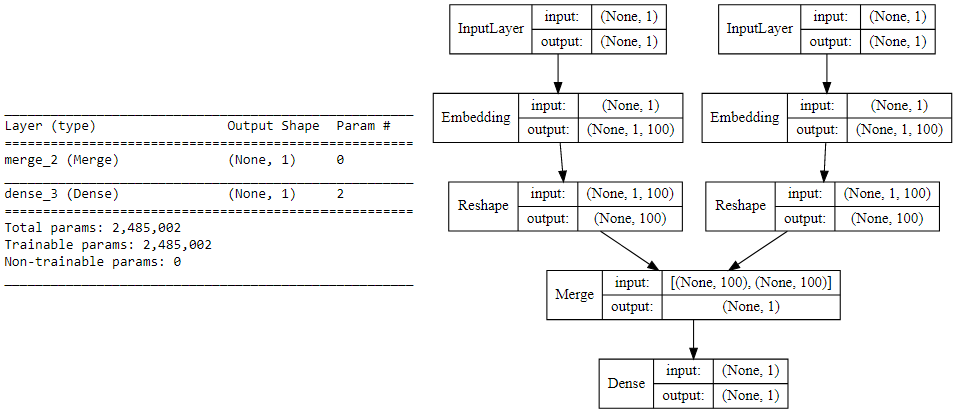
Skip-gram model summary and architecture
Understanding the above deep learning model is pretty straightforward. However, I will try to summarize the core concepts of this model in simple terms for ease of understanding. We have a pair of input words for each training example consisting of one input target word having a unique numeric identifier and one context word having a unique numeric identifier. If it is a positive sample the word has contextual meaning, is a context wordand our label Y=1, else if it is a negative sample, the word has no contextual meaning, is just a random word and our label Y=0. We will pass each of them to an embedding layer of their own, having size (vocab_size x embed_size) which will give us dense word embeddings for each of these two words (1 x embed_size for each word). Next up we use a merge layer to compute the dot product of these two embeddings and get the dot product value. This is then sent to the dense sigmoid layer which outputs either a 1 or 0. We compare this with the actual label Y (1 or 0), compute the loss, backpropagate the errors to adjust the weights (in the embedding layer) and repeat this process for all (target, context) pairs for multiple epochs. The following figure tries to explain the same.
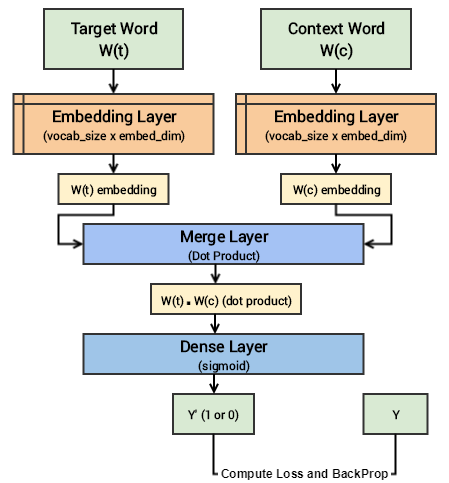
Visual depiction of the Skip-gram deep learning model
Let’s now start training our model with our skip-grams.
Train the Model
Running the model on our complete corpus takes a fair bit of time but lesser than the CBOW model. Hence I just ran it for 5 epochs. You can leverage the following code and increase it for more epochs if necessary.
Epoch: 1 Loss: 4529.63803683 Epoch: 2 Loss: 3750.71884749 Epoch: 3 Loss: 3752.47489296 Epoch: 4 Loss: 3793.9177565 Epoch: 5 Loss: 3716.07605051
Once this model is trained, similar words should have similar weights based off the embedding layer and we can test out the same.
Get Word Embeddings
To get word embeddings for our entire vocabulary, we can extract out the same from our embedding layer by leveraging the following code. Do note that we are only interested in the target word embedding layer, hence we will extract the embeddings from our word_model embedding layer. We don’t take the embedding at position 0 since none of our words in the vocabulary have a numeric identifier of 0 and we ignore it.
