







参考视频:https://www.bilibili.com/video/BV1zS4y1n7Eq/spm_id_from=333.999.0.0&vd_source=98d31d5c9db8c0021988f2c2c25a9620
前言
- 人工智能:多领域交叉科学技术。
- 机器学习:计算机智能决策算法。
- 深度学习:高效的机器学习算法。
pytorch实现模型训练
- 数据
- 如何把数据从硬盘读到内存?
- 如何组织数据进行训练?图片如何预处理及数据增强?
- 模型
- 如何构建模型模块?如何组织复杂网络?
- 如何初始化网络参数?如何定义网络层?
- 损失函数
- 如何创建损失函数?如何设置损失函数超参数?
- 如何选择损失函数?
- 优化器
- 如何管理模型参数?如何管理多个参数组实现不同学习率?
- 如何调整学习率。
- 迭代学习
- 如何观察训练效果?如何绘制Loss/Accuray曲线?
- 如何用TensorBoard分析?
- 模型应用
- 如何进行图像分类 ?图像分割?
- 目标检测?对抗生成?循环网络?
Tensor
张量其本质就是一个多维数组。
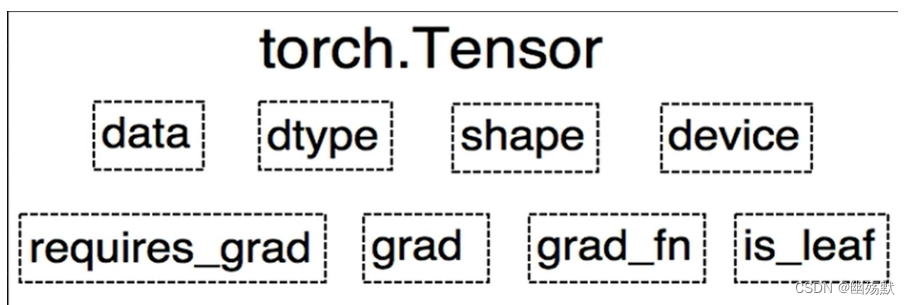
上图是torch.tensor的八个属性。
-
data: 就是张量的值。
-
dtype: 张量的数据类型。
-
shape: 张量的形状。
-
device: 张量所在设备 CPU/GPU。
-
requires_grad:一个布尔值,指示张量是否需要梯度计算。
-
grad:张量的梯度,如果requires_grad为True并且进行了反向传播计算,则该属性存储相对于张量的梯度值。
-
grad_fn:创建张量的函数,用于跟踪梯度的计算历史。
张量的创建:
-
torch.tensor() -
torch.from_numpy(ndarray)- 从
numpy创建tensor,这俩是共享内存的,一个改都改。
- 从
-
torch.zeros() -
torch.ones() -
torch.full()torch.full((3,3),2)创建一个3x3的张量其值全为2。
-
torch.eye()创建单位对角矩阵。 -
torch.normul()生成正态分布。 -
torch.randn()生成标准正态分布。 -
torch.rand()在[0,1)生成均匀分布。
张量的拼接:
torch.cat()将张量按照dim维度进行拼接。torch.stack()在新创建的维度dim进行拼接。
张量的切分:
torch.chunk()将张量按维度dim进行平均切分。- 若不能整除,最后一份张量小于其他张量。
torch.split()将张量按维度dim进行切分,可以指定每一份的大小。
张量的索引:
torch.index_select():在维度dim上按index索引数据。torch.masked_select():按mask中的True进行索引。
张量变换:
-
torch.reshape():变换张量形状。 -
torch.transpose():交换张量的两个维度。 -
torch.t():二维张量转置。 -
torch.squeeze():压缩长度为1的维度 -
torch.unsqueeze():依据dim扩展维度
写一个简单的线性回归模型
import matplotlib
matplotlib.use('TkAgg') # 选择一个合适的后端,比如Agg
import matplotlib.pyplot as plt
import torch
import time
torch.manual_seed(10)
lr = 0.01 # 学习率
# 创建训练数据
x = torch.rand(20, 1) * 10
y = 2 * x + (5 + torch.randn(20, 1))
# 构建线性回归参数
w = torch.randn((1), requires_grad=True)
b = torch.randn((1), requires_grad=True)
for iteration in range(2000):
# 前向传播
wx = torch.mul(w, x)
y_pred = torch.add(wx, b)
# 计算MSE loss
loss = (0.5 * (y - y_pred)**2).mean()
# 反向传播
loss.backward()
# 更新参数
b.data.sub_(lr * b.grad)
w.data.sub_(lr * w.grad)
# 清除梯度
b.grad.zero_()
w.grad.zero_()
# 绘图
if iteration % 20 == 0:
plt.clf()
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), y_pred.data.numpy(), 'r-', lw=5)
plt.text(2, 20, ':Loss=%.4f' % loss.data.numpy(), fontdict={'size': 20, 'color': 'red'})
plt.xlim(1.5, 10)
plt.ylim(8, 28)
plt.title("Iteration: {} Loss: {:.4f}".format(iteration, loss.data.numpy()))
plt.draw()
plt.pause(0.1)
if loss.data.numpy() < 0.5:
break
plt.show()
autograd
torch.autograd.backward
- 功能:自动求取梯度。
- tensors: 用于求导的张量,如loss。
- retain_graph:用于保存计算图。
- create_graph:创建导数计算图,用于高阶求导。
- grad_tensors:多梯度权重。
torch.autograd.grad
- 功能:求取梯度。
- outputs:用于求导的张量,如loss。
- inputs: 需要梯度的张量。
- create_graph:创建导数计算图,用于高阶求导。
- retain_graph:保存计算图。
- grad_outputs:多梯度权重。
需要注意的点:
- 1、梯度不自动清零。
- 2、依赖于叶子结点的结点,requires_graid默认为True。
- 3、叶子结点不可执行in-place。
逻辑回归
逻辑回归是线性的二分类模型。

