






「优秀不够,那就要无可替代!」
作者 | 小一

全文共2188字,阅读全文需10分钟
写在前面的话
最近更新的不是很及时了,是因为在上一篇实战写完之后,在纠结是应该继续写爬虫实战项目呢,还是写进阶的内容?
因为写实战项目,确实很好玩!
但是没有进阶,就没有进步!!
想通了之后我就又开始写了,爬虫进阶,搞起来。
而且我发现以前发文章没有规律,以后尽量就按照这个来吧!

上一篇文末的碎碎念
屁股痛是真的,不过第二天还是去上搏击操课了!
日常回顾一下,前面介绍了爬虫的基本流程和网页解析,我们对爬虫有了基本的认识。
也通过两个实战项目浅入浅出爬虫的实现流程
但是有一点不知道大家有没有注意,我们前面的两个小项目,针对的数据都是静态网页数据。
“什么是静态网页数据呢?”
普及一下相关知识:
浏览器从服务器得到的超文本标记文档的后缀通常分为两大类:
静态页面:htm、html、shtml、xml;
动态页面:asp、jsp、php、perl、cgi;
静态页面
静态网页是指存放在服务器文件系统中实实在在的HTML文件。
当用户在浏览器中输入网页的 URL 时,浏览器会下载相应的 html 文件,渲染之后呈现在窗口中。若你想要进行交互操作,对不起,当前页面不可以,请跳转到其他页面。
动态页面
动态网页是相对于静态网页而言的。
当用户在浏览器中输入网页的 URL 时,浏览器向服务器发送请求。服务器返回相应的数据动态生成HTML页面,然后在发送给浏览器(后面步骤同静态页面)。
说白了,静态网页不可以交互,看到啥就是啥;动态网页可以交互,看到的只是一部分。
来看一下我们爬豆瓣电影的页面:
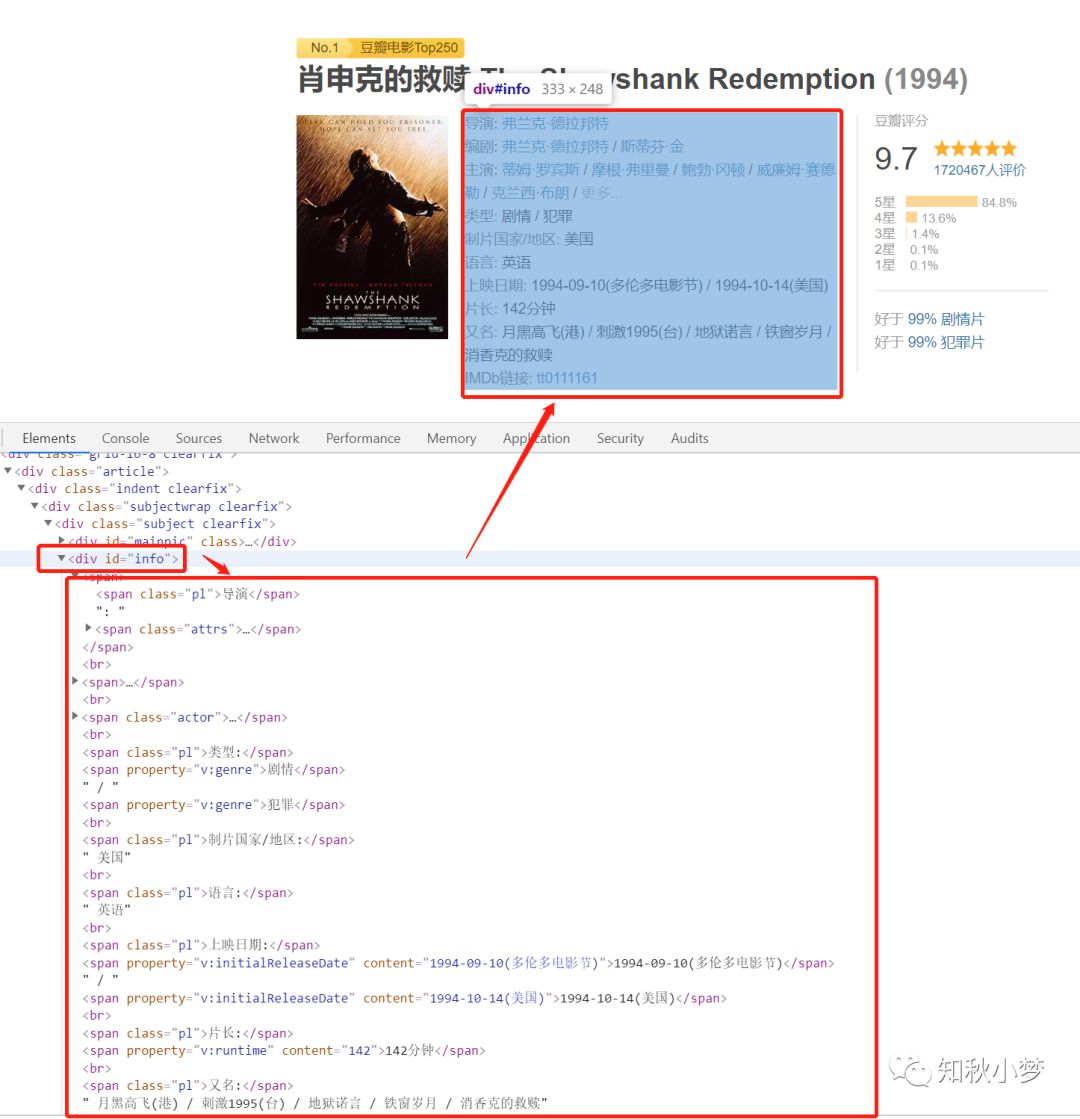
我们需要的影片数据是不会发生变化的,我称之为静态数据。
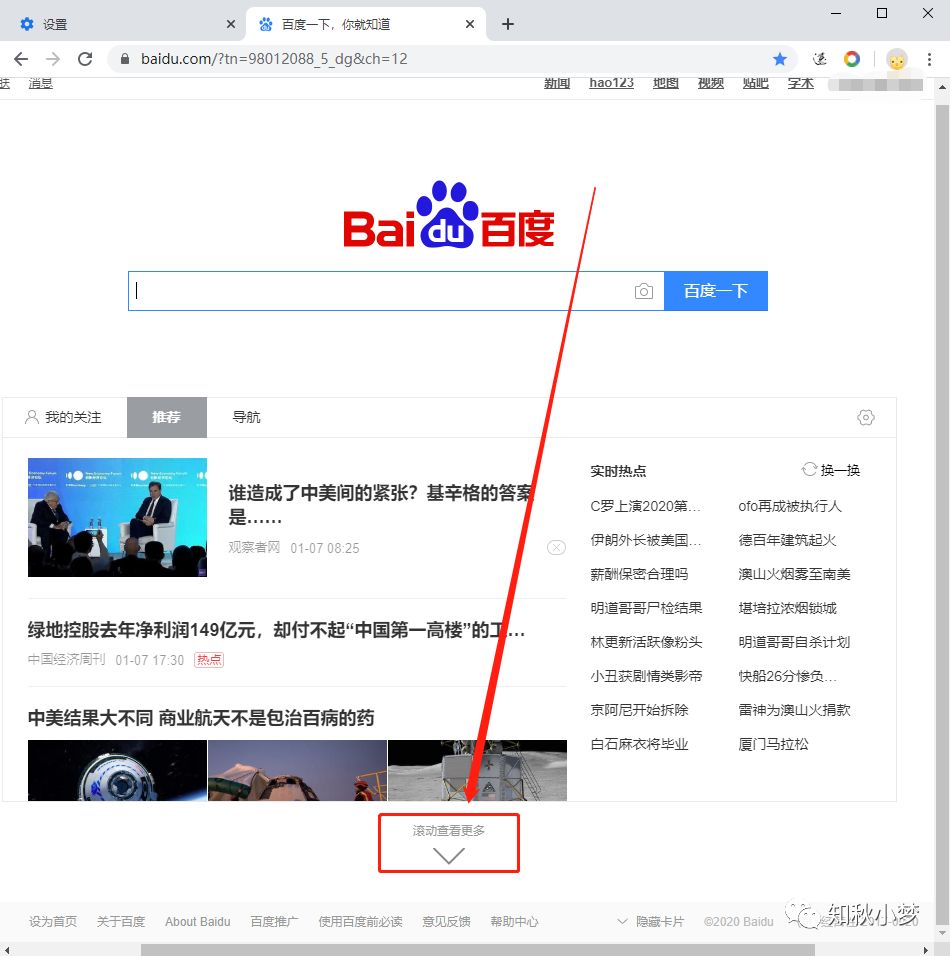
再来看百度搜索首页:

点一下会出现新的数据,但是页面并没有发生变化,我称之为动态数据。
当然,像租房爬虫中的房屋经纬度数据,我们打开网页的时候就已经拿到了。
但是数据是在 js 中放着,在页面渲染的时候才会将数据插入到网页中。
所以我们的爬虫也是无法直接拿到的。
那么,问题来了,静态的数据我们可以轻松拿到,那动态的呢?
“别担心,有我在!”
如何获取动态数据
我们已经知道,浏览器的动态页面是经过 JavaScript 处理数据后生成的结果。
这种数据可能已经在 html 页面中,可能是经过 JavaScript 计算后生成,也可能是动态交互后渲染生成的。
对于这种 JavaScript 渲染的页面数据,我们有两种方法:
分析 ajax 请求,找到相应的接口进行抓取
使用 selenium 自动化工具模拟浏览器进行抓取
“所以嘛,不要怕,你遇到的问题小一我都已经想好了对策!”
Ajax 获取动态数据
Ajax 是什么
Ajax :Asynchronous JavaScript and XML,即异步的 JavaScript 和 XML。
Ajax 技术使得页面不被全部刷新的情况下更新内容。
实际上,是通过后台与服务器交互,通过服务端返回新的数据对网页内容进行了更新。
Ajax 基本原理
从发送 Ajax 请求到网页数据更新分为三步:
发送请求
解析内容
渲染网页
发送请求:
还是这张图,我们在网页中点击下拉按钮,都相当于进行了一次请求。
这个请求会发送给服务器,但是此刻页面不会发生任何变化。
解析内容:
服务器接收到请求后,会返回一份数据。
这个数据可能是 HTML 文件,也可能是 JSON 数据。
此时,页面也没有发生变化。
渲染网页:
在 JavaScript 将服务器发送的数据进行解析、转化,并对原始 HTML 中的源代码进行更改,实现网页内容的更新、删除等。
这个时候,浏览器的页面才会发生改变。
Ajax 动态数据获取案例
以 Chrome 浏览器为例介绍
分析百度搜索界面的新闻动态刷新
首先,我们打开百度搜索界面,在页面中点击鼠标右键
从弹出的快捷菜单中选择“检查”选项,此时便会弹出开发者工具
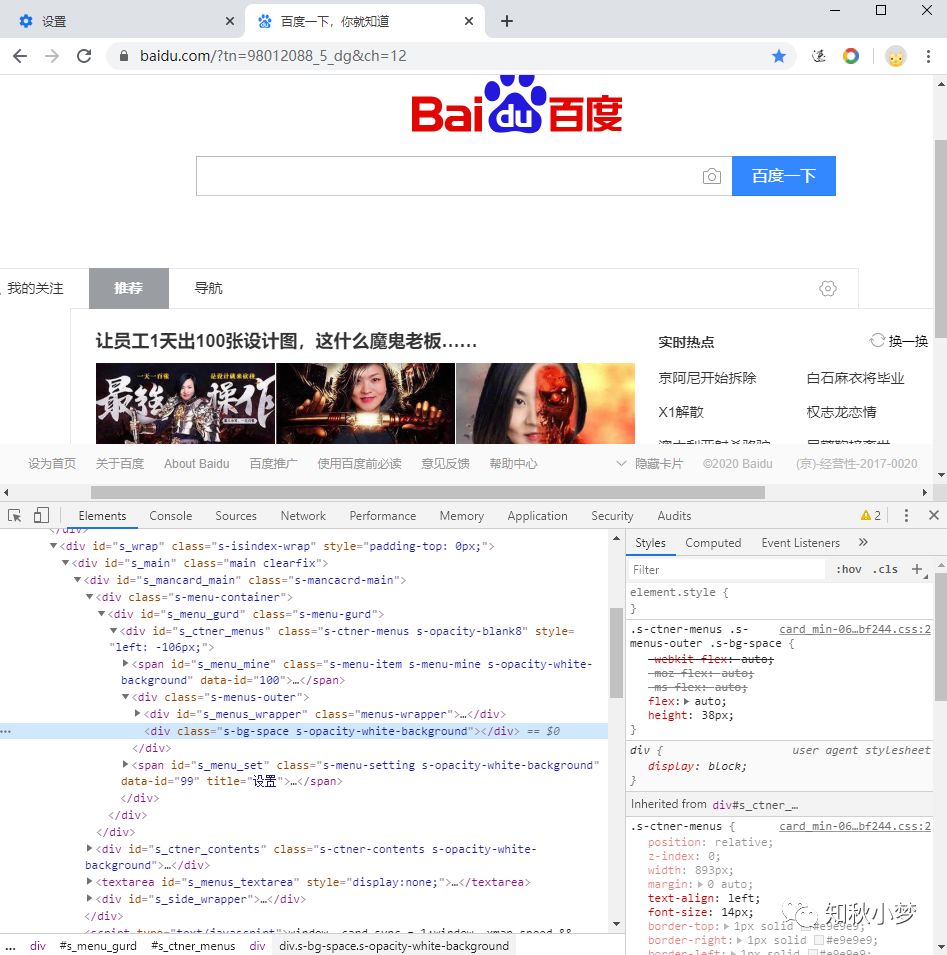
左侧是网页的源代码,右侧是节点的样式。
我们切换到 Network 选项卡,选择 XHR,此时显示应该是空白
为什么选择 XHR 呢?
因为 Ajax 有其特殊的请求类型,就是 XHR
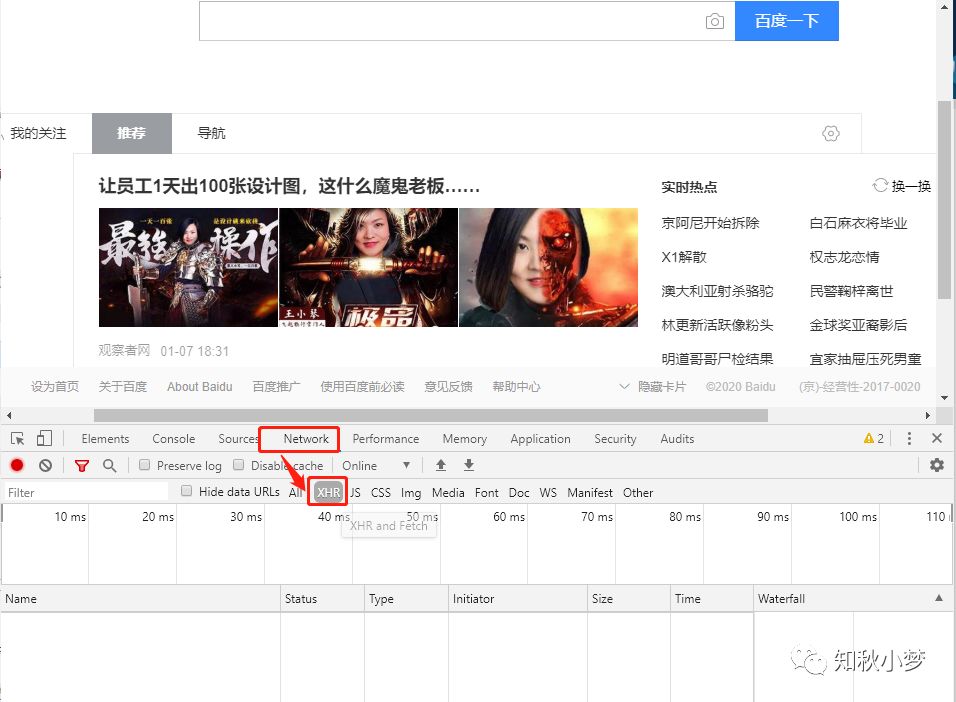
我们在页面上点击下拉查看更多或者鼠标滚轮向下滚动
可以看到在新的新闻刷新的同时,XHR 中也有了相应的链接

