






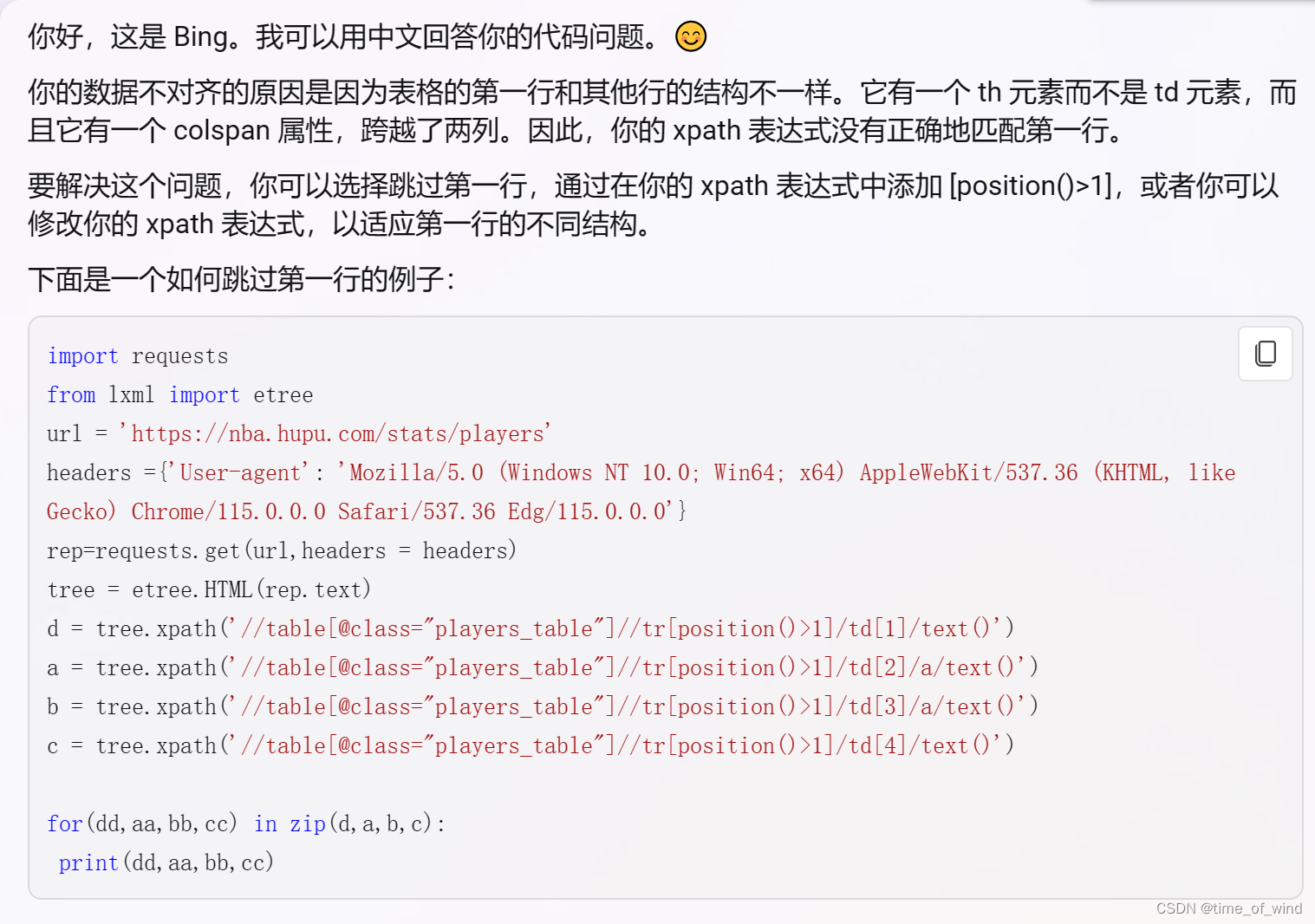
xpath
url=‘https://nba.hupu.com/stats/players’
贴一下代码
import requests
from lxml import etree
url = 'https://nba.hupu.com/stats/players'
headers ={'User-agent': ''}
rep=requests.get(url,headers = headers)
tree = etree.HTML(rep.text)
d = tree.xpath('//table[@class="players_table"]//tr[position()>1]/td[1]/text()')
a = tree.xpath('//table[@class="players_table"]//tr/td[2]/a/text()')
b = tree.xpath('//table[@class="players_table"]//tr/td[3]/a/text()')
c = tree.xpath('//table[@class="players_table"]//tr[position()>1]/td[4]/text()')
for(dd,aa,bb,cc) in zip(d,a,b,c):
print(dd,aa,bb,cc)
先声明etree,传headers,重点是xpath应用
我是看着视频做的,视频链接在这里
贴一下xpath基本用法
说一下如何复制表格,首先是要用markdown写文章把,然后嘞,用开发者工具打开光标找到要复制的表格元素全部贴过来就可以了吧~~~~~~~~~~~哈哈哈哈哈