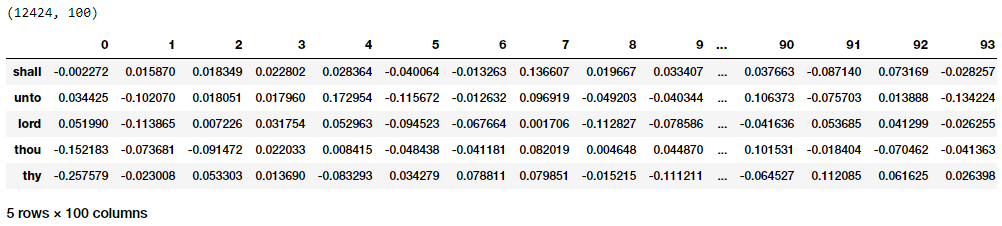
Word Embeddings for our vocabulary based on the Skip-gram model
Thus you can clearly see that each word has a dense embedding of size (1x100) as depicted in the preceding output similar to what we had obtained from the CBOW model. Let’s now apply the euclidean distance metric on these dense embedding vectors to generate a pairwise distance metric for each word in our vocabulary. We can then find out the n-nearest neighbors of each word of interest based on the shortest (euclidean) distance similar to what we did on the embeddings from our CBOW model.
(12424, 12424)
{'egypt': ['pharaoh', 'mighty', 'houses', 'kept', 'possess'],
'famine': ['rivers', 'foot', 'pestilence', 'wash', 'sabbaths'],
'god': ['evil', 'iniquity', 'none', 'mighty', 'mercy'],
'gospel': ['grace', 'shame', 'believed', 'verily', 'everlasting'],
'jesus': ['christ', 'faith', 'disciples', 'dead', 'say'],
'john': ['ghost', 'knew', 'peter', 'alone', 'master'],
'moses': ['commanded', 'offerings', 'kept', 'presence', 'lamb'],
'noah': ['flood', 'shem', 'peleg', 'abram', 'chose']}
You can clearly see from the results that a lot of the similar words for each of the words of interest are making sense and we have obtained better results as compared to our CBOW model. Let’s visualize these words embeddings now using t-SNE which stands for t-distributed stochastic neighbor embedding a popular dimensionality reduction technique to visualize higher dimension spaces in lower dimensions (e.g. 2-D).
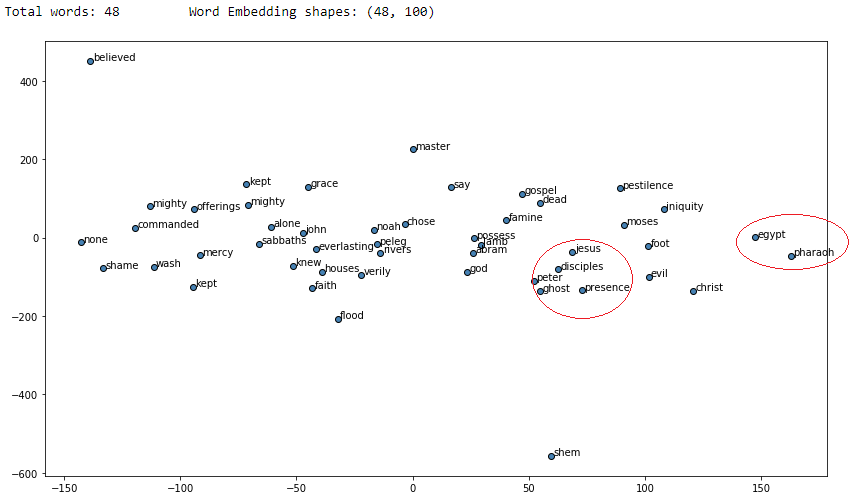
Visualizing skip-gram word2vec word embeddings using t-SNE
I have marked some circles in red which seemed to show different words of contextual similarity positioned near each other in the vector space. If you find any other interesting patterns feel free to let me know!