import torch
import torch.nn as nn
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
matplotlib.use('TkAgg') # 设置后端为TkAgg或其他可用的后端
torch.manual_seed(256)
##########################生成数据###################################
sample_nums=100
mean_value=1.7
bias=1
n_data=torch.ones(sample_nums,2)
x0=torch.normal(mean_value*n_data,1)+bias#数据(100,2)
y0=torch.zeros(sample_nums)#标签(100,1)
x1=torch.normal(-mean_value*n_data,1)+bias#数据(100,2)
y1=torch.ones(sample_nums)#标签(100,1)
train_x=torch.cat((x0,x1),0)#(200,2)
train_y=torch.cat((y0,y1),0)#(200,1)
###################################################################
##############################模型####################################
class LR(nn.Module):
def __init__(self):
super(LR, self).__init__()
self.features=nn.Linear(2,1)
self.sigmoid=nn.Sigmoid()
def forward(self,x):
x=self.features(x)
x=self.sigmoid(x)
return x
lr_net=LR()#实例化模型
#####################################################################
##############################损失函数##########################################
loss_fn=nn.BCELoss()
###############################优化器###########################################
lr=0.001 #学习率
optimizer=torch.optim.SGD(lr_net.parameters(),lr=lr,momentum=0.9)
#######################################模型训练########################################
for iteration in range(1000):
#前向传播
y_pred=lr_net(train_x)
#计算损失
loss=loss_fn(y_pred.squeeze(),train_y)
#反向传播
loss.backward()
#更新参数
optimizer.step()
#绘图
if iteration % 20 ==0:
mask=y_pred.ge(0.5).float().squeeze() #以0.5的阈值进行分类
correct=(mask==train_y).sum()#计算正确样本的个数。
acc=correct.item()/train_y.size(0) #计算准确率
plt.scatter(x0.data.numpy()[:,0],x0.data.numpy()[:,1],c='r',label='class 0')
plt.scatter(x1.data.numpy()[:, 0], x1.data.numpy()[:, 1], c = 'b', label = 'class 1')
w0,w1=lr_net.features.weight[0]
w0,w1=float(w0.item()),float(w1.item())
plot_b=float(lr_net.features.bias[0].item())
plot_x=np.arange(-6,6,0.1)
plot_y=(-w0*plot_x-plot_b)/w1
plt.xlim(-5,7)
plt.ylim(-7,7)
plt.plot(plot_x,plot_y)
plt.text(-5,5,'Loss=%.4f' % loss.data.numpy(),fontdict={'size':20,'color':'red'})
plt.title("Iteration: {}\nw0:{:.2f} w1:{:.2f} b: {:.2f} accuracy:{:.2%}".format(iteration,w0,w1,plot_b,acc))
plt.legend()
plt.show()
plt.pause(0.5)
if acc>0.99:
break














 3536
3536











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