在右侧可以观察有 General、Request Headers 和 Response Headers 等信息
同时在 Request URL 中发现有一个 offset 的参数
继续向下滚动滚轮,发现又会出现一个链接
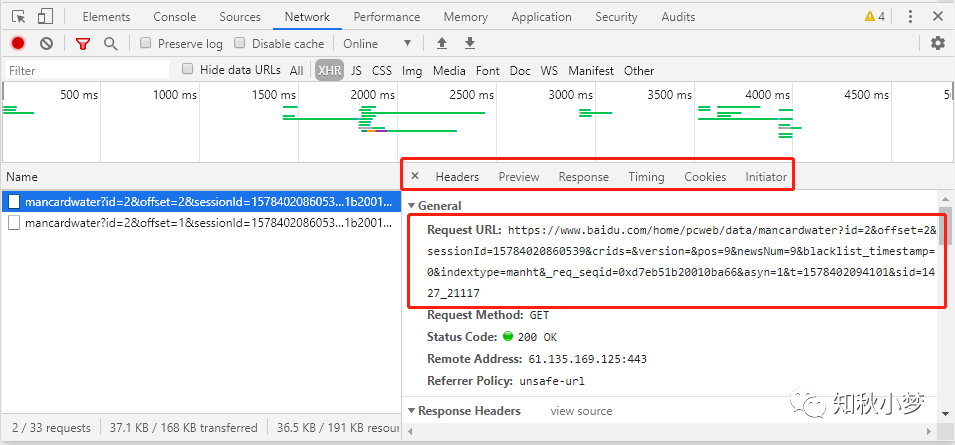
这个时候,新链接中的 Request URL 中的 offset 变成了 2
继续向下滚动滚轮,发现又会出现一个链接

