







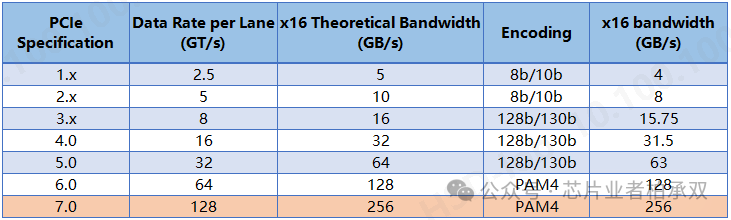
每每谈到PCIe速率的时候,必不可少要谈论的就是PCIe的带宽问题。互联网上也有很多帖子在谈这个事情,但总觉得差那么点意思。我从几个维度来讨论我的理解,希望有些信息能带给大家不一样的看法。先贴张PCIe速率提升图。
理论带宽、实际带宽、带宽利用率、单向带宽、双向带宽
PCIe理论带宽的计算是:链路速率 x Lane number, 如果计算双向带宽的话还要再乘以2(PCIe是双工通信),比如PCIe 3.0 x16的理论带宽为:8Gbps x 16 = 16GB/s 。那这里有个要讨论的问题就是什么时候带宽乘2,什么时候不乘2呢?我们介绍完实际带宽之后再来讨论这个问题。
在讨论实际带宽的时候其实更多的时候也是一个工程问题,这个时候我们更多从带宽本身的概念出发去衡量:带宽定义为单位时间传输的数据量。工程上做带宽评估就是记录发起数据请求的时间,再记录一下响应返回的时间,然后用:请求的数据量/时间来计算实际带宽。
带宽利用率 = 实际带宽 / 理论带宽。这里边理论带宽一般是定值,所以实际带宽越高意味着带宽利用率越高,也就意味着传输性能越高。项目上做带宽优化就是分析系统中影响性能的因素,然后调节这些因素来提高带宽利用率。
现在我们来回答上面的是否乘2问题。工程上在分析带宽的时候通常会拆分成两个部分:读带宽和写带宽。而这两种场景在单独分析时,通常上只在Tx或Rx一个方向上有数据(不知道Tx和Rx是啥的请留言),这个时候就只计算单向带宽。做带宽利用率计算的时候,也只用实际带宽/单向理论带宽来计算。但实际上有一些数据请求者是可以同时发出读请求和写请求的,比如现在对数据传输效率有要求的DMA都能支持这个功能,这个时候对DMA而言,我们依然用读实际带宽和写实际带宽来评估;而如果你要问PCIe的带宽利用率,这个时候就用双向理论带宽来计算。所以请大家不要过多纠结这个问题,讲清楚这个东西背后的逻辑是想告诉大家,在实际工程上要去怎么思考问题,毕竟这个才是重点。
协议开销分析
在此之前我们需要先理解开销这个概念,英文叫Overhead。定义总线的目的本身是为了传输数据,而总线为了高效安全的传输数据,就需要定义一些额外的命令控制字段与响应字段。也就意味着总线在传输数据的时候引入了本身不是数据的信息。宏观上来讲,这些不属于数据的信息都叫开销。所以互联网上目前所见到的讨论PCIe带宽的文章都是用(数据量 / 数据量 + 开销)这个公式来分析带宽的。因为数据量是比较好定的,PCIe的Length字段就能指明数据量,所以这个事情其实应该叫做开销分析,而不应该叫带宽分析。开销分析是为了让你更懂协议,而带宽分析我们上面讲过了,要从定义出发。
我们从协议给出的一张图来逐步分析PCIe的开销来源。
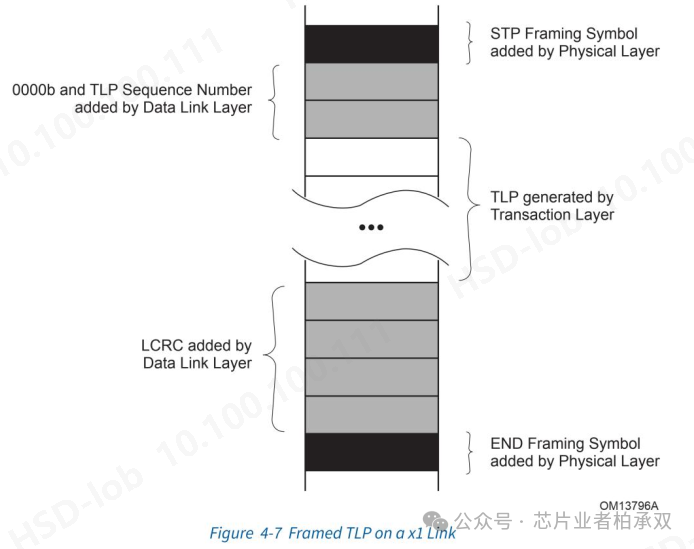
协议开销或者叫TLP开销
Figuer 4-7中间部分有个叫TLP generated by Transaction Layer的部分,这部分其实一个完整的TLP。TLP的构成如下图。

我们上面讲到除了数据部分,其它部分都算开销。所以从协议层引入的开销包括TLP Prefixes、TLP header以及TLP Digest。