Robust Word2Vec Models with Gensim
While our implementations are decent enough, they are not optimized enough to work well on large corpora. The gensim framework, created by Radim Řehůřek consists of a robust, efficient and scalable implementation of the Word2Vec model. We will leverage the same on our Bible corpus. In our workflow, we will tokenize our normalized corpus and then focus on the following four parameters in the Word2Vec model to build it.
size: The word embedding dimensionalitywindow: The context window sizemin_count: The minimum word countsample: The downsample setting for frequent words
After building our model, we will use our words of interest to see the top similar words for each of them.

The similar words here definitely are more related to our words of interest and this is expected given that we ran this model for more number of iterations which must have yield better and more contextual embeddings. Do you notice any interesting associations?

Noah’s sons come up as the most contextually similar entities from our model!
Let’s also visualize the words of interest and their similar words using their embedding vectors after reducing their dimensions to a 2-D space with t-SNE.

Visualizing our word2vec word embeddings using t-SNE
The red circles have been drawn by me to point out some interesting associations which I found out. We can clearly see based on what I depicted earlier that noah and his sons are quite close to each other based on the word embeddings from our model!
Applying Word2Vec features for Machine Learning Tasks
If you remember reading the previous article Part-3: Traditional Methods for Text Data you might have seen me using features for some actual machine learning tasks like clustering. Let’s leverage our other top corpus and try to achieve the same. To start with, we will build a simple Word2Vec model on the corpus and visualize the embeddings.
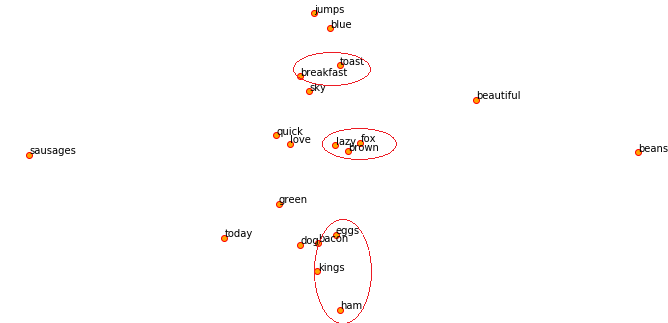
Visualizing word2vec word embeddings on our toy corpus
Remember that our corpus is extremely small so to get meaninful word embeddings and for the model to get more context and semantics, more data helps. Now what is a word embedding in this scenario? It’s typically a dense vector for each word as depicted in the following example for the word sky.
w2v_model.wv['sky']
Output ------
array([ 0.04576328, 0.02328374, -0.04483001, 0.0086611 , 0.05173225, 0.00953358, -0.04087641, -0.00427487, -0.0456274 , 0.02155695], dtype=float32)
Now suppose we wanted to cluster the eight documents from our toy corpus, we would need to get the document level embeddings from each of the words present in each document. One strategy would be to average out the word embeddings for each word in a document. This is an extremely useful strategy and you can adopt the same for your own problems. Let’s apply this now on our corpus to get features for each document.
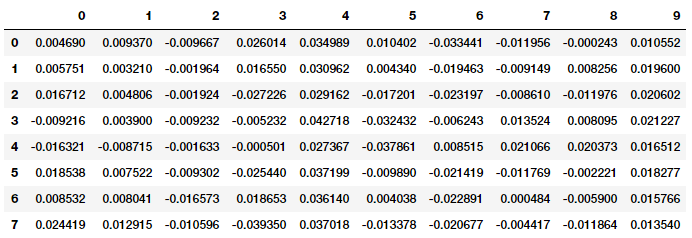
Document level embeddings
Now that we have our features for each document, let’s cluster these documents using the Affinity Propagation algorithm, which is a clustering algorithm based on the concept of “message passing” between data points and does not need the number of clusters as an explicit input which is often required by partition-based clustering algorithms.

