







👍【AI机器学习入门与实战】目录
🍭基础篇
🔥 第一篇:【AI机器学习入门与实战】AI 人工智能介绍
🔥 第二篇:【AI机器学习入门与实战】机器学习核心概念理解
🔥 第三篇:【AI机器学习入门与实战】机器学习算法都有哪些分类?
🔥 第四篇:【AI机器学习入门与实战】数据从何而来?
🔥 第五篇:【AI机器学习入门与实战】数据预处理的招式:闪电五连鞭!
🔥 第六篇:【AI机器学习入门与实战】选择合适的算法:选择比努力重要!
🔥 第七篇:【AI机器学习入门与实战】训练模型、优化模型、部署模型
🍭实战篇
🔥 第八篇:【AI机器学习入门与实战】用户RFM模型聚类分层实战
🔥 第九篇:【AI机器学习入门与实战】使用OpenCV识别滑动验证码案例
🔥 第十篇:【AI机器学习入门与实战】CNN卷积神经网络识别图片验证码案例
未完待续…
案例背景:程序自动化的爬虫而无需人工介入是我们的最终目标。自动化爬虫避免不了自动登录的问题,在爬取XX数据的过程中,遇到登录图形验证码的识别的问题,那我们该如何攻破这种验证码呢?
字符验证码图片如下:

在这个案例中,我会通过案例一步一步攻破这种验证码。
现有能力调研

- pytesseract 是一款开源的免费的OCR识别工具,它能识别一些很基础、很简单的验证码,但是面对稍微复杂一点的验证码识别准确率就很低了。
- 超级鹰等云打码平台,能够识别复杂的验证码,识别准确率较好,但是其是收费的,费用标准大约几百每年。在平台上注册后会送一些免费的使用次数,大家感兴趣的可以尝试一下。
靠人不如靠己!不就是个简单的验证码识别吗?弄他!
验证码分析
我们先分析一下,我们这个验证码相较于市面上常见的验证码,有何区别?

这个验证码主要有2个问题影响识别:
- 干扰元素较多
- 字符倾斜,严重的字符展示不全。
如何让机器像人一样准确地识别出图片上的验证码字符呢?下面我们一起用机器学习搞定这个实战案例!开始之前,我们再来回顾一下六步法实战!

1、数据收集
首先,我们要搞定训练数据收集的问题,也就是收集一些验证码图片的数据。数据从何而来呢?在六步法实战中,我们介绍了获取数据的几种常用手段。显然,这个数据集需要我们自己去手动搞定他了!怎么搞?答案就是爬虫!
爬虫分析实现
- XX平台获取验证码的接口是动态的,也就是同样的请求会随机返回一张二维码。接口的URL是:http://xxxxx
- 获取的图片的数据后,我们将数据保存下来。
- 重复1、2步骤…
20行代码实现爬取图片数据
import requests
import time
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/88.0.4324.182 Safari/537.36 Edg/88.0.705.81"}
url = "https://xxxxx"
def get_captcha():
"""
获取验证码并存储
:return:
"""
for i in range(0, 10000):
time.sleep(2)
print("sleeping...")
resp = requests.get(url, headers=headers)
with open(f"../picture/{i}.png", 'wb') as file:
file.write(resp.content)
def main():
get_captcha()
if __name__ == '__main__':
main()
这里我们通过 resp = requests.get(url, headers=headers) 请求验证码图片并返回数据,然后通过 file.write(resp.content) 保存图片数据。
这里爬了很多个小时,终于把数据准备好了!(不敢爬的太快!爬虫爬得快,监狱进的早🌝)爬完之后的数据长这样子。

