







前面几篇文章都只是对Scrapy框架的一个初步了解,这篇文章中我打算稍微深入Scrapy框架中,通过下载保存美女图片的例子,去探究下Spider Middleware的相关知识。
一,Scrapy架构概览
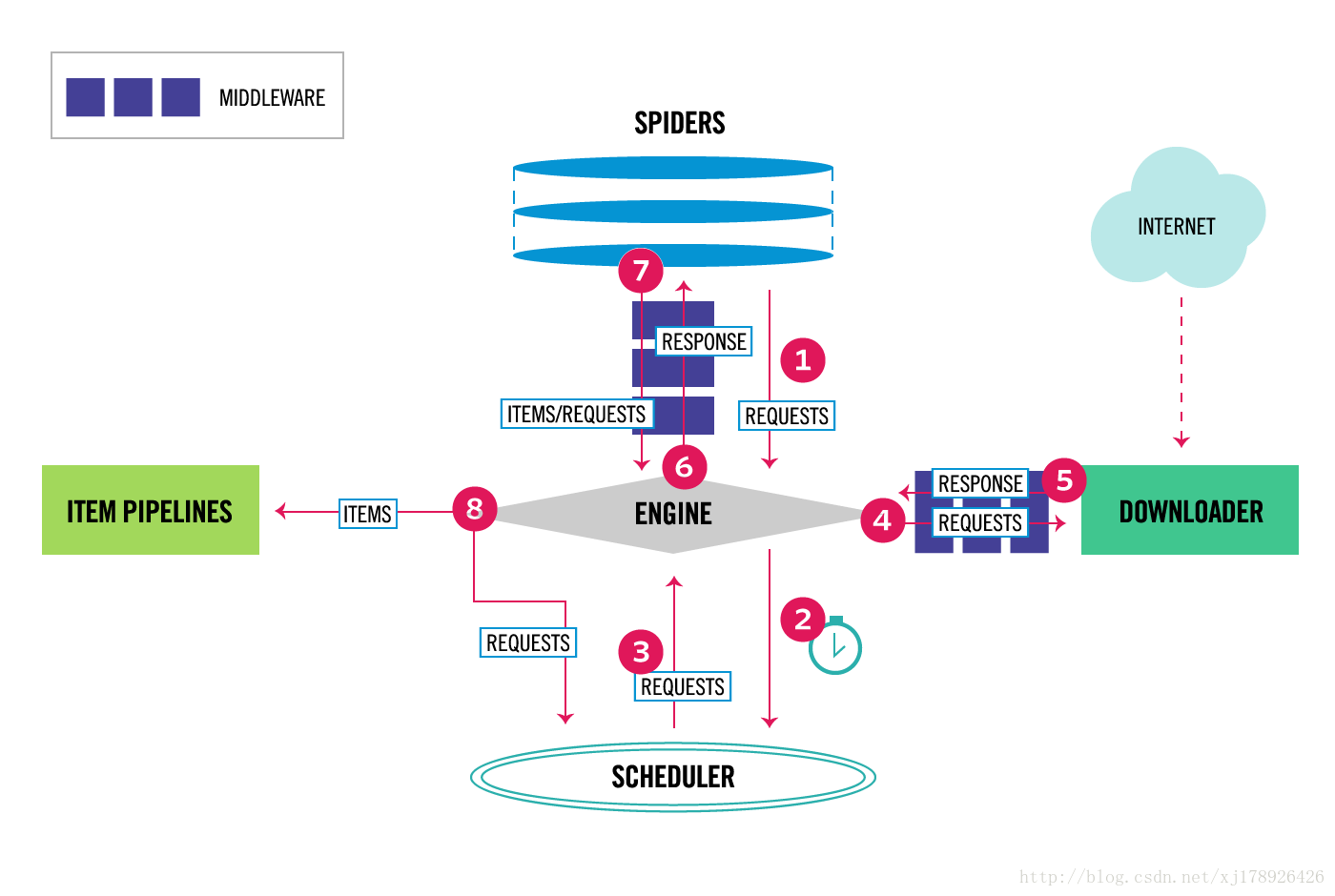
要探究清楚Spider Middleware,首先得对Scrapy框架的整体架构有个大致的认识,如下图所示:
1,组件(Components)
Scrapy 引擎(Engine)
引擎负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。 详细内容查看下面的数据流(Data Flow)部分。
调度器(Scheduler)
调度器从引擎接受request并将他们入队,以便之后引擎请求他们时提供给引擎。
下载器(Downloader)
下载器负责获取页面数据并提供给引擎,而后提供给spider。
Spiders
Spider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站,我们前面几篇文章中,通过Scrapy框架实现的爬虫例子都是在Spiders这个组件中实现。 更多内容请看 Spiders 。
管道(Item Pipeline)
Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数据库中)。 更多内容查看 Item Pipeline 。
下载器中间件(Downloader Middlewares)
下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。更多内容请看 Downloader Middleware 。
Spider中间件(Spider Middlewares)
Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。更多内容请看 Spider Middleware 。
2,数据流(Data flow)
Scrapy中的数据流由执行引擎控制,其过程如下:
1,引擎从Spiders中获取到最初的要爬取的请求(Requests)。
2,引擎安排请求(Requests)到调度器中,并向调度器请求下一个要爬取的请求(Requests)。
3,调度器返回下一个要爬取的请求(Requests)给引擎。
4,引擎将上步中得到的请求(Requests)通过下载器中间件(Downloader Middlewares)发送给下载器(Downloader ),这个过程中下载器中间件(Downloader Middlewares)中的process_request()函数会被调用到。
5,一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(Downloader Middlewares)发送给引擎,这个过程中下载器中间件(Downloader Middlewares)中的process_response()函数会被调用到。
6,引擎从下载器中得到上步中的Response并通过Spider中间件(Spider Middlewares)发送给Spider处理,这个过程中Spider中间件(Spider Middlewares)中的process_spider_input()函数会被调用到。
7,Spider处理Response并通过Spider中间件(Spider Middlewares)返回爬取到的Item及(跟进的)新的Request给引擎,这个过程中Spider中间件(Spider Middlewares)的process_spider_output()函数会被调用到。
8,引擎将上步中Spider处理的其爬取到的Item给Item 管道(Pipeline),将Spider处理的Request发送给调度器,并向调度器请求可能存在的下一个要爬取的请求(Requests)。
