







无监督点云模型


如图流程:一开始随机生成每个形状的特征 g 1 , g 2...... 到 g i g1,g2......到gi g1,g2......到gi,在右边聚类分成C类,为每个聚类生成聚类特征向量 g ‾ k \overline{g}_k gk,~~将带有聚类信息后的特征向量和原始每个形状融合再加入特征提取网络提取出每个形状的新的 g 1 , g 2...... 到 g i g1~~ ,g2......到gi g1 ,g2......到gi特征,再进行聚类,反复迭代?作者这里讲的晦涩难懂,也没有代码,很是难受
符号说明
S
j
Sj
Sj表示S集合中第J个形状。
P
i
,
j
Pi,j
Pi,j表示第J个形状中的点。
d
i
,
j
di,j
di,j(显著性值)表示第J个形状中的点
P
i
,
j
Pi,j
Pi,j是否是区分它所在形状与S中其他几何形状的关键点。
d
i
,
j
di,j
di,j=1表示关键性很高,说明这个点表示的相关区域仅仅存在于所在的形状,而
d
i
,
j
di,j
di,j=0则表示这个区域在所有形状中含有,没有什么区分度。
f
i
,
j
fi,j
fi,j是J个形状中的第i个点的特征向量
Feature Embedding版块
提取每个点的特征信息 F j Fj Fj
初步提取每个点的特征
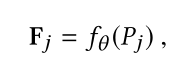
他在这里选择了PointCnn作为
f
f
f函数来初步提取原始点云特征。
特征再提取(特征细化)
因为需要提取每个形状中区分这些形状最显著的那些点,所以对每个点不仅仅需要局部的上下文信息,而且需要形状的上下文信息(应该还是指这个形状整体吧 不是所有形状 毕竟输入应该是单个形状的输入 )。对此作者再采用了 channel-spatial attention机制来进一步提取特征channel-spatial attention机制由CBAM论文最初提出。 有点没明白
CBAM
CBAM是由spatial attention(STN)和channel attention结合的注意力机制模块。
(spatial attention关注的是空间中哪一个点,或者区域比较重要。可以说是位置信息;channel attention关注的是空间中某一个通道,哪一个特征占比更大。关注的是特征信息。)
论文:Sanghyun Woo, Jongchan Park, Joon-Young Lee, and In So Kweon. 2018. CBAM:
Convolutional block attention module. In European Conference on Computer Vision
(ECCV). 3–19.
提取形状特征 g i gi gi
将提取到的每个点的特征向量加起来再求平均值得到形状特征,表示为1*M的
g
i
gi
gi问题:一堆不同形状的东西怎么就提取出一个形状特征呢
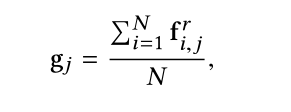
提取每个点的显著性特征
f
i
,
j
fi,j
fi,j是J个形状中的第i个点的特征向量,维度是M维,提取显著性特征就直接取这M维度中的最大值来作为显著性特征
d
i
,
j
di,j
di,j。最后都会归一化到0~1之间,这就是前面符号说明提到的显著性
d
i
,
j
di,j
di,j。

每个形状的点云经过Feature embedding后,得到了 g 1 , g 2...... 到 g i g1,g2......到gi g1,g2......到gi的形状特征向量,用于下游聚类任务。
Joint loss版块
基于聚类的非参数Softmax
Softmax多分类
Softmax将Logistic推广到了两种分类以上
代价函数
J
=
−
y
i
∗
l
o
g
(
y
′
)
J=-yi*log(y')
J=−yi∗log(y′)
其中
y
i
yi
yi是原始数据标签,
y
′
y'
y′是Softmax分类器输出的概率,要损失函数最小就需要输出的概率越大。
这里的公式:输入
g
i
gi
gi时
y
j
=
q
yj=q
yj=q的概率,
w
k
wk
wk充当第K个聚类的类原型,如何计算
w
k
wk
wk?可以用包含类的所有特征向量的平均值来近似聚类原型。
w
k
∗
g
j
wk*gj
wk∗gj表示输入的
g
j
gj
gj和第K类的相似程度,内积表示相似程度要在已经归一化的前提下。
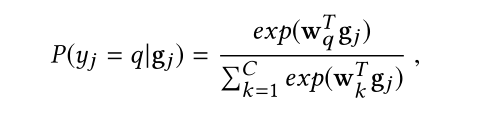
因此上述公式中
w
k
wk
wk用包含类的所有特征向量的平均值来替换后,可以写成如下形式。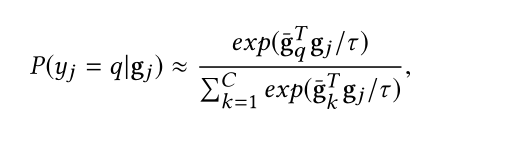
为什么这里又多了一个符号
τ
τ
τ呢,这又是一个叫知识蒸馏的小技巧。
知识蒸馏
用强的老师模型教一个学生模型,达到模型压缩的目的。但是要保证新的学生模型有好的泛化性质,因此我们得对传统的Softmax分类器做一下升级。
传统的Softmax来做分类时,本身负样本(就是不是正确的识别内容的样本)输出就是非常小的概率,接近于0,这样负样本携带的信息,应该还没有转化为概率值时是为负数输出吧 这个就难以学习到。加了这个符号
τ
τ
τ(可以叫他温度)后,正样本携带的信息就相对变小,同理负样本携带的信息就被相对放大了。学习到的信息不仅有正样本,还有负样本的。
经过这样,每个相似的形状都聚类成了一团去了。
对比损失:增加聚类的准确性
用了一个三元组 {gi,gi+ ,gi-}作为输入,计算对比损失。
gi+和gi描述的是同一个类的不同采样,gi-是从和gi不同类集中的随机采用。对比损失函数就是要减少相似的类间欧氏距离,增大差距大的类间的欧氏距离。
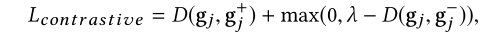















 3292
3292











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









