






从地铁客流量来看上海阳性感染者情况
最近上班的时候,有一个明显的感觉,那就是:公交车上的人越来越少了,路上的车越来越少了,平常一个小时的行程,现在四十分钟就可以了。上班人员的减少,从侧面反映出阳性感染者不断增加,居家办公的人数越来越多。但,这是否预示着上海的这波疫情已经达到顶峰,或者还在继续扩大。因此,我们通过观察上海地铁客流量的变化,来观察上海这波疫情情况。
一、数据来源
通过百度搜索知道,上海地铁微博每天会发布上海地铁的客流情况,因此打算从上海地铁微博爬取每日的客流量数据。

二、数据获取
2.1、用到的python库
-
运用
requests访问上海地铁微博网页,获取原始数据; -
运用
re库解析原始数据,获取地铁客流量数据。
2.2、思路解析
2.2.1、找到目标URL
1)登录自己的微博,并切换到“上海地铁shmetro”微博首页;
2)在页面空白处单击右键,并选择【检查】,调出开发者工具界面;
3)在弹出的开发者工具界面,选择【网络】选项卡,然后重新刷新页面;
4)在开发者工具界面点击放大镜进行搜索;在搜索框中输入“地铁网络客流”;
5)选中搜索结果,然后点击标头,便可以找到目标URL地址。
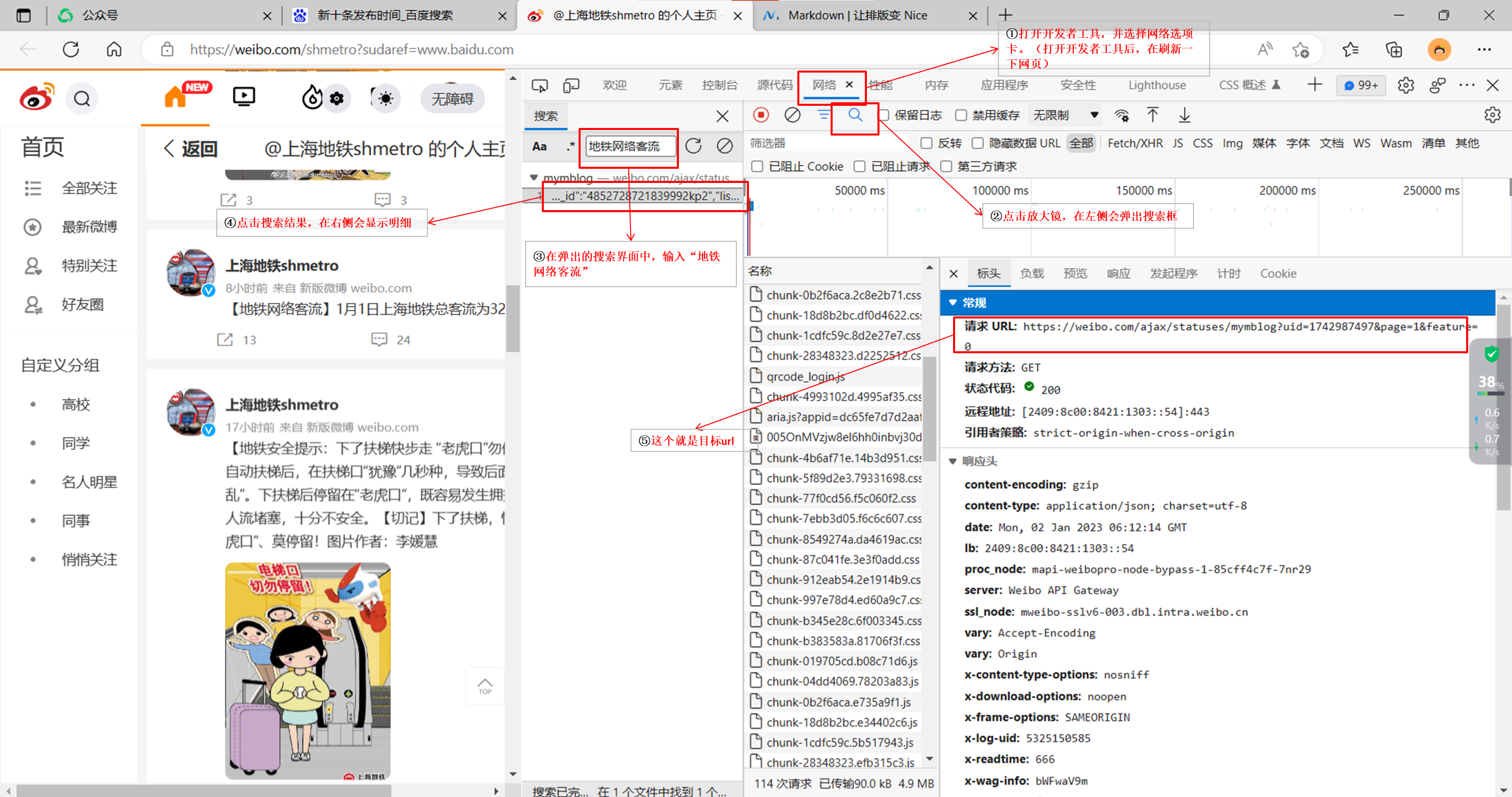
2.2.2、访问目标
import requests
import re
import pandas as pd
def get_content(page,since_id):
since_id=since_id#当访问第二页数据时,需要该参数
page = page
if since_id is None:
url=str('https://weibo.com/ajax/statuses/mymblog?uid=1742987497&page='+str(page)+'&feature=0')
else:
url=str('https://weibo.com/ajax/statuses/mymblog?uid=1742987497&page='+str(page)+'&feature=0&since_id='+str(since_id))
headers = {
"authority":"weibo.com",
"method":"GET",
"path":"/ajax/statuses/mymblog?uid=1742987497&page=1&feature=0",
"scheme": "https",
"accept": "application/json, text/plain, */*",
"accept-encoding": "gzip, deflate, br",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"client-version": "v2.37.21",