这个时候,新链接中的 Request URL 中的 offset 变成了 3
是不是已经发现了一些规律?
我们再切换到 Preview 和 Response 选项卡,可以看到返回的数据
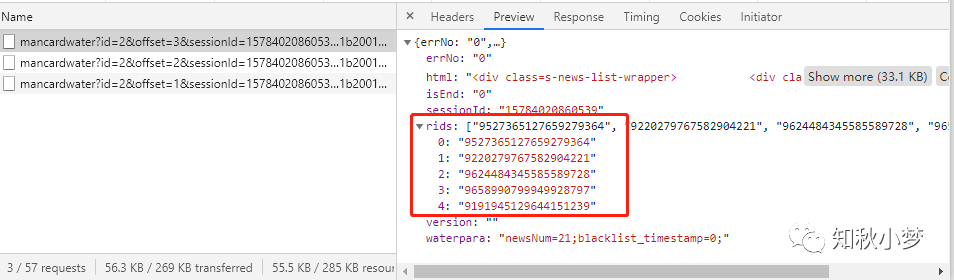
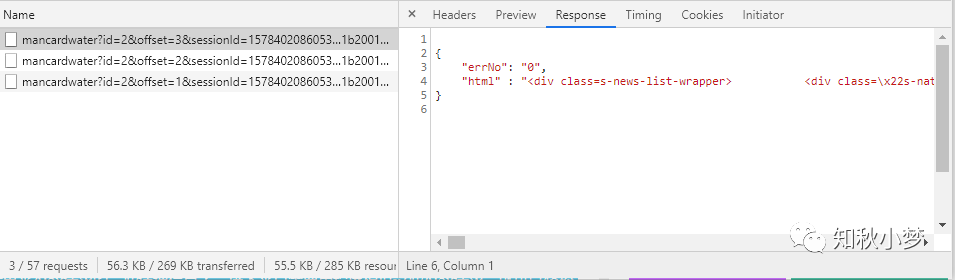
Ajax 每请求一次会得到五条新闻数据,对应的数据类型为 JSON 类型。
到此,我们已经找到 Ajax 请求数据的相应接口
下一步,只需要通过请求相应的接口,对返回的 JSON 数据进行解析,就可以提取到数据了。
总结一下
这节我们介绍了动态数据,不同于前面我们爬取到的静态数据。
对静态数据可以直接用爬虫拿下,而动态数据我们也有两种方法。
这一节主要介绍了第一种:通过 Ajax 动态获取数据。
主要难点是如果通过跟踪网页获取到请求的接口,不过你如果能跟着我顺一遍今天的案例,应该大致会有个了解。
通过 selenium 自动化测试工具我们下节再谈。
写在后面的话
今天就不骗你们点在看了,虽然大多数情况都骗不到 o(╥﹏╥)o
碎碎念一下
我好像发现为什么前几篇5000+了,应该是代码贴的太多了
以后就少贴点代码,多点讲解
不过代码中注释是不会少的。吼吼吼
Python系列
Python系列会持续更新,从基础入门到进阶技巧,从编程语法到项目实战。若您在阅读的过程中发现文章存在错误,烦请指正,非常感谢;若您在阅读的过程中能有所收获,欢迎一起分享交流。
如果你也想和我一起学习Python,关注我吧!
学习Python,我们不只是说说而已
End


如果对你有用,就点个在看吧














 147
147











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









