






数学建模常用方法及MATLAB代码
二分法
我们通常使用二分法计算非线性方程或者超越方程近似根,MATLAB代码为:
// 二分法求根
function [x0,n]=dichotomy(a,b,err,f_x)
%输入参数a为根的区间左端点
%输入参数b为根的区间右端点
%输入参数err为误差精度
% 输入参数f_x为待求根函数
%输出参数x0为满足精度要求的根
% 输出参数n为迭代的次数
n=ceil((log((b-a)./err)./log(2)-1));%求迭代次数
while(sign(f_x(a))==0)%如果a的函数值为0停止迭代输出x0为a的值,迭代次数为0
x0=a;
n=0;
return;
end
while(sign(f_x(b))==0)%如果b的函数值为0停止迭代输出x0为b的值,迭代次数为0
x0=b;
n=0;
return;
end
while(sign(f_x(a))~=sign(f_x(b)))%a、b符号不同进行区间二分
x0=a/2+b/2; %区间中点
if(sign(f_x(a))~=sign(f_x(x0)))%判断区间中点函数值与区间端点符号
b=x0; %将中点赋值给符号相同的端点
if(b-a<=err||abs(f_x(x0))<=err)%判断是否满足精度要求
x0=a/2+b/2;
return;
else %不满足精度循环调用二分法
dichotomy(a,b,err,f_x);
end
else
a=x0; %将中点赋值给符号相同的端点
if(b-a<=err||abs(f_x(x0))<=err)%判断是否满足精度要求
x0=a/2+b/2;
return;
else %不满足精度循环调用二分法
dichotomy(a,b,err,f_x);
end
end
end
量纲分析法
π定理的解题步骤:
(1)确定关系式:根据对所研究的现象的认识,确定影响这个现象的各个物理量及其关系式:
(2)确定基本量:从n个物理量中选取所包含的m个基本物理量作为基本量纲的代表,一般取m=3。在管流中,一般选d,v,ρ三个作基本变量,而在明渠流中,则常选用H,v,ρ。
(3)确定π数的个数N(π)=(n-m),并写出其余物理量与基本物理量组成的π表达式
(4)确定无量纲π参数:由量纲和谐原理解联立指数方程,求出各π项的指数x,y,z,从而定出各无量纲π参数。π参数分子分母可以相互交换,也可以开方或乘方,而不改变其无因次的性质。
(5)写出描述现象的关系式或显解一个π参数,或求得一个因变量的表达式。
选择基本量时的注意原则:
1)基本变量与基本量纲相对应。即若基本量纲(M,L,T)为三个,那么基本变量也选择三个;倘若基本量纲只出现两个,则基本变量同样只须选择两个。
2)选择基本变量时,应选择重要的变量。换句话说,不要选择次要的变量作为基本变量,否则次要的变量在大多数项中出现,往往使问题复杂化,甚至要重新求解。
3)不能有任何两个基本变量的因次是完全一样的,换言之,基本变量应在每组量纲中只能选择一个。
图论法

其MATLAB代码为:
// 图论算法
function P = dgraf( A )
%A为图的邻接矩阵
%P为图的可达矩阵
n=size(A,1);
P=A;
for i=2:n
P=P+A^i;
end
P(P~=0)=1;
P;
end
应用举例:
A=[0 1 1 1;1 0 1 1;1 1 0 1;1 1 10];
P=dgraf(A);
P=[1 1 1 1;1 1 1 1;1 1 1 1;1 1 1 1];
差分法
背景差分法是采用图像序列中的当前帧和背景参考模型比较来检测运动物体的一种方法,其性能依赖于所使用的背景建模技术。背景构建的方法有多种,简单的有均值法、中值法,复杂点的有卡尔曼滤波器模型法、单高斯分布模型法、双高斯分布模型法等,这里我用的是均值法。以下是相应的matlab代码和输出结果:
// 差分法
%背景差分法
clear all;
clc;
avi=MMREADER('I:\\电影\\test.avi');
VidFrames=read(avi,[10000,10050]);
N=4;
start=11;
threshold=15;
bg(start).cdata=0;
i=1;
for k=start-10:start-1 bg(k).cdata=rgb2gray(VidFrames(:,:,:,k)); bg(start).cdata=abs((bg(start).cdata+bg(k).cdata)/i); %均值法构建背景
i=i+1;
end
for k=1+start:N+1+start mov(k).cdata=rgb2gray(VidFrames(:,:,:,k)); %转化成灰度图
end
[row,col]=size(mov(1+start).cdata);
alldiff=zeros(row,col,N);
bgpic=zeros(row,col,1);
bgdata=bg(start).cdata>threshold;
bgpic(:,:,1)=double(bgdata);
figure(1);
imshow(bgpic(:,:,1)) %输出构建的背景
for k=1+start:N+start
diff=abs(mov(k).cdata-bg(start).cdata);
idiff=diff>threshold;
alldiff(:,:,k)=double(idiff);
end
j=2;
for k=1+start:N+start
figure(j);
imshow(alldiff(:,:,k)) %输出测试帧减去构建背景的效果
title(strcat(num2str(k),'帧','-','背景'));
j=j+1;
end
变分法
//变分法