TLP Prefixes的个数是根据具体的设计定的,为了对PCIe在功能上做扩展,PCIe ATS功能就是一个例子,需要借助TLP Prefixes传输更多信息。
TLP Header分3DW和4DW两种类型。其中有个非常重要的字段叫length字段,它定义了Data Payload部分的字节数,PCIe一个请求的最大数据量为4096 bytes。从(数据量 / 数据量 + 开销)这个公式来看,数据量越大带宽利用率越高。但实际上PCIe定义了MPS(Max_Payload_Size)和RCB(Read_Completion_Boundary)两个因子来限制PCIe一个请求中能携带的最大数据传输量。这是基于系统带宽平衡上的考虑。在做系统性能优化的时候,这两个信息是可以调整的。
TLP Digest是个4bytes的ECRC可选字段。
以上分析的都是带Data Payload字段的开销,实际在数据传输过程中,还有额外的一些不带Data Payload的TLP会占据链路,而这些是不容易能分析到的。所以我们再回顾一下实际带宽分析的做法:要从带宽的概念出发。
链路层开销
回过头再看Figuer 4-7,TLP下发到链路层会加上TLP Sequence Number和LCRC。除了加入的这两个字段的开销之外,链路层还有Ack/Nak机制和流控机制会带来额外开销,他们分别用来管理TLP传输的健壮性和高效性。
物理层编码开销
再回头来理解下最开始那种表,这张表的最后一列是计算了物理层编码开销之后带宽,它既不是理论带宽也不是实际带宽。我们只需要掌握这样一个概念就行了,它的实际意义不大,也就是说工程上一般不用这个信息来做任何事:在Gen1和Gen2上物理层8B/10B编码开销是1/5,这时候编码开销算是个比较大的影响。在Gen3/4/5上物理层采用了128b/130b的编码策略,其实这时候编码开销带来的带宽影响已经不是那么严重了。在Gen6和Gen7上物理层使用了PAM4编码,这时候其实已经没有编码开销了。
物理层Symbol开销
再回头看Figuer 4-7,TLP在物理层的时候要加上STP Frame Symbol和End Frame Symbol。加这两个Symbol的目的是在RX侧解析的时候能找到TLP的开头和结尾。这两个Symbol会带来一定的开销。
DLLP在物理层上也会加入SDP Symbol和End Symbol,这也会引入很小的开销。
物理层为了做链路两侧设备的CDC问题(很多文章介绍的时钟补偿技术,用于弥补发送侧和接受侧时钟抖动引入的数据传输问题,其实就是CDC问题,CDC即跨时钟域处理)引入的SKP Order Set的传输也会占据链路,所以也会引入开销。
注意物理层对Symbol在Gen3以上速率时有所变化。传输DLLP时会带两个SDP Symbol,传输TLP时会带4个STP Symbol。End Frame Symbol也会变成4个。
再啰嗦一下,我们讨论开销分析的好处是能对PCIe的整个处理流程更熟悉。但要注意的是,落到产品上,在做PCie实际带宽分析的时候还有更多影响因子要考虑。
PCIe实际带宽分析
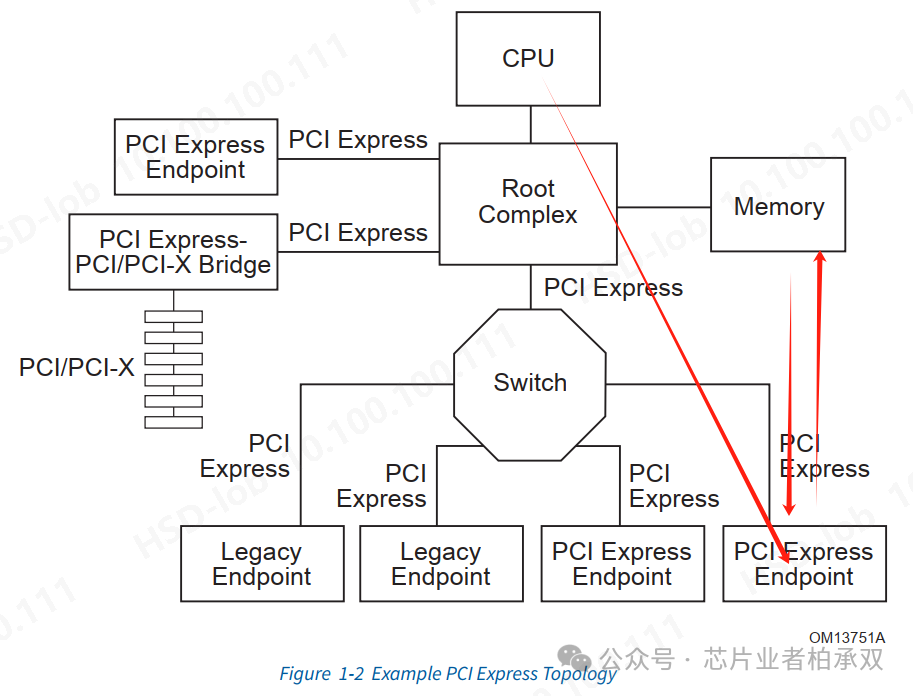
我们用协议中的一个PCIe拓扑结构图的例子作为简化模型来讨论怎么进行PCIe带宽分析。
