







一、Vision Transformer
Vision Transformer (ViT)将Transformer应用在了CV领域。在学习它之前,需要了解ResNet、LayerNorm、Multi-Head Self-Attention。
ViT的结构图如下:
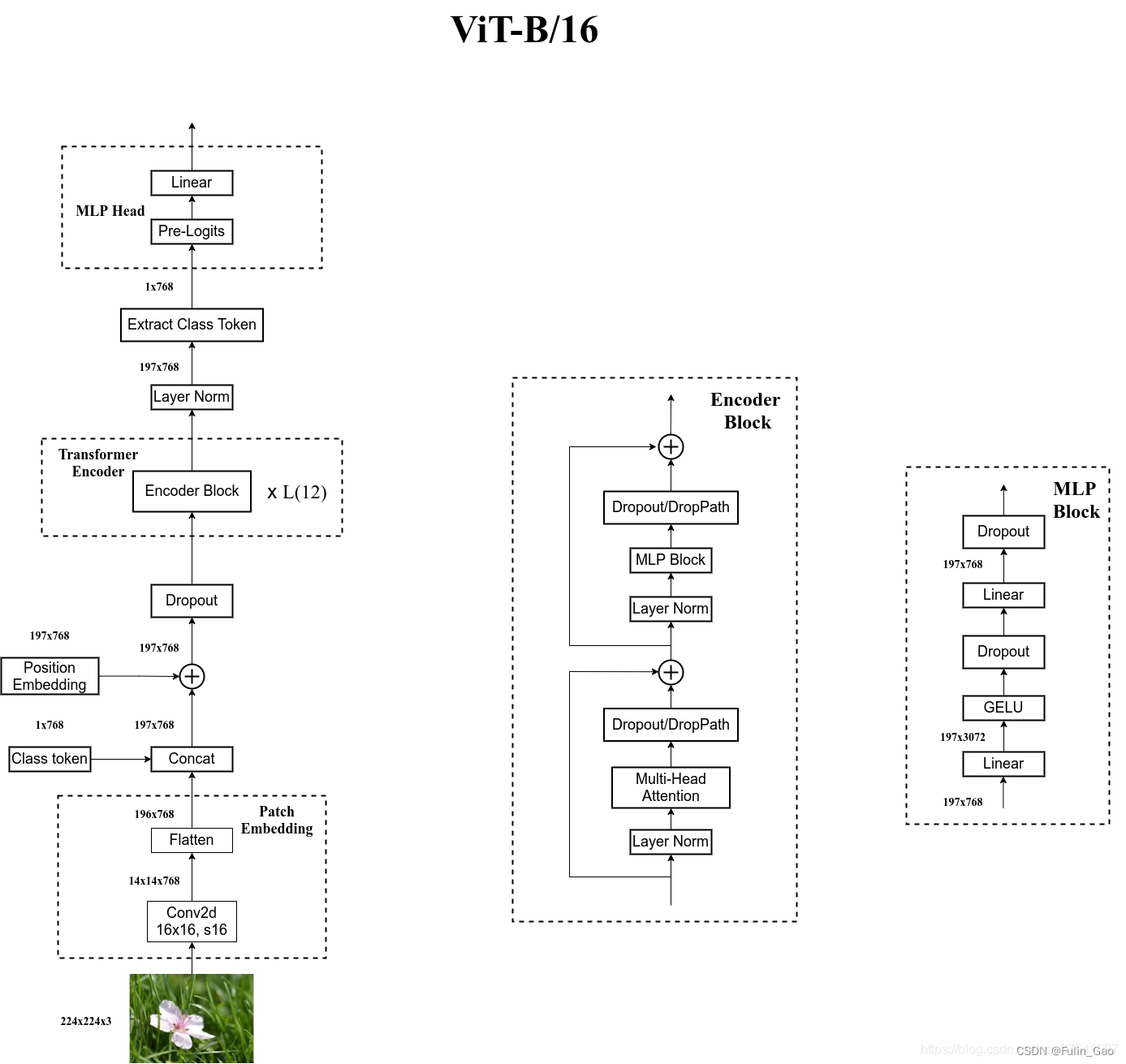
如图所示,ViT主要包括Embedding、Encoder、Head三大部分。Class token、Position Embedding、Extract Class Token等部分会按照顺序穿插讲解。
1. Patch Embedding
由于多头自注意力是针对NLP提出的,它的输入尺度为 [ b a t c h _ s i z e , n u m _ t o k e n , d i m _ t o k e n ] [batch\_size,num\_token,dim\_token] [batch_size,num_token,dim_token],而CV中图像输入尺度通常为 [ b a t c h _ s i z e , n u m _ c h a n n e l , h e i g h t , w i d t h ] [batch\_size, num\_channel,height,width] [batch_size,num_channel,height,width],ViT通过Patch Embedding将其尺度转换至期望的形式。