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点 |
| / | 从当前节点选取直接子节点 |
| // | 从当前节点选取子孙节点 |
| . | 选取当前节点 |
| . . | 选取当前节点的父节点 |
| @ | 选取属性 |
| 运算符 | 描述 | 实例 | 返回值 |
|---|---|---|---|
| | | 计算两个节点集 | //book | //cd | 返回所有拥有 book 和 cd 元素的节点集 |
| + | 加法 | 6 + 4 | 10 |
| - | 减法 | 6 - 4 | 2 |
| * | 乘法 | 6 * 4 | 24 |
| div | 除法 | 8 div 4 | 2 |
| = | 等于 | price=9.80 | 如果 price 是 9.80,则返回 true。 如果 price 是 9.90,则返回 false。 |
| != | 不等于 | price!=9.80 | 如果 price 是 9.90,则返回 true。 如果 price 是 9.80,则返回 false。 |
| < | 小于 | price<9.80 | 如果 price 是 9.00,则返回 true。 如果 price 是 9.90,则返回 false。 |
| <= | 小于或等于 | price<=9.80 | 如果 price 是 9.00,则返回 true。 如果 price 是 9.90,则返回 false。 |
| > | 大于 | price>9.80 | 如果 price 是 9.90,则返回 true。 如果 price 是 9.80,则返回 false。 |