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
I=imread('toys.bmp'); % load image
I=double(I(20:120,10:105)); % cut a piece, convert to double
%%% Parameters
std_n=10; var_n=std_n^2; % Gaussian noise standard deviation
reduced_pw = 1.5*var_n; % power to reduce in first phase
sig_w = 5; ws=4*sig_w+1; % window size
%%%%%%%%%%%%%%
%%% Add noise
In = randn(size(I))*std_n;
I0 = I + In; % noisy input image
% show original and noisy images
figure(1); imshow(uint8(I)); title('Original')
figure(2); imshow(uint8(I0)); title('Noisy image')
snr_noisy=db(I,I0)
% run normal tv - strong denoising
tic;
J=I0;
ep_J=0.1; % minimum mean change in image J
J_old=0;
lam=0; iter=10; dt=0.2; ep=1;
while (mean(mean(abs(J - J_old))) > ep_J), % iterate until convergence
J_old=J;
J=tv(J,iter,dt,ep,lam,I0); % scalar lam
lam = calc_lam(J,I0,reduced_pw); % update lambda (fidelity term)
end % while
% figure(3); imshow(uint8(J)); title('residue TV')
% snr_residue= db(I,J)
Ir=I0-J; % Ir scalar
Pr = mean(mean(Ir.^2)); % power of residue
LV = loc_var(Ir,ws,sig_w^2); % local variance (local power of the residue )
% P=mean(mean(LV));
Pxy=1*(var_n^2)./LV; %% Sxy inverse proportional to the LV
%%% Varying Lambda
lamxy=zeros(size(I0));
J=I0; J_old=0;
ep_J=0.001;
%eps=0.01;
while (mean(mean(abs(J - J_old))) > ep_J), % iterate until convergence
J_old=J;
J=tv(J,iter,dt,ep,lamxy,I0); % adaptive lam
%J=tv(J,iter,dt,ep_J,lamxy,I0);
lamxy = calc_lamxy(J,I0,Pxy,sig_w); % update lambda (fidelity term)
end % while
figure(3); imshow(uint8(J)); title('Adaptive TV')
snr_adap= db(I,J)
toc
t1=toc
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% Run scalar TV denoising for comparision
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
tic
J=I0;
% params
ep_J = 0.01; % minimum mean change in image J
lam=0; J_old=0;
i=0;
while (mean(mean(abs(J - J_old))) > ep_J), % iterate until convergence
J_old = J;
J=tv(J,iter,dt,ep,lam,I0); % scalar lam
lam = calc_lam(J,I0,var_n,ep); % update lambda (fidelity term)
end % for i
% Ir=I0-J; % Ir scalar
% Pr = mean(mean(Ir.^2)); % power of residue
function Ig=gauss(I,ks,sigma2)
%private function: gauss (by Guy Gilboa):
% Ig=gauss(I,ks,sigma2)
% ks - kernel size (odd number)
% sigma2 - variance of Gaussian
[Ny,Nx]=size(I);
hks=(ks-1)/2; % half kernel size
if (Ny<ks) % 1d convolutin
x=(-hks:hks); %x:1x ks
flt=exp(-(x.^2)/(2*sigma2)); % 1D gaussian
flt=flt/sum(sum(flt)); % normalize
% expand
x0=mean(I(:,1:hks)); xn=mean(I(:,Nx-hks+1:Nx));%x0,xn :1 x hks;
eI=[x0*ones(Ny,ks) I xn*ones(Ny,ks)]; % ???