9,(从第二步)重复直到调度器中没有更多的请求(Requests)。
二,Spider中间件(Spider Middlewares)
Spider中间件是介入到Scrapy中的spider处理机制的钩子框架,可以插入自定义功能来处理发送给 Spiders 的response,以及spider产生的item和request。
1,激活Spider中间件(Spider Middlewares)
要启用Spider中间件(Spider Middlewares),可以将其加入到 SPIDER_MIDDLEWARES 设置中。 该设置是一个字典,键为中间件的路径,值为中间件的顺序(order)。
样例:
- 1
- 2
- 3
- 1
- 2
- 3
SPIDER_MIDDLEWARES 设置会与Scrapy定义的 SPIDER_MIDDLEWARES_BASE 设置合并(但不是覆盖), 而后根据顺序(order)进行排序,最后得到启用中间件的有序列表: 第一个中间件是最靠近引擎的,最后一个中间件是最靠近spider的。
关于如何分配中间件的顺序请查看 SPIDER_MIDDLEWARES_BASE 设置,而后根据您想要放置中间件的位置选择一个值。 由于每个中间件执行不同的动作,您的中间件可能会依赖于之前(或者之后)执行的中间件,因此顺序是很重要的。
如果您想禁止内置的(在 SPIDER_MIDDLEWARES_BASE 中设置并默认启用的)中间件, 您必须在项目的 SPIDER_MIDDLEWARES设置中定义该中间件,并将其值赋为 None 。 例如,如果您想要关闭off-site中间件:
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
最后,请注意,有些中间件需要通过特定的设置来启用。更多内容请查看相关中间件文档。
2,编写自己的spider中间件
编写spider中间件十分简单。每个中间件组件是一个定义了以下一个或多个方法的Python类:
class scrapy.contrib.spidermiddleware.SpiderMiddleware
process_spider_input(response, spider)
当response通过spider中间件时,该方法被调用,处理该response。
process_spider_input() 应该返回 None 或者抛出一个异常(exception)。
如果其返回 None ,Scrapy将会继续处理该response,调用所有其他的中间件直到spider处理该response。
如果其抛出一个异常(exception),Scrapy将不会调用任何其他中间件的 process_spider_input() 方法,并调用request的errback。 errback的输出将会以另一个方向被重新输入到中间件链中,使用 process_spider_output() 方法来处理,当其抛出异常时则带调用process_spider_exception() 。
参数:
response (Response 对象) – 被处理的response
spider (Spider 对象) – 该response对应的spider
process_spider_output(response, result, spider)
当Spider处理response返回result时,该方法被调用。
process_spider_output() 必须返回包含 Request 或 Item 对象的可迭代对象(iterable)。
参数:
response (Response 对象) – 生成该输出的response
result (包含 Request 或 Item 对象的可迭代对象(iterable)) – spider返回的result