Clusters assigned based on our document features from word2vec
We can see that our algorithm has clustered each document into the right group based on our Word2Vec features. Pretty neat! We can also visualize how each document in positioned in each cluster by using Principal Component Analysis (PCA) to reduce the feature dimensions to 2-D and then visualizing the same (by color coding each cluster).
Visualizing our document clusters
Everything looks to be in order as documents in each cluster are closer to each other and far apart from other clusters.
The GloVe Model
The GloVe model stands for Global Vectors which is an unsupervised learning model which can be used to obtain dense word vectors similar to Word2Vec. However the technique is different and training is performed on an aggregated global word-word co-occurrence matrix, giving us a vector space with meaningful sub-structures. This method was invented in Stanford by Pennington et al. and I recommend you to read the original paper on GloVe, ‘GloVe: Global Vectors for Word Representation’ by Pennington et al. which is an excellent read to get some perspective on how this model works.
We won’t cover the implementation of the model from scratch in too much detail here but if you are interested in the actual code, you can check out the official GloVe page. We will keep things simple here and try to understand the basic concepts behind the GloVe model. We have talked about count based matrix factorization methods like LSA and predictive methods like Word2Vec. The paper claims that currently, both families suffer significant drawbacks. Methods like LSA efficiently leverage statistical information but they do relatively poorly on the word analogy task like how we found out semantically similar words. Methods like skip-gram may do better on the analogy task, but they poorly utilize the statistics of the corpus on a global level.
The basic methodology of the GloVe model is to first create a huge word-context co-occurence matrix consisting of (word, context) pairs such that each element in this matrix represents how often a word occurs with the context (which can be a sequence of words). The idea then is to apply matrix factorization to approximate this matrix as depicted in the following figure.
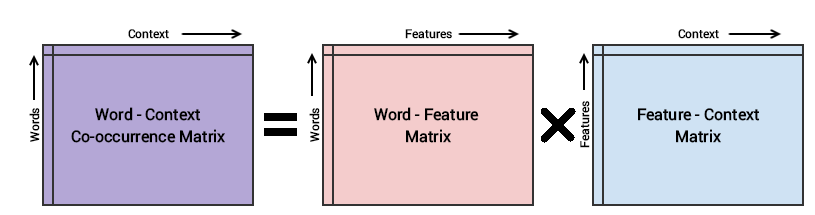
Conceptual model for the GloVe model’s implementation
Considering the Word-Context (WC) matrix, Word-Feature (WF) matrix and Feature-Context (FC) matrix, we try to factorize WC = WF x FC, such that we we aim to reconstruct WC from WF and FC by multiplying them. For this, we typically initialize WF and FC with some random weights and attempt to multiply them to get WC’ (an approximation of WC) and measure how close it is to WC. We do this multiple times using Stochastic Gradient Descent (SGD) to minimize the error. Finally, the Word-Feature matrix (WF) gives us the word embeddings for each word where F can be preset to a specific number of dimensions. A very important point to remember is that both Word2Vec and GloVe models are very similar in how they work. Both of them aim to build a vector space where the position of each word is influenced by its neighboring words based on their context and semantics. Word2Vec starts with local individual examples of word co-occurrence pairs and GloVe starts with global aggregated co-occurrence statistics across all words in the corpus.
Applying GloVe features for Machine Learning Tasks
Let’s try and leverage GloVe based embeddings for our document clustering task. The very popular spacy framework comes with capabilities to leverage GloVe embeddings based on different language models. You can also get pre-trained word vectors and load them up as needed using gensim or spacy. We will first install spacy and use the en_vectors_web_lg model which consists of 300-dimensional word vectors trained on Common Crawl with GloVe.
# Use the following command to install spaCy > pip install -U spacy
OR
> conda install -c conda-forge spacy
# Download the following language model and store it in disk https://github.com/explosion/spacy-models/releases/tag/en_vectors_web_lg-2.0.0
# Link the same to spacy > python -m spacy link ./spacymodels/en_vectors_web_lg-2.0.0/en_vectors_web_lg en_vecs
Linking successful
./spacymodels/en_vectors_web_lg-2.0.0/en_vectors_web_lg --> ./Anaconda3/lib/site-packages/spacy/data/en_vecs
You can now load the model via spacy.load('en_vecs')
There are automated ways to install models in spacy too, you can check their Models & Languages page for more information if needed. I had some issues with the same so I had to manually load them up. We will now load up our language model using spacy.