Ig=conv(eI,flt);
Ig=Ig(:,ks+hks+1:Nx+ks+hks); % truncate tails of convolution
else
%% 2-d convolution
x=ones(ks,1)*(-hks:hks); y=x';
flt=exp(-(x.^2+y.^2)/(2*sigma2)); % 2D gaussian
flt=flt/sum(sum(flt)); % normalize
% expand
if (hks>1)
xL=mean(I(:,1:hks)')'; xR=mean(I(:,Nx-hks+1:Nx)')';% xL,xR :Ny x 1
else
xL=I(:,1); xR=I(:,Nx);
end
eI=[xL*ones(1,hks) I xR*ones(1,hks)]; % Ny x Nx+2hks
if (hks>1)
xU=mean(eI(1:hks,:)); xD=mean(eI(Ny-hks+1:Ny,:)); % xU,xD: 1 x Nx+2hks
else
xU=eI(1,:); xD=eI(Ny,:);
end
数据拟合法
以下以一个较为简单的数据组作为示例:
//数据拟合法
clc;
clear;
% the first one;
R=[0.68 0.805 0.863 0.893 0.9122 0.916];
x=[1.07 2.24 3.86 5.91 8.5 11.5];
y=R./(1-R);
plot(x,y,'ro')
hold on
x=x'; % transfer Row matrix to Column matrix;
y=y';
p=fittype('(x/a)*exp(-x/b)') % Fitting function
f=fit(x,y,p)
plot(f,x,y);
回归分析法
在 Matlab 中,可以直接调用命令实现回归分析,
( 1 ) [b,bint,r,rint,stats]=regress(y,x) ,其中 b 是回归方程中的参数估计值, bint 是 b 的置信区间, r 和 rint 分别表示残差及残差对应的置信区间。stats 包含三个数字,分别是相关系数, F 统计量及对应的概率 p 值。
( 2 ) recplot(r,rint) 作残差分析图。
( 3 ) rstool(x,y) 一种交互式方式的句柄命令。
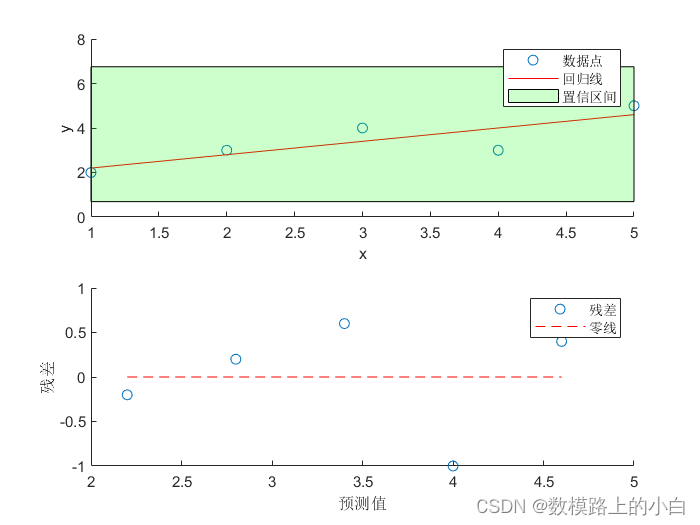
例:现有多个样本的因变量和自变量的数据,下面我们利用 Matlab ,通过回归分析建立两者之间的回归方程。
//一元线性回归分析
% 输入数据
x = [1, 2, 3, 4, 5]; % 自变量
y = [2, 3, 4, 3, 5]; % 因变量
% 计算回归系数
n = length(x); % 数据点个数
xy = x .* y;
xx = x .* x;
b1 = (n * sum(xy) - sum(x) * sum(y)) / (n * sum(xx) - sum(x)^2);
b0 = mean(y) - b1 * mean(x);
% 计算预测值和残差
y_pred = b0 + b1 * x; % 预测值
residuals = y - y_pred; % 残差
% 计算置信区间
X = [ones(n, 1), x'];
[~, ~, ~, ~, stats] = regress(y', X); % 使用regress函数计算置信区间