spider (Spider 对象) – 其结果被处理的spider
process_spider_exception(response, exception, spider)
当spider或(其他spider中间件的) process_spider_input() 抛出异常时, 该方法被调用。
process_spider_exception() 必须要么返回 None , 要么返回一个包含 Response 或 Item 对象的可迭代对象(iterable)。
如果其返回 None ,Scrapy将继续处理该异常,调用中间件链中的其他中间件的 process_spider_exception() 方法,直到所有中间件都被调用,该异常到达引擎(异常将被记录并被忽略)。
如果其返回一个可迭代对象,则中间件链的 process_spider_output() 方法被调用, 其他的 process_spider_exception() 将不会被调用。
参数:
response (Response 对象) – 异常被抛出时被处理的response
exception (Exception 对象) – 被跑出的异常
spider (Spider 对象) – 抛出该异常的spider
process_start_requests(start_requests, spider)
0.15 新版功能.
该方法以spider 启动的request为参数被调用,执行的过程类似于 process_spider_output() ,只不过其没有相关联的response并且必须返回request(不是item)。
其接受一个可迭代的对象(start_requests 参数)且必须返回另一个包含 Request 对象的可迭代对象。
注解
当在您的spider中间件实现该方法时, 您必须返回一个可迭代对象(类似于参数start_requests)且不要遍历所有的 start_requests。 该迭代器会很大(甚至是无限),进而导致内存溢出。 Scrapy引擎在其具有能力处理start request时将会拉起request, 因此start request迭代器会变得无限,而由其他参数来停止spider( 例如时间限制或者item/page记数)。参数:
start_requests (包含 Request 的可迭代对象) – start requests
spider (Spider 对象) – start requests所属的spider
三,下载保存美女图片的例子
talking is cheap, show me the code前面说了这么多,还是让我们用一个小的例子来进行实际操作下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
这个就是我们的Spider实现代码,很简单,这里不过多解释。重点看看我们实现的3个Spider中间件代码:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
关于上面三个Spider中间件的配置如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
上面的三个Spider中间件,其实也没有做什么实际有用的功能,旨在了解Spider中间件相关的各接口函数的使用,中间件相关打印可以在日志文件中查看,感兴趣的同学可以在我的代码上自己扩展。
关于图片的下载和保存在这节就不进行深入解释,可以查询官方文档—Downloading and processing files and images。
最后通过如下命令来执行:
- 1
- 1
感兴趣的可自己去运行试试.

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









