







感知器(举例:“与”门)
感知器原理
什么是神经⽹络?⼀开始,我将解释⼀种被称为“感知器”的⼈⼯神经元。感知器在20世 纪五、六⼗年代由科学家Frank Rosenblatt发明,其受到Warren McCulloch和Walter Pitts早 期著作的影响。今天,使⽤其它⼈⼯神经元模型更为普遍——主要使⽤的是⼀种叫做S型神经元的神经元模型。
⼀个感知器接受⼏个⼆进制输⼊,x1,x2,…,并产⽣⼀个⼆进制输 出:
(感知器模型)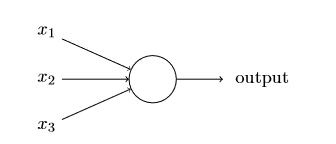
⽰例中的感知器有三个输⼊,x1,x2,x3。通常可以有更多或更少输⼊。Rosenblatt提议⼀个 简单的规则来计算输出。他引⼊权重,w1,w2,…,表⽰相应输⼊对于输出重要性的实数。神经 元的输出,0或者1,则由分配权重后的总和∑j wjxj⼩于或者⼤于⼀些阈值决定。和权重⼀样, 阈值是⼀个实数,⼀个神经元的参数。⽤更精确的代数形式:(将它程之为激活函数)——————这里的j从1开始
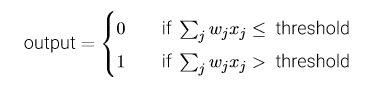
若用偏置b=-threshold代替,那么感知器的规则可重写为:
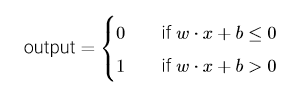
同样的,(这里有点技巧)将偏执b看作:输入信号X0(即X0=b),权重为1的信号,即b=X0*1.那么此时这个感知器的模型可改为:——————这里的j从0开始
y=output
权重更新
更新公式
Wj=Wj+△Wj
△Wj=η*(y-y_hat)Xj
-
η为学习率(更新幅度)
-
y为真实值
-
y_hat为预测值
-
Xj为输入
更新步骤
-
对权重初始化(0或很小的值)
-
对训练集中的每一个样本进行迭代,计算出输出值
-
根据输出值与真实值调整权重
-
循环步骤2,知道达到指定次数或完全收敛
【注】
-
线性可分,感知器一定能收敛(预测出)
比如在二维空间下:
-
线性不可分,感知器永远不可能收敛(预测)
实例说明(“与“门)
代码
import numpy as np
from datetime import datetime
import random
#定义数据集
X=np.array([[1,0,0],[1,0,1],[1,1,0],[1,1,1]])
#定义标签
y=np.array([0,0,0,1])
#定义权重
w=np.zeros(3)
#定义学习率
eta=0.1
for epoch in range(7):
for x,target in zip(X,y):
#计算静输入
z=np.dot(w,x) #dot实现对应相乘
#根据静输入计算分类值
y_hat=1 if z>=0 else 0
#根据预测值与真实值,进行权重调整
w+=eta*(target - y_hat)*x
#这里使用了矢量化计算,相当于计算了以下操作
# w[0]+=eta*(target - y_hat)*x[0]
# w[1]+=eta*(target - y_hat)*x[1]
# w[2]+=eta*(target - y_hat)*x[2]
print (target,y_hat)
print(w)
代码参数说明
实现“与”门:
| 数据集:【x0,x1,x2】 | 标签:y |
|---|---|
| [1,0,0] | 0 |
| [1,0,1] | 0 |
| [1,1,0] | 0 |
| [1,1,1] | 1 |
初始权重:(0,0,0)
学习率:0.1
真实值(标签):y
学习后输出(分类值):y_hat















 1823
1823











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