首先要交代几个背景:
-
在市场上,CPU、Root Complex、Memory这三个东西一般是一个开发商实现的。Switch可能是另一个开发商的产品。PCI Express Endpoint又是另一个开发商。
-
实际系统中可能没有Switch。
-
我们讨论最右侧双向红色箭头的Memory到EP的数据搬运过程。我们假设EP实现的有设备侧存储。Memory一般就是主存。
-
我们把带宽分析的内容也要简化到只有主存和设备存储之间的数据搬运这一条通路,因为整个系统的性能分析还受各个开发商的实现方案影响。比如主机和设备侧如果都实现了多Master访问存储的情况,如果其他Master也在工作,就势必会抢占带宽。而系统性能的分析就是根据多Master之间的仲裁策略给各Master提供够用的QoS。
主存到设备存储的数据搬运一般有两种方式:1)CPU的Load/Store指令方式(RISC处理器系统的访存指令);2)设备侧会实现一个DMA用来做主存到设备存储的数据搬运。当前的主流都是用DMA做数据搬运。
我们在做带宽分析的思想就是定义一批数据量(一般从MRS定义的数据量开始,大到可能有2MB、4MB,甚至更多的数据量),然后统计从数据搬运到指令开始到所有这些数据搬完所花费的时间,然后用数据量/时间计算出带宽。
用DMA做数据搬运影响PCIe性能的最大因素有两个:一个是MPS和RCB值;一个是DMA工作机制。
-
MPS影响写带宽,RCB影响读带宽。在枚举过程中系统会把所有PCIe设备的这两个值设置为所有设备中最小的值。但是依然可以调节来做试验。
-
DMA最开始的问题在于它对数据的搬运过程是受控于CPU的,就是说它的工作流程一般是这样的:
-
CPU配置DMA的寄存器(起始地址、目的地址、搬运的数据量)。
-
CPU启动数据搬运(配置DMA的Start寄存器)。
-
DMA搬运完数据报中断。
-
CPU处理DMA中断,清除DMA中断。
-
CPU开始下一轮数据搬运,重复上述过程。
-
这样DMA在每两笔数据搬运之间总要插入一段CPU指令以及中断处理过程。而DMA技术的演化过程也就一直在致力于消除这个过程。LinkList技术、Shadow Register技术、Doolbell技术等都在这个方向上做努力。
-
其它影响因子
-
PCIe Ack/Nak机制可以支持多个TLP返回一个Ack,减少了Ack DLLP包的个数。
-
PCie的灵活路由技术可以减少排队阻塞。
-
以上还只是能想到的PCie本身的因素。实际上整个数据搬运过程中的各个组件都可能会有影响PCIe性能的设计,比如缓存大小不够就会导致频繁反压,DDR本身性能还未优化到最佳。
做个总结
我们一直提到PCIe是个系统问题,PCIe的带宽分析也是个系统问题。如果对系统方案不熟悉那做PCIe性能分析那是不全面的。对PCIe做带宽分析实际上是各个开发商内控的过程,因为在做产品标的的时候,一般不会给出PCIe实际带宽是多少。而实际做产品性能分析的时候更多的要考虑总体性能,这时候就要分析影响整个系统性能的因子,这就会变的更复杂。















 1637
1637

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