CI = stats(1:2); % 置信区间上界和下界
% 绘制数据点、回归线和置信区间
subplot(2,1,1);
scatter(x, y); % 绘制散点图
hold on;
plot(x, y_pred, 'r'); % 绘制回归线
fill([min(x), max(x), max(x), min(x)], [CI(1), CI(1), CI(2), CI(2)], 'g', 'FaceAlpha', 0.2); % 填充置信区间
xlabel('x');
ylabel('y');
legend('数据点', '回归线', '置信区间');
% 绘制残差图
subplot(2,1,2);
scatter(y_pred, residuals); % 绘制残差图
hold on;
plot([min(y_pred), max(y_pred)], [0, 0], 'r--'); % 绘制零线
xlabel('预测值');
ylabel('残差');
legend('残差', '零线');
% 输出回归系数和置信区间
disp(['回归系数 b0 = ', num2str(b0)]);
disp(['回归系数 b1 = ', num2str(b1)]);
disp(['置信区间 = [', num2str(CI(1)), ', ', num2str(CI(2)), ']']);
其输出结果为:
//输出结果
回归系数 b0 = 1.6
回归系数 b1 = 0.6
置信区间 = [0.69231, 6.75]
多元回归分析
x1=[5.5 2.5 8 3 3 2.9 8 9 4 6.5 5.5 5 6 5 3.5 8 6 4 7.5 7]';
x2=[31 55 67 50 38 71 30 56 42 73 60 44 50 39 55 70 40 50 62 59]';
x3=[10 8 12 7 8 12 12 5 8 5 11 12 6 10 10 6 11 11 9 9]';
x4=[8 6 9 16 15 17 8 10 4 16 7 12 6 4 4 14 6 8 13 11]';
% 输入因变量数据
y=[79.3 200.1 163.1 200.1 146.0 177.7 30.9 291.9 160 339.4 159.6 86.3 237.5 107.2 155 201.4 100.2 135.8 223.3 195]';
X=[ones(size(x1)),x1,x2,x3,x4];
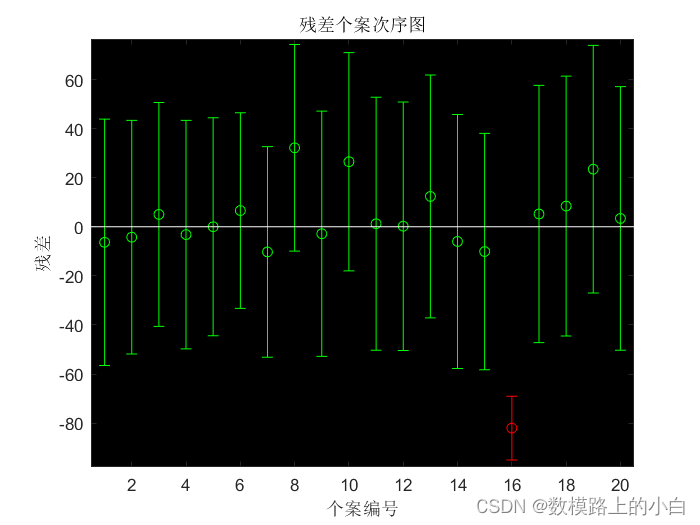
[b,bint,r,rint,stats]=regress(y,X)% 回归分析
Q=r'*r
sigma=Q/18
rcoplot(r,rint);
结果为:
回归系数 b0 = 1.6
回归系数 b1 = 0.6
置信区间 = [0.69231, 6.75]
>> untitled
b =
191.9906
-0.7751
3.1718
-19.6849
-0.4494
bint =
103.1866 280.7946
-7.1474 5.5972
2.0634 4.2802
-25.1686 -14.2012
-3.7276 2.8288
r =
-6.3088
-4.2260
5.0635
-3.1701
0.0269
6.6185
-10.2294
32.1836
-2.8287
26.5217