Total word vectors: 1070971
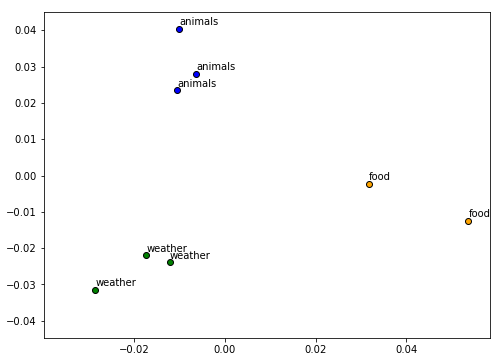
This validates that everything is working and in order. Let’s get the GloVe embeddings for each of our words now in our toy corpus.
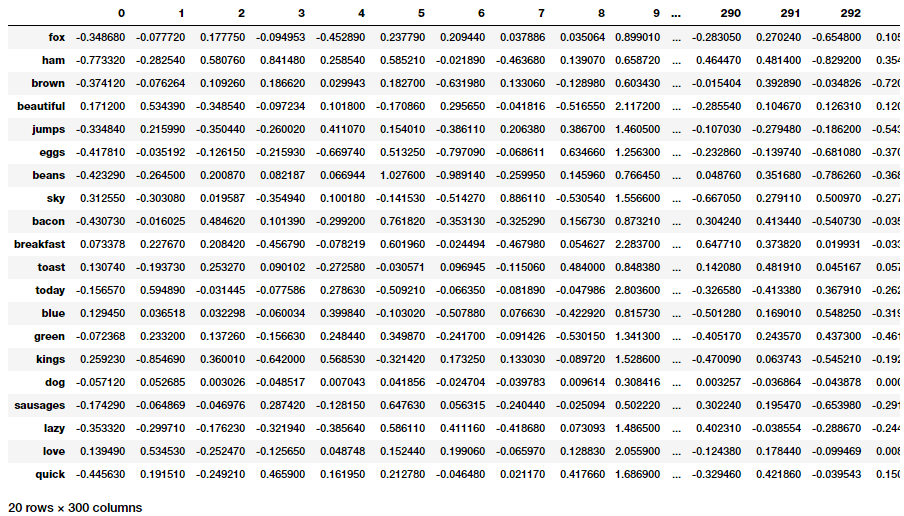
GloVe embeddings for words in our toy corpus
We can now use t-SNE to visualize these embeddings similar to what we did using our Word2Vec embeddings.
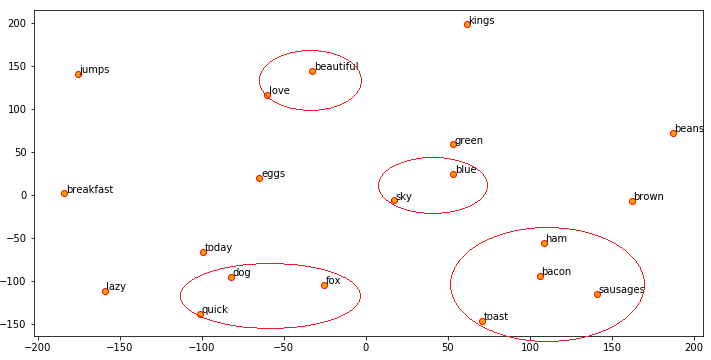
Visualizing GloVe word embeddings on our toy corpus
The beauty of spacy is that it will automatically provide you the averaged embeddings for words in each document without having to implement a function like we did in Word2Vec. We will leverage the same to get document features for our corpus and use k-means clustering to cluster our documents.