"cookie": "需要替换成自己的cookie",
"referer": "https://weibo.com/u/1742987497",
"sec-ch-ua": "'Microsoft Edge';v='107', 'Chromium';v='107', 'Not=A?Brand';v='24'",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "Windows",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin",
"server-version": "v2022.12.30.4",
"traceparent": "00-68055a6f6dd06c7642e847a62527f526-fa55575be1511b1b-00",
"user-agent": "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.35",
"x-requested-with": "XMLHttpRequest",
"x-xsrf-token": "hvhCFVwWluphipcsxJqBPYsK"
}#请求头,就是把目标URL下面的请求头都复制过来就可以了。
response = requests.get(url, headers=headers)
mycontent = response.json()#返回的数据是json格式的数据
return mycontent
2.2.3、解析目标
def parse_content(mycontent):
mycontent=mycontent
temp = mycontent["data"]["list"]
group_count = len(temp)
population = []
daytime = []
createtime = []
orgtext = []
for i in range(group_count):
search_result = re.search("地铁网络客流",temp[i]["text"],re.S)#得到发布客流量的那个微博消息
if search_result is not None:
population_temp = float(re.search("([0-9.]+)万",temp[i]["text"],re.S).group(1))
daytime_temp = re.search("[0-9]+月[0-9]+日",temp[i]["text"],re.S).group()
createtime_temp = temp[i]["created_at"]
orgtemp = temp[i]["text"]