1.2446
0.2377
12.3762
-5.9684
-10.0799
-82.0142
5.2187
8.4492
23.4779
3.4069
rint =
-56.5100 43.8924
-51.7978 43.3459
-40.5391 50.6662
-49.7192 43.3789
-44.3792 44.4331
-33.2139 46.4509
-53.1383 32.6796
-9.9179 74.2851
-52.7738 47.1163
-17.9441 70.9875
-50.2831 52.7722
-50.3838 50.8593
-37.1054 61.8578
-57.6997 45.7628
-58.2285 38.0687
-94.9997 -69.0286
-47.1632 57.6005
-44.4731 61.3716
-26.9733 73.9292
-50.3016 57.1154
stats =
0.9034 35.0555 0.0000 644.5831
Q =
9.6687e+03
sigma =
537.1526
逐步回归
X1=[x1,x2,x3,x4];
stepwise(X1,y,[1,2,3])% 逐步回归
% X2=[ones(size(x1)),x2,x3];
% X3=[ones(size(x1)),x1,x2,x3];
% X4=[ones(size(x1)),x2,x3,x4];
% [b1,b1int,r1,r1int,stats1]=regress(y,X2)
% [b2,b2int,r2,r2int,stats2]=regress(y,X3);
% [b3,b3int,r3,r3int,stats3]=regress(y,X4);
机理分析
- 机理方法概述
(1)自身存在的发展规律和理由–分析事物的内在因素,研究其内在关系,得到内在规律—机理模型。
(2)如何从事物的内在因素和条件中研究其内在关系与规律??------机理分析建模方法。
(3)利用机理分析方法所建立的模型有:代数方程、函数方程、微分方程、积分方程和一般的动力学模型等。
一般不能直接应用某种现成的方法得到模型,或直接套用现成的模型得到结论。 - 机理建模的基本方法
类比分析法:根据一些物理定律,经济规律,数学原理等建立不同事物之间的类比关系,建立问题的数学模型。
量纲分析法:通过分析问题相关物理量的量纲,根据量纲一致性原则建立各物理量之间的关系。
几何分析法:针对实际问题,利用平面几何、立体几何、解析几何的原理等建立模型。
逻辑分析法:一句问题的客观条件和实际情况,利用逻辑推理和逻辑运算建立模型
比较分析法:对照各个事物,确定事务间的共同点和差异点,通过文字描述、图表等方式对事物特征进行分析,建立模型。
推理分析法:在掌握一定的已知事实,数据信息或者因素相关性的基础上,通过因果关系或其他相关关系顺次,逐步地推论得出新结论,建立模型。 - 机理分析建模流程
针对实际问题-----了解问题背景----分析问题-----明确相关因素和参数-----分析其内在关系—用适当数学方法—建立关联模型–选用实际数据–确定未知数据—求解模型—用结果解释实际问题—用实际数据或模拟检验模型—进一步扩展模型。
例:人才吸引力评价(2018深圳杯A题)—中国大学生在线可看此论文
将定性分析转换成定量分析,比如:发展前景、经济收入、社会环境
问题的关键:首先搞清楚:什么是人才吸引力?水平如何?优势与不足?如何提升?