Clusters assigned based on our document features from GloVe
We see consistent clusters similar to what we obtained from our Word2Vec model which is good! The GloVe model claims to perform better than the Word2Vec model in many scenarios as illustrated in the following graph from the original paper by Pennington el al.
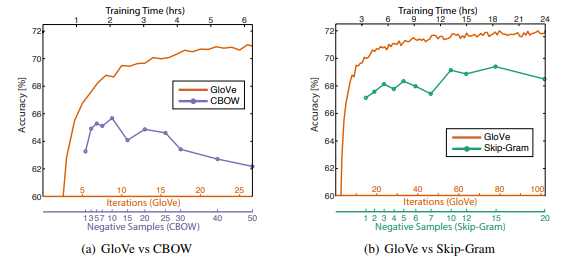
GloVe vs Word2Vec performance (Source: https://nlp.stanford.edu/pubs/glove.pdf by Pennington et al.)
The above experiments were done by training 300-dimensional vectors on the same 6B token corpus (Wikipedia 2014 + Gigaword 5) with the same 400,000 word vocabulary and a symmetric context window of size 10 in case anyone is interested in the details.
The FastText Model
The FastText model was first introduced by Facebook in 2016 as an extension and supposedly improvement of the vanilla Word2Vec model. Based on the original paper titled ‘Enriching Word Vectors with Subword Information’ by Mikolov et al. which is an excellent read to gain an in-depth understanding of how this model works. Overall, FastText is a framework for learning word representations and also performing robust, fast and accurate text classification. The framework is open-sourced by Facebook on GitHub and claims to have the following.
- Recent state-of-the-art English word vectors.
- Word vectors for 157 languages trained on Wikipedia and Crawl.
- Models for language identification and various supervised tasks.
Though I haven’t implemented this model from scratch, based on the research paper, following is what I learnt about how the model works. In general, predictive models like the Word2Vec model typically considers each word as a distinct entity (e.g. where) and generates a dense embedding for the word. However this poses to be a serious limitation with languages having massive vocabularies and many rare words which may not occur a lot in different corpora. The Word2Vec model typically ignores the morphological structure of each word and considers a word as a single entity. The FastText model considers each word as a Bag of Character n-grams. This is also called as a subword model in the paper.
We add special boundary symbols < and > at the beginning and end of words. This enables us to distinguish prefixes and suffixes from other character sequences. We also include the word w itself in the set of its n-grams, to learn a representation for each word (in addition to its character n-grams). Taking the word where and n=3 (tri-grams) as an example, it will be represented by the character n-grams: <wh, whe, her, ere, re> and the special sequence <where> representing the whole word. Note that the sequence , corresponding to the word <her> is different from the tri-gram her from the word where.
In practice, the paper recommends in extracting all the n-grams for n ≥ 3 and n ≤ 6. This is a very simple approach, and different sets of n-grams could be considered, for example taking all prefixes and suffixes. We typically associate a vector representation (embedding) to each n-gram for a word. Thus, we can represent a word by the sum of the vector representations of its n-grams or the average of the embedding of these n-grams. Thus, due to this effect of leveraging n-grams from individual words based on their characters, there is a higher chance for rare words to get a good representation since their character based n-grams should occur across other words of the corpus.
Applying FastText features for Machine Learning Tasks
The gensim package has nice wrappers providing us interfaces to leverage the FastText model available under the gensim.models.fasttext module. Let’s apply this once again on our Bible corpus and look at our words of interest and their most similar words.

You can see a lot of similarity in the results with our Word2Vec model with relevant similar words for each of our words of interest. Do you notice any interesting associations and similarities?
Moses, his brother Aaron and the Tabernacle of Moses
Note: Running this model is computationally expensive and usually takes more time as compared to the skip-gram model since it considers n-grams for each word. This works better if trained using a GPU or a good CPU. I trained this on an AWS
p2.x instance and it took me around 10 minutes as compared to over 2–3 hours on a regular system.
Let’s now use Principal Component Analysis (PCA) to reduce the word embedding dimensions to 2-D and then visualize the same.