2、数据预处理
数据准备好之后,重头戏才刚刚开始。
在数据处理之前,我们先明确一个问题,验证码识别应该属于什么类型的机器学习项目?其实这是一个分类的项目,并且属于监督学习。以机器的视角来看,验证码识别,其实就是对验证码图片上的字符进行分类成A、B、C、7、8、9等等,所以这是监督学习中的分类问题,那为什么是监督学习呢?请你思考一下。
在数据的预处理阶段,我们要做哪些工作?再回顾一下数据预处理的经典5步:
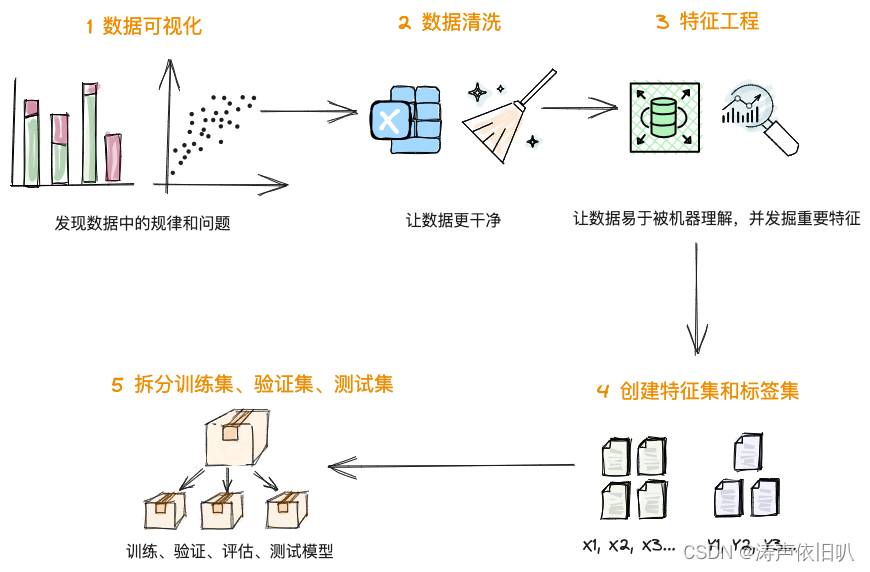
数据可视化阶段在这个案例中可以省略了!
数据清洗对于验证码图片数据而言,叫图片清洗分类更为贴切,其中包括图片的灰度、降噪、裁剪、分类等工作。
2.1、让图片更干净些
我们先看一下效果,如下是经过了验证码背景图清洗前和清洗后的对比:

这里主要使用OpenCV库对图片进行灰度、降噪、二值化,这些都是图片预处理的常用手段。这里我们简单的介绍一下。
OpenCV是一个开源的计算机视觉库。它提供了一系列图像处理和计算机视觉算法,包括图像滤波、目标检测、人脸识别等。
灰度图像
在一张彩色图片中,每个像素点由三个RGB颜色通道(红、绿、蓝)组成,每个通道的颜色值可以是0到255之间的任何值。灰度图像是一种单通道图像,每个像素只有一个灰度值。灰度图像可以看作是将彩色图像的三个颜色通道(红、绿、蓝)合并为一个通道得到的结果,也可以通过将三个通道的值加权平均得到。
在机器学习领域,通常将彩色图像转换为灰度图像进行处理,因为与RGB图像相比,灰度图像具有更简单的结构和更低的计算复杂度。在OpenCV中使用 cv2.cvtColor(img, cv2.COLOR_RGB2GRAY) 方法将RGB三通道图像转换为灰度图像。
降噪
降噪就是用于减少图像中的噪声。图像噪声是由于图像获取和传输过程中的信号干扰、电磁辐射等原因导致的随机扰动。这些噪声会影响图像质量和后续处理结果,因此需要使用降噪技术来减少噪声的影响。在OpenCV中,可以使用`cv2.GaussianBlur()函数实现高斯滤波,从而提高图像的质量和后续处理结果。
二值化
图片二值化是一种重要的图像预处理技术,可以用于去除噪声、提高对比度、简化图像信息、分离目标、降低数据量等目的。在实际应用中,需要根据具体情况选择合适的二值化方法和参数,以达到最佳的效果。在OpenCV中,可以使用 cv2.threshold()函数对图像进行二值化操作。
以下是降噪、灰度和二值化的完整代码,主要流程为:
- OpenCV载入待处理图片:
img = cv2.imread(image_path, 1) - 将RGB三通道图像转为灰度图像
gray_img = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY) - 使用高斯滤波降噪
cv2.GaussianBlur(gray_img, (5, 5), 0) - 二值化图片
cv2.threshold(blur, 134, 255, 0, gray_img) - 返回处理后的图片
完整代码如下:
def cv2_noise_remove(image_path, k):
"""
8邻域降噪
Args:
image_path: 图片文件命名
k: 判断阈值
Returns:
"""
def calculate_noise_count(img_obj, w, h):
"""
计算邻域非白色的个数
Args:
img_obj: img obj
w: width
h: height
Returns:
count (int)
"""
count = 0
width, height = img_obj.shape
for _w_ in [w - 1, w, w + 1]:
for _h_ in [h - 1, h, h + 1]:
if _w_ > width - 1:
continue
if _h_ > height - 1:
continue
if _w_ == w and _h_ == h:
continue
if img_obj[_w_, _h_] < 230: # 二值化的图片设置为255
count += 1
return count
img = cv2.imread(image_path, 1)
# 灰度
gray_img = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
w, h = gray_img.shape
for _w in range(w):
for _h in range(h):
if _w == 0 or _h == 0:
gray_img[_w, _h] = 255
continue
# 计算邻域pixel值小于255的个数
pixel = gray_img[_w, _h]
if pixel == 255:
continue
if calculate_noise_count(gray_img, _w, _h) < k:
gray_img[_w, _h] = 255
# gray_img = cv2.adaptiveThreshold(gray_img, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 11, 2)
# 先使用一个 5x5 的高斯核除去噪音,然后再使用 Otsu 二值化
blur = cv2.GaussianBlur(gray_img, (5, 5), 0)
# ret3, th3 = cv2.threshold(blur, 1, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
# ret3, th3 = cv2.threshold(blur, 144, 255, 0, gray_img)
ret3, th3 = cv2.threshold(blur, 134, 255, 0, gray_img) # 更优秀
# # 二值化处理
# ret3, th3 = cv2.threshold(th3, 134, 255, 0, th3) # 二值化函数
return th3
2.2、裁剪图片
图片清理干净后,我们需要对图片进行裁剪。裁剪的目的是将图片按照字符进行切分,以便于后续的训练及识别。

切割的方法比较简单,这里我们将验证码图片等比例切分为4份。并保存切割后的图片。主要逻辑为:
- 等比例裁剪图片
image.copy()[box[1]:box[3], box[0]:box[2]] # 裁剪坐标为[y0:y1, x0:x1] - 使用OpenCV保存图片
cv2.imwrite(temp_path, temp_image)
def cv2_split_image_and_save(img_path):
"""
根据图片路径cv2处理图片并拆分
:param img_path: 图片download路径
:return: 拆分后图片路径
"""
# '/Users/rongtao7/IdeaProjects/yaoCaptchaDiscern/temp/97090039-4859-4bb6-a47e-003654b36881.png'
image = cv2_noise_remove(img_path, 4)
save_path = []
for i in range(ConfigUtil.IMG_CHAR_COUNT):
box = cv2_img_crop_box(i)
temp_image = image.copy()[box[1]:box[3], box[0]:box[2]] # 裁剪坐标为[y0:y1, x0:x1]
file_name = f"{img_path.split('/temp/')[1].split('.')[0]}{ConfigUtil.TEMP_IMG_NAME_SEPARATOR}{i}.png"
# print(file_name)
temp_path = f"{sys.path[0]}/temp/{file_name}.png"
cv2.imwrite(temp_path, temp_image)
save_path.append(temp_path)
return save_path
2.3、图片分类
裁剪好的图片,我们需要将图片分类,相当于给图片打标签,告诉机器这张图片应该属于什么分类,也就是它是什么。那我们一共有哪些分类呢?
由数字和英文字母组成,一共32个分类类别,其中排除掉了 1和I 0和O的易错选项,因为他们容易混淆,人眼都容易弄错,用户的体验也不好。