(1)柯布–道格拉斯函数
人才吸引力:发展前景、经济收入、社会环境
发展前景:历史数据、当前数据
经济收入:人均收入、物价水平
社会环境:空气环境指数、
(2)万有引力定律
(3)类欧姆定律
例:出租车模型
(1)建立合理性模型,并分析不同时空出租车资源的供求匹配程度。
(2)分析相关公司的出租车补贴方案是否对缓解打车难问题有帮助?
(3)试创建一个打车软件服务平台,计一个补贴方案,并论证其合理性
深圳杯的题目----深圳一天的数据 都可以查到
关系的问题===核心问题
基例—情景—数据
1.目前出租车资源的配置是否合理?
2.如何实现出租车供求关系的良好匹配?
3.打车软件是否能有效解决打车难问题?
解决问题:分析与出租车供求相关的因素和关系机理,建立问题的机理模型。
需要收集某区域或城市出租车的相关数据,通过对数据的分析研究,统计挖掘出相关规律,来支持所建立的数学哦行和模型的结论。
出租车运行轨迹数据----------------不需要
优秀论文:-----------中国大学生在线可看到
(1)匹配指标如何建立?出租车里程利用率和供求比率的经验公式
(2)某城市的滴滴数据补贴的前后数据分析,客观形成好单和坏单要分阶段进行讨论考虑,而不是单单说有利还是无利。
通过机理分析建立分区动态实时补贴模型,给出符合实际的补贴方案:针对司机和乘客不同的设计。
在各区各时段的补贴保持平衡的前提下,建立平衡补贴的方程组模型。
排队方法
这个就直接上代码了。
//排队论
% /M/PH/1(k);
% p=stationary_prob(4,beta,S,order,lambda);
function [p,p_minus,p_add,mean,time]=stationary_prob(k,beta,S,lambda) order=length(beta);
e=ones(order,1);
R=lambda*inv(lambda*eye(size(S))-lambda*e*beta-S);
R_k=eye(size(S));
for i=1:k
R_k = R_k+R^i;
end
p0=inv(beta*(R_k-lambda*R^k*inv(S))*e);
p_t=p0;
for i=1:k
p_t=[p_t,p0*beta*R^i];
end
p_t=[p_t,p0*beta*(R^k)*(-lambda*inv(S))];
% the queue length distribution in any time
% add every phase in the same level
p=p0;
for i=1:k+1
sum=0;
for j=1:order
sum =sum+p_t(1+(i-1)*order+j);
end
p=[p,sum];
end
p_minus = p;
% the queue length distribution at departure
% p_add = p_minus(i)/(1-p_minus(k+1))
p_add=[0];
for i=0:k
p_add=[p(k-i+1)/(1-p(k+2)),p_add];
end
% the mean queue length
mean=0;
for i=1:k
mean =mean+i*p(i+1);
end
层次分析法(AHP)
基本步骤:
1.建立层次分析结构模型。常见的有目标层-准则层-方案层模型。
2.构造成对比较矩阵。常用的有1-9尺度。尺度大小取决于下层的元素个数。
3.计算权向量并作一致性检验。引入一致性指标CI,CI越大,不一致越严重。引入随机一致性指标RI。定义一致性比率CR=CI/RI。CR<0.1时,通过一致性检验。
4.计算组合权向量作组合一致性检验,组合权向量可作为决策的定量依据。方案层对目标层的组合权向量为ww*w。选择组合权向量大的元素作为输出结果。
注意,该方法具有较强的主观性
//AHP代码
clc
a=[1,1,1,4,1,1/2
1,1,2,4,1,1/2
1,1/2,1,5,3,1/2
1/4,1/4,1/5,1,1/3,1/3
1,1,1/3,3,1,1
2,2,2,3,3,1];%一致矩阵
[x,y]=eig(a);eigenvalue=diag(y);lamda=max(eigenvalue);