population.append(population_temp)
daytime.append(daytime_temp)
createtime.append(createtime_temp)
orgtext.append(orgtemp)
return population,daytime,createtime,orgtext
2.2.4、获取数据
population = []
daytime = []
createtime = []
orgtext = []
for m in range(1,40):
if m == 1:
mycontent = get_content(page=m,since_id=None)
since_id = mycontent["data"]["since_id"]
else:
since_id = mycontent["data"]["since_id"]
mycontent = get_content(page=m,since_id=since_id)
population_temp,daytime_temp,createtime_temp,orgtemp=parse_content(mycontent)
population.extend(population_temp)
daytime.extend(daytime_temp)
createtime.extend(createtime_temp)
orgtext.extend(orgtemp)
passengerdf = pd.DataFrame()
passengerdf["createtime"] = createtime
passengerdf["population"] = population
passengerdf["daytime"] = daytime
passengerdf["orgtext"] = orgtext
2.2.5、获取的目标数据截图
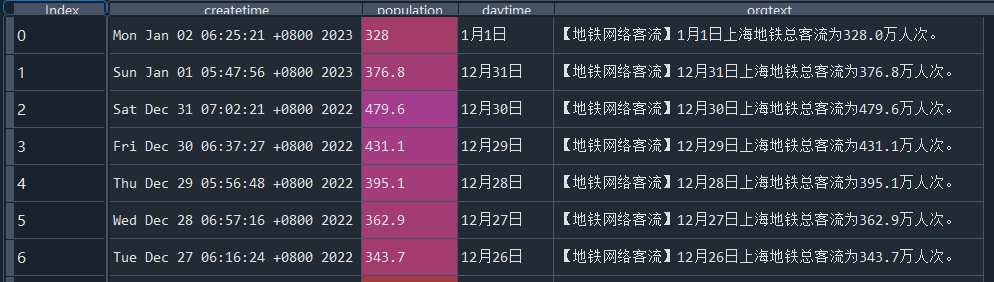
三、客流量趋势图
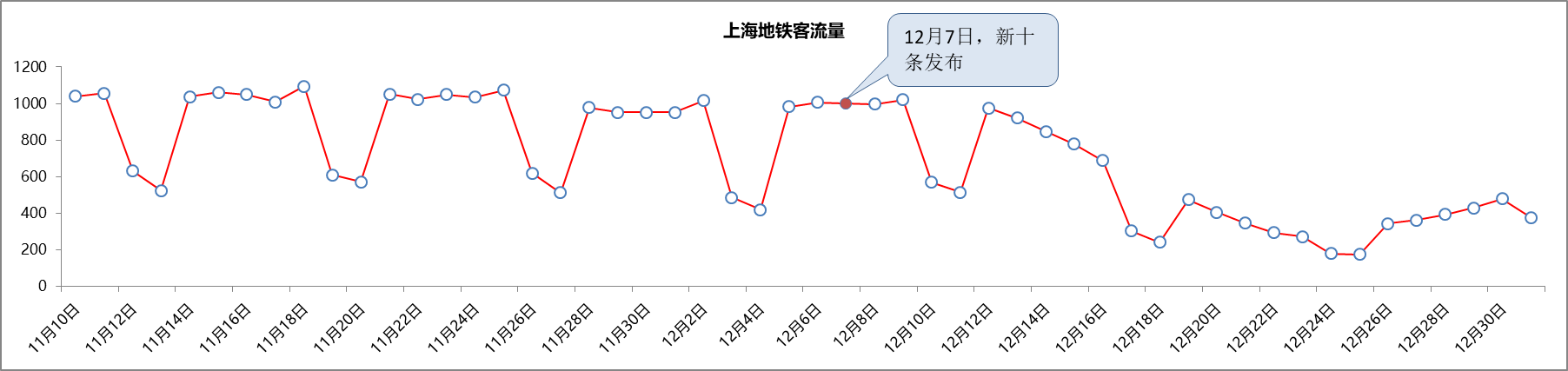
从客流量趋势来看,新十条发布后,上海地铁客流量连续两周下降,由1000多万水平下降至300多万水平。在12月26日达到低谷之后,从12月27日开始,客流量开始有逐渐回升的趋势。
因此根据上述客流量可以预估,上海第一波感染的高峰在12月26日。此后,第一波感染者开始陆续返岗,并且返岗人数大于阳性居家人数。
本文写的并不详细,如有疑惑的地方可查看我的往期文章(网络爬虫学习笔记目录)学习一下基础的网络爬虫知识。














 3258
3258











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