那我们现在要做的工作就是将所有切割后的图片分类到这32个文件夹中!好家伙!这可是一个庞大的工程啊,看一下我是怎么做的?
。。。。。。省略人工标注过程
前期我做了大量的人工标注工作,简直怀疑人生🤣
那有没有什么工具能帮帮我呢!这让我又想起了 pytesseract 这个开源的OCR识别库,前面我们提到过,针对整个验证码图片它的识别率是极低的,因为它只能处理简单的字符图片识别工作!但是我们的图片经过预处理和切割后,相对也好识别一些了,所以我就想到了让 pytesseract 帮我识别一部分,它识别不了的或者识别错误的,我们再手动标注一部分数据,这样我们图片手动标注的工作也是提效了约 50%

那有的同学就想到了!是不是图片切割好以后,用 pytesseract 识别字符,就可以完成验证码识别工作了?
当然可以!这个我也尝试过了,只不过识别的准确率较低,每个字符图片的准确率大概在 40%左右,但是4张图片结果加到一起后准确率相对就比较低了,一个免费开源的库你还要啥自行车🚴🏻啊!
使用 pytesseract辅助分类的代码如下,主要有2个步骤:(1)通过 ocr方法识别图片(2)通过 collect将图片移动到指定文件夹下
import os
import cv2
from PIL import Image, ImageFilter
import shutil
import pytesseract
"""
OCR图片分类
"""
split_list = os.listdir("./splits")
list_new = os.listdir("./captchas_new")
def ocr(img_path):
"""
pytesseract ocr识别
:param img_path: 图片路径
:return: 识别结果
"""
image = cv2.imread(img_path, 1)
if image is None:
return ""
test_message = Image.fromarray(image)
if test_message is None:
return ""
target = pytesseract.image_to_string(test_message, lang='eng',
config='--psm 10 --oem 3 -c '
'tessedit_char_whitelist=0123456789QWERTYUIOPLKJHGFDSAZXCVBNM')
target = target.replace('\n', '').replace('\r', '')
print(f"图片路径:{img_path},ocr识别结果为:{target}")
return target
def collect(target, source):
"""
收集图片
:param target: 目标路径
:param source: 源路径
:return:
"""
target = "./captchas_new/" + target + "/"
if str(target) in list_new:
shutil.move(source, target)
print(f"移动文件成功,源文件为:[{source}]")
else:
print(f"移动文件失败,{source}文件识别结果为[{target}]")
for path in split_list:
print(path)
new_path = "./splits/" + path
source = ocr(new_path)
collect(source, new_path)
至此,我们的数据清洗工作就完成了!
2.4、特征工程
在特征工程阶段,我们要对图片的数据特征进行变换。特征变换的手段对于数值特征和分类特征是不同的。
我们这里属于分类特征,那对标签我们使用独热编码进行变换。而图片数据,我们通过特征缩放变换来压缩特征的空间。