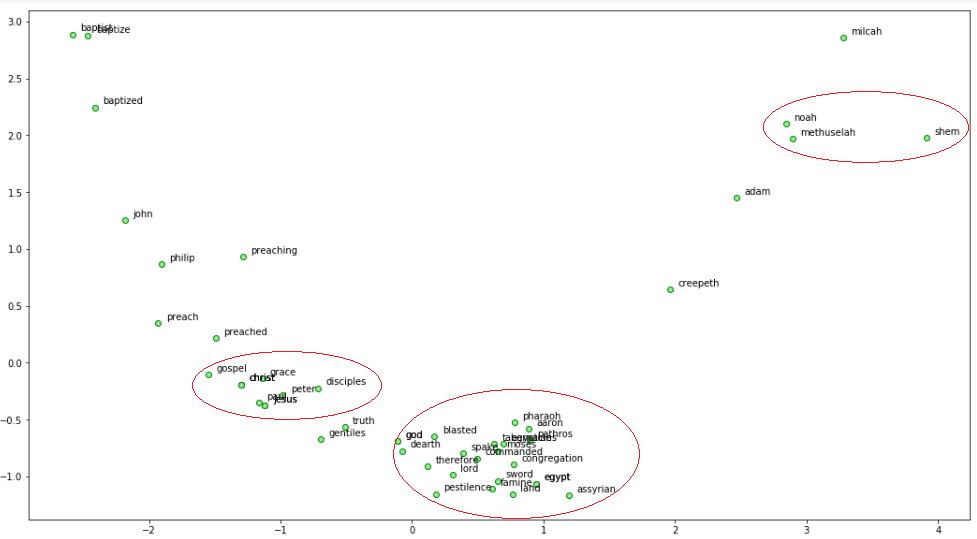
Visualizing FastTest word embeddings on our Bible corpus
We can see a lot of interesting patterns! Noah, his son Shem and grandfather Methuselah are close to each other. We also see God associated with Moses and Egypt where it endured the Biblical plagues including famine and pestilence. Also Jesus and some of his disciples are associated close to each other.
To access any of the word embeddings you can just index the model with the word as follows.
ft_model.wv['jesus']
array([-0.23493268, 0.14237943, 0.35635167, 0.34680951,
0.09342121,..., -0.15021783, -0.08518736, -0.28278247,
-0.19060139], dtype=float32)
Having these embeddings, we can perform some interesting natural language tasks. One of these would be to find out similarity between different words (entities).
print(ft_model.wv.similarity(w1='god', w2='satan')) print(ft_model.wv.similarity(w1='god', w2='jesus'))
Output ------ 0.333260876685 0.698824900473
We can see that ‘god’ is more closely associated with ‘jesus’ rather than ‘satan’ based on the text in our Bible corpus. Quite relevant!
Considering word embeddings being present, we can even find out odd words from a bunch of words as follows.
st1 = "god jesus satan john"
print('Odd one out for [',st1, ']:',
ft_model.wv.doesnt_match(st1.split()))
st2 = "john peter james judas"
print('Odd one out for [',st2, ']:',
ft_model.wv.doesnt_match(st2.split()))
Output ------ Odd one out for [ god jesus satan john ]: satan Odd one out for [ john peter james judas ]: judas
Interesting and relevant results in both cases for the odd entity amongst the other words!
Conclusion
These examples should give you a good idea about newer and efficient strategies around leveraging deep learning language models to extract features from text data and also address problems like word semantics, context and data sparsity. Next up will be detailed strategies on leveraging deep learning models for feature engineering on image data. Stay tuned!
To read about feature engineering strategies for continuous numeric data, check out Part 1 of this series!
To read about feature engineering strategies for discrete categoricial data, check out Part 2 of this series!
To read about traditional feature engineering strategies for unstructured text data, check out Part 3 of this series!
All the code and datasets used in this article can be accessed from my GitHub
The code is also available as a Jupyter notebook















 780
780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









