







 本文介绍了Pooling层在卷积神经网络(ConvNet)中的作用,主要关注Max Pooling,用于减少网络参数和计算,控制过拟合。通过2x2的滤波器和2的步长,每个深度切片的空间大小被缩小,激活值保留最大值。此外,还提到了均值池化和p范数池化等其他池化函数。
本文介绍了Pooling层在卷积神经网络(ConvNet)中的作用,主要关注Max Pooling,用于减少网络参数和计算,控制过拟合。通过2x2的滤波器和2的步长,每个深度切片的空间大小被缩小,激活值保留最大值。此外,还提到了均值池化和p范数池化等其他池化函数。
参考:cs231n
这个系列写的是我对cs231n的一些翻译和理解
————————————————————————————————————————————
Pooling layer
先看cs231n上的描述:
It is common to periodically insert a Pooling layer in-between successive Conv layers in a ConvNet architecture. Its function is to progressively reduce the spatial size of the representation to reduce the amount of parameters and computation in the network, and hence to also control overfitting. The Pooling Layer operates independently on every depth slice of the input and resizes it spatially, using the MAX operation. The most common form is a pooling layer with filters of size 2x2 applied with a stride of 2 downsamples every depth slice in the input by 2 along both width and height, discarding 75% of the activations. Every MAX operation would in this case be taking a max over 4 numbers (little 2x2 region in some depth slice). The depth dimension remains unchanged. More generally, the pooling layer
简单来说就是,在连续的卷积层之间插入汇聚层可以有效地减少参数的数量。拿最简单的汇聚层——max pooling来说,我们将四个相邻的点合并为一个点,新产生的点的像素值是这四个点中像素值最大的点的像素值。如果移动时的步长恰好等于汇聚层的尺寸(在这里stride=2),那么一个卷积后产生的feature map的参数会降为原来的1/4,大大减小了参数的数量。
参考一张图片
来自:http://www.cnblogs.com/hellocwh/p/5564568.html
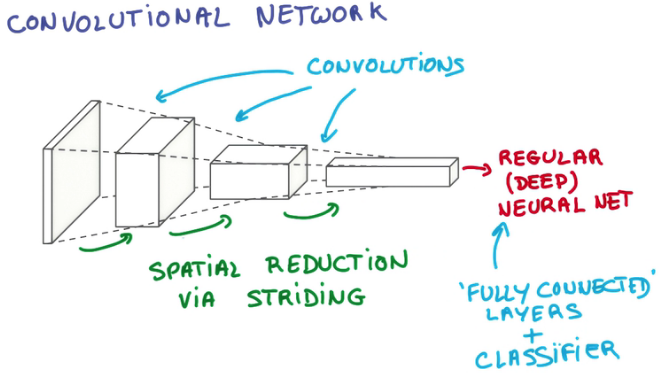
我们可以看到,经过一层层的layer后,数据已经从最初的像一张纸一样又宽又薄的样子,变成了像一支笔一样又窄又厚的样子。(depth是因为卷积核的数量增加所以增大,width和height是因为pooling所以减少)
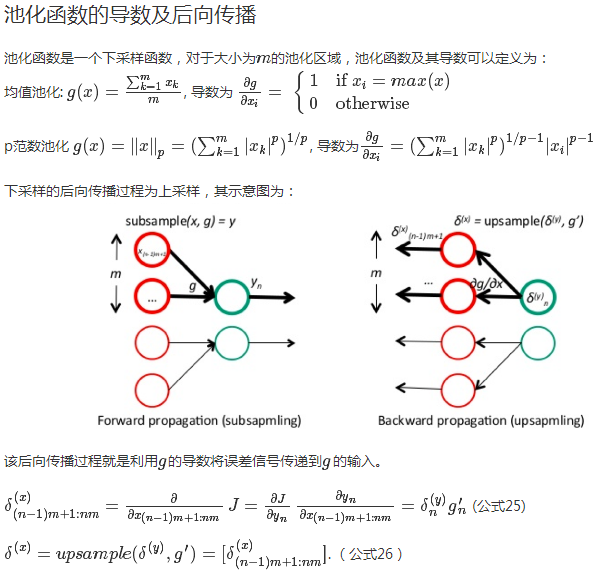
上一张干货图:介绍两种其他的池化函数:均值池化和p范数池化
来自:[http://blog.csdn.net/taigw/article/details/50612963]















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