在这个环节,我们要将图片转换成机器可以识别的数据,然后就可以把数据集喂给模型了。这里我们将图片转换成 NumPy 数组也叫张量数组,对张量数组进行归一化缩放;将标签转换成One-Hot编码。
什么是张量数组
在深度学习中,模型的输入通常都是张量数组。通过使用张量数组,可以对大量的数据进行高效的处理和计算。
张量数组其实就是一个多维数组。他可以存储和处理大量的数据。例如,图像可以表示为三维数组,其中第一个维度表示图像的高度,第二个维度表示图像的宽度,第三个维度表示图像的颜色通道。文本数据可以表示为二维数组,其中第一个维度表示文本的序列长度,第二个维度表示每个单词的向量表示。
什么是One-Hot编码
One-hot编码是一种常见的数据编码方式,用于将离散的、分类的数据转换为机器学习算法能够使用的数值型数据。在One-hot编码中,每个离散的特征值(也称为类别、标签或因子)被编码为一个长度为特征数量的二进制向量,其中只有一个元素为1,其他元素均为0。这个1所在的位置就代表了该特征值所属的类别。
首先,我们通过OpenCV来读入图片的数据,并使用NumPy将图片转换成张量数组。
import numpy as np
import pandas as pd
import os
import cv2
list = ["2","3","4","5","6","7","8","9","A","B","C","D","E","F","G","H","J","K","L","M","N","P","Q","R","S","T","U","V","W","X","Y","Z"]
X = []
y_label = []
imgsize = [105, 96]
def training_data(label, data_dir):
for img in os.listdir(data_dir):
path = os.path.join(data_dir, img) # 目录+文件名
img = cv2.imread(path,cv2.IMREAD_COLOR) #读入图片
img = cv2.resize(img,(imgsize[0],imgsize[1])) #设定图片像素维度
X.append(np.array(img)) #X特征集
y_label.append(str(label)) #y标签
for label in list:
training_data(label, f'./captchas_new/{label}')
这段代码很简单,我们通过 for 循环调用 training_data() 方法,在这个方法中,通过 cv2.imread 读取os路径的图片数据,然后通过 cv2.resize(img,(imgsize[0],imgsize[1]))统一图片的像素维度。收集特征和标签分别到 X = [] 和 y_label = []集合中。
然后通过 NumPy将图片转换为张量数组
X = np.array(X) # 将X从列表转换为张量数组
现在我们要对张量数组再进行特征变换,由于我们的特征都是0~255之间的数值,所以这里选择特征缩放,即归一化缩放。
X = X/255 # 将X张量归一化
然后我们对标签进行编码及特征变换的处理。这里要使用 sklearn 库的LabelEncoder编码工具,然后通过 keras 库的 to_categorical 进行One-hot编码。
from sklearn.preprocessing import LabelEncoder # 导入标签编码工具
from keras.utils import to_categorical # 导入One-hot编码工具
label_encoder = LabelEncoder()
y = label_encoder.fit_transform(y_label) # 标签编码
y = to_categorical(y, 32) # 将标签转换为One-hot编码
好了,现在我们的特征集X和标签集 y 就构建完毕了,在特征工程阶段,我们对特征集X进行了归一化缩放,对标签集y进行了One-hot编码,做这些工作的目的就是为了能够把数据集喂给模型。
2.4、构建特征集和标签集
这里我们要借助 sklearn 库的 model_selection 模块的 train_test_split 拆分工具来拆分数据集。我们将特征集拆分为训练集 X_train 和 测试集 X_test,将标签集拆分为训练集 y_train 和 测试集 y_test。并且训练集和测试集的比例是8:2
from sklearn.model_selection import train_test_split # 导入拆分工具
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,random_state=1)
3、选择算法
图像的处理,使用深度学习的神经网络算法肯定是更胜一筹,它擅长对复杂特征的提取。
神经网络算法又分为CNN、RNN、DNN等,而卷积神经网络对图像等数据进行特征提取和分类则是比较有优势,所以这里我们选择卷积神经网络CNN算法。
举例:车牌识别
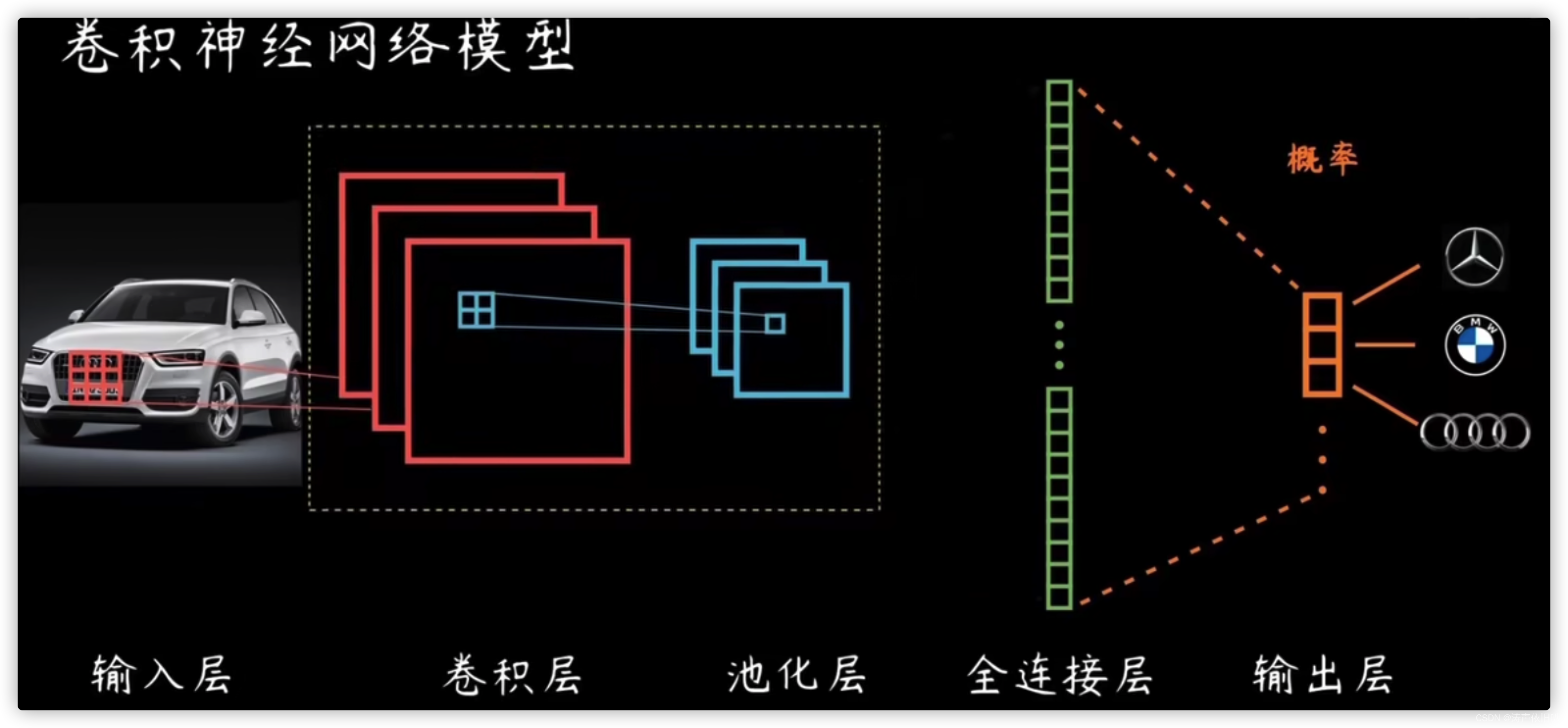
卷积神经网络?
卷积神经网络(CNN)是一种常用的神经网络模型,特别适用于图像、视频和语音等高维度数据的处理和分析。其主要原理是通过卷积操作和池化操作来提取数据的特征,并通过全连接层将这些特征映射到输出层进行分类或回归。
卷积神经网络结构:卷积神经网络由输入层、一个或多个卷积层和输出层的全连接层组成。