ci1=(lamda-6)/5;cr1=ci1/1.24
w1=x(:,1)/sum(x(:,1))
b1=[1,1/4,1/2;4,1,3;2,1/3,1];
[x,y]=eig(b1);eigenvalue=diag(y);lamda=eigenvalue(1);
ci21=(lamda-3)/2;cr21=ci21/0.58
w21=x(:,1)/sum(x(:,1))
b2=[1 1/4 1/5;4 1 1/2;5 2 1];
[x,y]=eig(b2);eigenvalue=diag(y);lamda=eigenvalue(1);
ci22=(lamda-3)/2;cr22=ci22/0.58
w22=x(:,1)/sum(x(:,1))
b3=[1 3 1/3;1/3 1 1/7;3 7 1];
[x,y]=eig(b3);eigenvalue=diag(y);lamda=eigenvalue(1);
ci23=(lamda-3)/2;cr23=ci23/0.58
w23=x(:,1)/sum(x(:,1))
b4=[1 1/3 5;3 1 7;1/5 1/7 1];
[x,y]=eig(b4);eigenvalue=diag(y);lamda=eigenvalue(1);
ci24=(lamda-3)/2;cr24=ci24/0.58
w24=x(:,1)/sum(x(:,1))
b5=[1 1 7;1 1 7;1/7 1/7 1];
[x,y]=eig(b5);eigenvalue=diag(y);lamda=eigenvalue(1);
ci25=(lamda-3)/2;cr25=ci25/0.58
w25=x(:,1)/sum(x(:,1))
b6=[1 7 9;1/7 1 1 ;1/9 1 1];
[x,y]=eig(b6);eigenvalue=diag(y);lamda=eigenvalue(1);
ci26=(lamda-3)/2;cr26=ci26/0.58
w26=x(:,1)/sum(x(:,1))
w_sum=[w21,w22,w23,w24,w25,w26]*w1
ci=[ci21,ci22,ci23,ci24,ci25,ci26];
cr=ci*w1/sum(0.58*w1)
结果为:
cr1 =
0.0996
w1 =
0.1507
0.1792
0.1886
0.0472
0.1464
0.2879
cr21 =
0.0158
w21 =
0.1365
0.6250
0.2385
cr22 =
0.0212
w22 =
0.0974
0.3331
0.5695
cr23 =
0.0061
w23 =
0.2426
0.0879
0.6694
cr24 =
0.0559
w24 =
0.2790
0.6491
0.0719
cr25 =
-3.8284e-16
w25 =
0.4667
0.4667
0.0667
cr26 =
0.0061
w26 =
0.7986
0.1049
0.0965
w_sum =
0.3952
0.2996
0.3052
cr =
0.0117
主成分分析法
主成分分析法是利用降维的思想,把多指标转化为少数几个综合指标(即主成分),其中每个主成分都能够反映原始变量的大部分信息,且所含信息互不重复。这种方法在引进多方面变量的同时将复杂因素归结为几个主成分,使问题简单化,同时得到的结果更加科学有效的数据信息。
例如,做一件上衣需要测量很多尺寸,如身高,袖长,腰围,胸围,肩宽等十几项指标,但是厂家不可能把尺寸型号分这么多,而是从这十几种指标中综合成几个少数的综合指标作为分类型号,例如综合成反映身高,反映胖瘦和反应特体的三项指标,这就是主成分的思想。主要的方法有特征值分解,SVD(奇异值分解)和NMF(非负矩阵分解);
原始指标数据的标准化采集p维随机向量
x
=
(
X
i
1
,
X
i
2
,
⋯
,
X
i
p
)
T
x=(X_{i1},X_{i2},\cdots,X_{ip})^{T}
x=(Xi1,Xi2,⋯,Xip)Tn个样品
x
i
=
(
x
i
1
,
x
i
2
,
⋯
,
x
i
p
T
)
x_{i}=(x_{i1},x_{i2},\cdots,x_{ip}^{T})