如上图所示,假设一张图像的尺寸为 [ 3 , 224 , 224 ] [3,224,224] [3,224,224],ViT会将其均分为多个Patch(上图是 3 ∗ 3 = 9 3*3=9 3∗3=9个,结构图中是 14 ∗ 14 = 196 14*14=196 14∗14=196个),于是每个Patch的尺度为 [ 3 , 16 , 16 ] [3,16,16] [3,16,16]( 16 = 224 ÷ 14 16=224\div14 16=224÷14)。对于每个Patch,ViT使用一层2D卷积进行特征提取可以得到尺度为 [ 768 , 14 , 14 ] [768,14,14] [768,14,14]的特征(卷积核大小和步长均与Patch一致,输出通道数为768)。
之后将 [ 768 , 14 , 14 ] [768,14,14] [768,14,14]的特征转置为 [ 14 , 14 , 768 ] [14,14,768] [14,14,768]的并将其展平即可得到 [ 196 , 768 ] [196,768] [196,768]的特征,此时转换完成,196即为token的数量,768为token的向量长度。
由于ViT处理的是分类任务,所以它参考BERT特地拼接上了一个大小为 [ 1 , 768 ] [1,768] [1,768]的Class token,于是现在token的大小变成 [ 197 , 768 ] [197,768] [197,768]。ViT中Class token是一个初始化为0的可学习参数向量。通常Class token会被单独拿出来作为ViT提取出来的图像特征用于下游任务,例如,ViT中跟了一个分类头进行分类,广义类发现中GCD、OpenCon等方法直接使用该特征进行半监督聚类。
另外,ViT保留了Transformer中的位置编码(Position Embedding),它也是初始化为0的可学习参数,不过不是拼接而是加入,所以其大小为 [ 197 , 768 ] [197,768] [197,768],与当前token的大小一致。
此时,所以token的准备完成,一个批次的图像转换为token后尺度是 [ b a t c h _ s i z e , n u m _ t o k e n , d i m _ t o k e n ] [batch\_size,num\_token,dim\_token] [batch_size,num_token,dim_token]( n u m _ t o k e n = 197 , d i m _ t o k e n = 768 ] num\_token=197,dim\_token=768] num_token=197,dim_token=768])。
2. Transformer Encoder
该部分是ViT进行特征提取的主体部分,包括多个下图中的Encoder Block,例如ViT-B/16中有12个,ViT-L/16中有24个:

可以看出,除残差结构、Layer Norm、DropPath外,关键模块为Mutil-Head Attention和MLP Block。个人认为由于Mutil-Head Attention和MLP Block最后可能包含Dropout操作,所以有些方法在后面跟的是DropPath而非Dropout。
对于Mutil-Head Attention,由于ViT已经将图像转为了token,所以Mutil-Head Attention可以被即插即用,本质上它是对输入进行加权,详情请参考Multi-Head Attention。
对于MLP Block,它包括两层全连接(第一层输入大小为 768 768 768输出大小为 768 ∗ 4 768*4 768∗4,第二层输入大小 768 ∗ 4 768*4 768∗4输出大小为 768 768 768)、一层激活函数(GELU)、一层Dropout。
所以Transformer Encoder是通过Mutil-Head Attention和MLP进行多次特征提取,提取过程不改变原输出大小,因此Transformer Encoder的输出大小仍为 [ b a t c h _ s i z e , n u m _ t o k e n , d i m _ t o k e n ] [batch\_size,num\_token,dim\_token] [batch_size,num_token,dim_token]( n u m _ t o k e n = 197 , d i m _ t o k e n = 768 ] num\_token=197,dim\_token=768] num_token=197,dim_token=768])。
之后,经过Layer Norm,即可取出其中Class token所对应的部分(Extract Class Token),大小为 [ b a t c h _ s i z e , 1 , 768 ] [batch\_size,1,768] [batch_size,1,768]。这个就是很多方法直接取用的由ViT提取的图像特征。
3. MLP Head
该部分属于下游任务的自定义部分,ViT使用MLP作为分类头,其结构图如下:
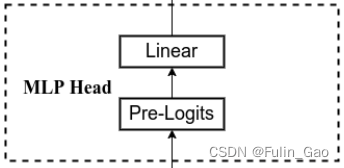
如图所示,MLP Head包括两个部分Pre-Logits和Linear。
Pre-Logits是一个全连接层加一层Tanh激活,通常我们做下游任务时不使用它,而是仅使用Linear,即一个输入为768输出为待分类类别数量的全连接层。
致谢:
本博客仅做记录使用,无任何商业用途,参考内容如下:
ViT| Vision Transformer |理论 + 代码
Vision Transformer详解















 6276
6276











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