- 输入层:接收输入数据,并将其传递到下一层。什么输入数据?就是特征缩放后的数据。
- 卷积层:主要负责提取图片的特征。其中的卷积核(上图中红框部分)也叫滤波器,能够自动进行图像特征的提取。
- 最大池化层:就是将特征映射划分为若干个矩形区域,挑选每个区域中的最大值,也就是最明显的特征作为采样的结果。可以避免过拟合。
- 多个卷积层和池化层能够实现对图像特征的逐层提取。
- 展平层,主要负责将网络展平。展平之后通常会接一个普通的全连接层。而最右边的输出层也是全连接层,用 Softmax 进行激活分类输出层,Softmax 函数的主要作用是将神经网络输出的实数值转化为概率分布。
建立CNN算法模型
借助 keras库的layers和models工具我们建立CNN模型
from keras import layers # 导入所有层
from keras import models # 导入所有模型
import joblib
# 贯序模型 ,序贯模型也是最简单的模型,就是像盖楼一样,一层一层往上堆叠着搭新的层。
cnn = models.Sequential()
# 激活函数接收神经元的输入信号,经过非线性变换后输出神经元的激活值。这个激活值通常被用于传递到下一层神经元或输出层中。激活函数可以增加模型的表达能力和拟合能力
cnn.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(96, 105, 3)))# 输入卷积层
cnn.add(layers.MaxPooling2D((2, 2))) # 最大池化层
cnn.add(layers.Conv2D(64, (3, 3), activation='relu')) # 卷积层
cnn.add(layers.MaxPooling2D((2, 2))) # 最大池化层
cnn.add(layers.Conv2D(128, (3, 3), activation='relu')) # 卷积层
cnn.add(layers.MaxPooling2D((2, 2))) # 最大池化层
cnn.add(layers.Conv2D(128, (3, 3), activation='relu')) # 卷积层
cnn.add(layers.MaxPooling2D((2, 2))) # 最大池化层
cnn.add(layers.Flatten()) # 展平层
cnn.add(layers.Dense(512, activation='relu')) # 全连接层
# 32表示种类,激活函数使用Softmax
cnn.add(layers.Dense(32, activation='softmax')) # 分类输出层
# 设置优化器
cnn.compile(loss='categorical_crossentropy', # 损失函数
optimizer='RMSprop',
metrics=['acc']) # 评估指标
4、训练模型
通过fit 拟合模型,指定训练轮次,训练的同事进行验证
在训练过程中,我们还指定了 validation_split,它可以在训练的同时,自动把训练集部分拆出来,进行验证,在每一个训练轮次中,求出该轮次在训练集和验证集上面的损失和预测准确率。
# 训练网络并把训练过程信息存入history对象
history = cnn.fit(X_train,y_train, #训练数据
epochs=50, #训练轮次(梯度下降)
validation_split=0.2) #训练的同时进行验证
然后将训练的模型保存到 model.h5文件中
cnn.save(os.path.join(os.path.dirname("./result"), 'model.h5'))
Train on 2089 samples, validate on 523 samples
Epoch 1/50
2089/2089 [==============================] - 86s 41ms/step - loss: 1.3523 - acc: 0.3978 - val_loss: 1.0567 - val_acc: 0.5411
Epoch 2/50
2089/2089 [==============================] - 85s 41ms/step - loss: 1.0167 - acc: 0.5692 - val_loss: 1.0336 - val_acc: 0.5526
Epoch 3/50
2089/2089 [==============================] - 85s 41ms/step - loss: 0.8912 - acc: 0.6343 - val_loss: 0.9183 - val_acc: 0.6310
Epoch 4/50
2089/2089 [==============================] - 84s 40ms/step - loss: 0.8295 - acc: 0.6596 - val_loss: 0.9289 - val_acc: 0.6138
Epoch 5/50
2089/2089 [==============================] - 85s 41ms/step - loss: 0.7228 - acc: 0.7056 - val_loss: 1.0086 - val_acc: 0.5736
... ...
这个输出的信息包括了训练的轮次(梯度下降的次数)、每轮训练的时长、每轮训练过程中的平均损失,以及分类的准确度。这里的每一个轮次,其实就是神经网络对其中的每一个神经元自动调参、通过梯度下降进行最优化的过程。
5、评估和优化模型
优化器和学习速率
在卷积神经网络中,优化器和学习速率是两个常用的超参数,用于调节模型的训练过程和优化效果。
**优化器(Optimizer)**是指模型在训练过程中使用的优化算法,用于更新模型的权重和偏置参数,使得模型的损失函数最小化。前较常用的是 RMSprop 和 Adam
学习速率(Learning Rate)是指模型在每次参数更新时,更新的步长大小。学习速率通常是一个非常重要的超参数,它能够影响模型的训练速度和优化效果。如果学习速率过大,可能会导致模型参数在更新过程中产生过大的波动,使得模型无法收敛;而如果学习速率过小,可能会导致模型训练缓慢,需要更长时间才能收敛。
优化器是用于解决神经网络中的局部最低点的问题。
神经网络也是通过梯度下降来实现参数的最优化,梯度下降是通过求导实现的。神经网络因为函数十分复杂,会出现很多的局部最低点,在每一个局部最低点,导数的值都为 0。没有求导后的正负,梯度下降也就没有任何方向感,所以这时候,优化神经网络的参数也不知道应该往哪里走了。