xi=(xi1,xi2,⋯,xipT),i=1,2,…n,n>p,构造样本阵,对样本阵元进行如下变化标准化变换:
Z
i
j
=
x
i
j
−
x
‾
j
s
j
,
i
=
1
,
2
,
⋯
,
n
;
j
=
1
,
2
,
⋯
,
p
Z_{ij}=\frac{x_{ij}-\overline{x}_{j}}{s_{j}},i=1,2,\cdots,n;j=1,2,\cdots,p
Zij=sjxij−xj,i=1,2,⋯,n;j=1,2,⋯,p
其中
x
‾
j
=
∑
i
=
1
n
x
i
j
n
,
s
j
2
=
∑
i
=
1
n
(
x
i
j
−
x
‾
j
)
2
n
−
1
\overline{x}_{j}=\frac{\sum_{i=1}^{n}x_{ij}}{n},s_{j}^{2}=\frac{\sum_{i=1}^{n}(x_{ij}-\overline{x}_{j})^{2}}{n-1}
xj=n∑i=1nxij,sj2=n−1∑i=1n(xij−xj)2得标准化阵Z。
2、对标准化阵Z求相关系数矩阵
R
=
[
r
i
j
]
p
x
p
=
Z
T
Z
n
−
1
R=[r_{ij}]_{p}xp=\frac{Z^{T}Z}{n-1}
R=[rij]pxp=n−1ZTZ
其中,
r
i
j
=
∑
z
k
j
⋅
z
k
j
n
−
1
,
i
,
j
=
1
,
2
,
⋯
,
p
r_{ij}=\frac{\sum{z_{kj}·z_{kj}}}{n-1},i,j=1,2,\cdots,p
rij=n−1∑zkj⋅zkj,i,j=1,2,⋯,p
3、解样本相关矩阵R的特征方程
∣
R
−
λ
I
p
∣
=
0
|R-\lambda{I_{p}}|=0
∣R−λIp∣=0得出p个特征根,确定主成分满足
∑
j
=
1
m
λ
j
∑
j
=
1
p
λ
j
≥
0.85
\frac{\sum_{j=1}^{m}\lambda_{j}}{\sum_{j=1}^{p}\lambda_{j}}\ge0.85
∑j=1pλj∑j=1mλj≥0.85确定m的值,使信息的利用率达85%以上,对每个
λ
j
,
j
=
1
,
2
,
⋯
,
m
\lambda_{j},j=1,2,\cdots,m
λj,j=1,2,⋯,m,解方程组
R
b
=
λ
j
b
Rb=\lambda_{j}b
Rb=λjb得单位特征向量
b
j
a
b_{j}^{a}
bja。
4、将标准化后的指标变量转化为主成分
U
i
j
=
z
i
T
b
j
a
,
j
=
1
,
2
,
⋯
,
m
U_{ij}=z_{i}^{T}b_{j}^{a},j=1,2,\cdots,m
Uij=ziTbja,j=1,2,⋯,m
U
1
U_{1}
U1称为第一主成分,
U
2
U_{2}
U2称为第二主成分,
⋯
\cdots
⋯,
U
p
U_{p}
Up称为第p主成分。
5、对m个主成分进行综合评价
对m个主成分进行加权求和,即得最终评价值,权数为每个主成分的方差贡献率。
以下为MATLAB代码:
/主成分分析法
x=[1.2,3,-1.1,17;
1.5,5,-3,22;
1.3,4.0,-2,19;
0.7,3,-2.3,11
1,4,-1.2,20.8];
stdr=std(x); %求各变量的标准差;
[n,m]=size(x); %矩阵的行与列
sddata=x./stdr(ones(n,1),:); %标准化变换
[p,princ,egenvalue]=princomp(sddata); %调用主成分
p=p(:,1:3); %输出前3主成分系
sc=princ(:,1:3); %前3主成分量;
egenvalue; %相关系数矩阵的特征值,即各主成分所占比例;
per=100*egenvalue/sum(egenvalue); %各个主成分所占百分比;
输出结果为:
| 成分 | Value |
|---|---|
| 1 | 68.2742 |
| 2 | 25.1274 |
| 3 | 6.5776 |
| 4 | 0.0208 |
















 8185
8185











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