| >= | 大于或等于 | price>=9.80 | 如果 price 是 9.90,则返回 true。 如果 price 是 9.70,则返回 false。 |
| or | 或 | price=9.80 or price=9.70 | 如果 price 是 9.80, 或者 price 是 9.70,则返回 true。 |
| and | 与 | price>9.00 and price<9.90 | 如果 price 大于 9.00, 并且 price 小于9.90,则返回 true。 |
| mod | 计算除法的余数 | 5 mod 2 | 1 |
preceding following来拿到此标签后面的同级内容
在爬取的第三行第二行的内容中加上球员名称等内容,达到对应的目的
通过指定文本的形式删除
问gpt,new bing
早知道直接问了md,因为是小白半天解决不了,处处碰壁,感谢有你 new bing
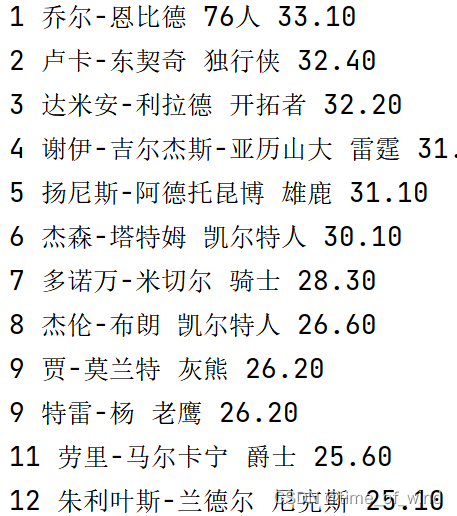
试着让他运行发现数据似乎是前几年的,这里我认为position()>1不用写在第二个第三个上,转念一想,似乎tr确实都是一样的格式,不过第二个第三个用a层级抓取,所以得到的结果没有区别,
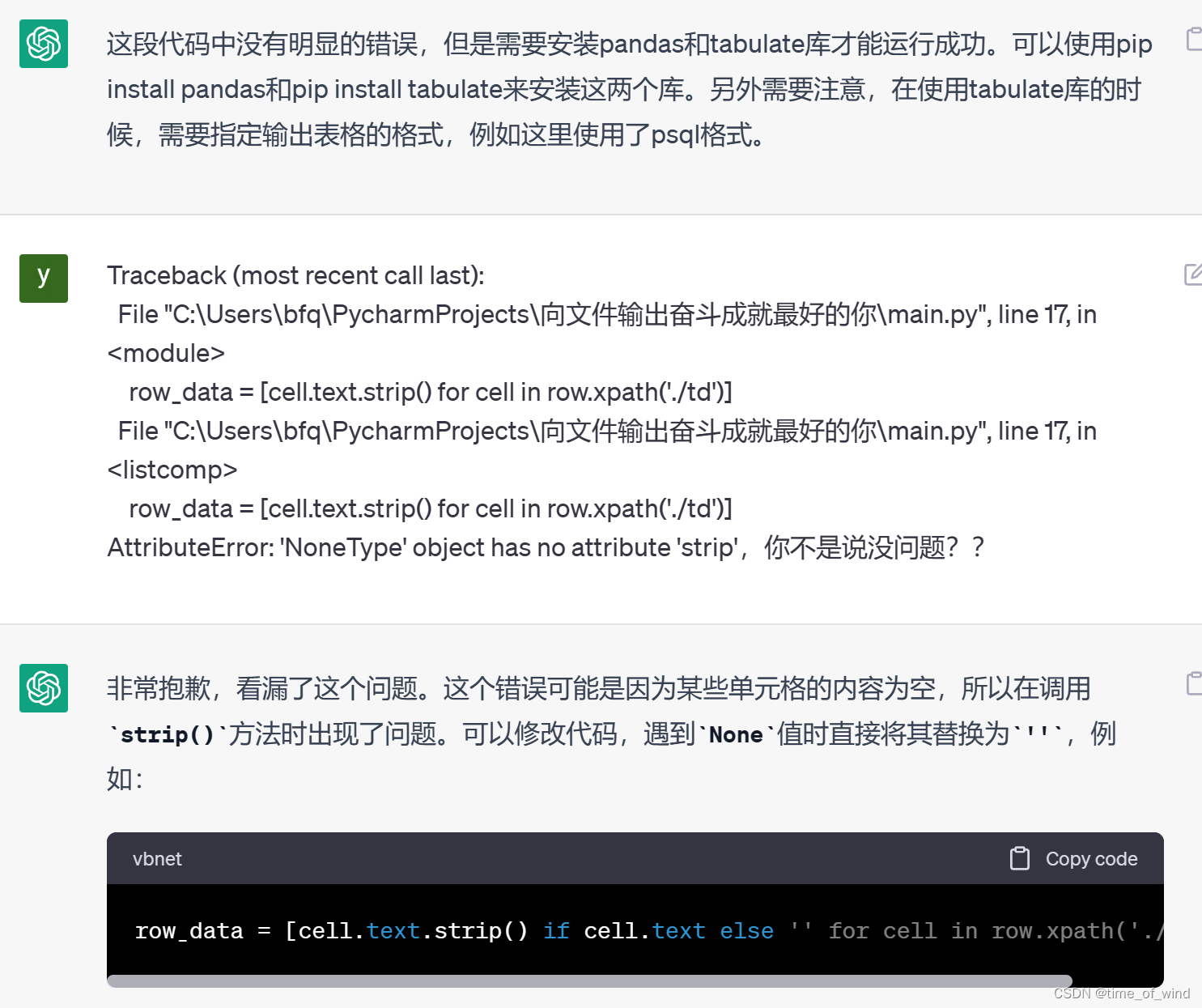
gpt3.5智商堪忧
我宣布newbing yyds















 1316
1316











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