学习速率(Learning Rate)是指模型在每次参数更新时,更新的步长大小。学习速率通常是一个非常重要的超参数,它能够影响模型的训练速度和优化效果。如果学习速率过大,可能会导致模型参数在更新过程中产生过大的波动,使得模型无法收敛;而如果学习速率过小,可能会导致模型训练缓慢,需要更长时间才能收敛。因此,选择合适的学习速率非常重要,通常需要通过实验和调参来确定最佳的学习速率。
如何设定优化器?==**
cnn.compile(loss='categorical_crossentropy', # 损失函数 行15
optimizer=Adam(learning_rate=1e-4), # 优化器和学习速率
metrics=['acc']) # 评估指标
显示训练过程中的损失曲线
在训练模型时,我们将训练的过程信息保存到了history对象中,通过history对象我们可以查看训练集上的损失以及验证集上的准确率。
# 训练网络并把训练过程信息存入history对象
history = cnn.fit(X_train,y_train, #训练数据
epochs=50, #训练轮次(梯度下降)
validation_split=0.2) #训练的同时进行验证
通过matplotlib画出损失曲线和准确率曲线
def show_history(history): # 显示训练过程中的学习曲线
loss = history.history['loss'] #训练损失
val_loss = history.history['val_loss'] #验证损失
epochs = range(1, len(loss) + 1) #训练轮次
plt.figure(figsize=(12,4)) # 图片大小
plt.subplot(1, 2, 1) #子图1
plt.plot(epochs, loss, 'bo', label='Training loss') #训练损失
plt.plot(epochs, val_loss, 'b', label='Validation loss') #验证损失
plt.title('Training and validation loss') #图题
plt.xlabel('Epochs') #X轴文字
plt.ylabel('Loss') #Y轴文字
plt.legend() #图例
acc = history.history['acc'] #训练准确率
val_acc = history.history['val_acc'] #验证准确率
plt.subplot(1, 2, 2) #子图2
plt.plot(epochs, acc, 'bo', label='Training acc') #训练准确率
plt.plot(epochs, val_acc, 'b', label='Validation acc') #验证准确率
plt.title('Training and validation accuracy') #图题
plt.xlabel('Epochs') #X轴文字
plt.ylabel('Accuracy') #Y轴文字
plt.legend() #图例
plt.show() #绘图
show_history(history) # 调用这个函数
通过 evaluate方法 可以评估模型在测试集上的准确率
result = cnn.evaluate(X_test, y_test) #评估测试集上的准确率
print('CNN的测试准确率为',"{0:.2f}%".format(result[1]))
下面是训练集和验证集的损失曲线和准确率曲线。
1)训练5次的结果。下面的损失曲线在验证集上是有一些波动的,效果并不是很好

2)训练24次,模型在测试集上的准确率为 95%

3)训练50次,模型在测试集上的准确率为 96%

这个时候,其实无论训练多少次,都没有多大作用了!我们要考虑优化模型的超参数了!
调整超参数:优化器和学习速率
我们将优化器由 Adam 更换为 RMSprop ,并且我们没有指定学习速率,RMSprop 优化器是一种自适应学习率算法,它可以根据梯度的大小自动调整学习速率。
cnn.compile(loss='categorical_crossentropy', # 损失函数 行15
# optimizer=Adam(learning_rate=1e-4), # 优化器
optimizer='RMSprop',
metrics=['acc']) # 评估指标
训练50次,使用RMSprop优化器,模型在测试集上的准确率为 99%

至此,我们训练的模型已经满足我们的要求了,它对验证码的识别准确率达到了 99%。
6、部署模型
模型已经训练出来了,我们现在要将模型部署到服务器上,然后通过域名对外提供API服务,这里我们选择了Django框架。因为有同事是使用这个框架部署的,可以借鉴一些经验,少踩坑!
Diango: Django是一个基于Python的Web应用程序框架。使用简单,社区很活跃,是python语言中开发Web应用的首选框架。
https://www.djangoproject.com/
具体涉及公司隐私内容,不便展示😀。
🎉 如果喜欢这篇文章,点赞👍 收藏⭐ 关注 ✅ 哦,创作不易,感谢!😀




















 999
999

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











