







前馈神经网络以Rossenblat感知器作为神经元,通过神经元与神经元间的全连接,使信息向前传递,因而称之为“前馈”。而在调整权重时,前一层的权重变化量由后一层的误差梯度决定,于是误差信息从输出层反向传播,这一修正算法被称之为“反向传播算法”。
单个Rossenblat神经元只划定了一个决策边界,而一个决策边界无法对异或运算的分布实现划分。然而,通过增加隐藏层而构成前馈神经网络的方法可以逼近划分运算结果所需的非线性决策边界(之所以说是“逼近”,是因为每个感知器的决策边界仍然是线性的)。为此,使用sigmoid函数(在生态学中又往往被称之为Logistic函数,相对于阶跃函数,是一个软限幅器)作为激活函数:
同时,用误差梯度代替误差e来作为误差的表征:
输出层误差梯度:
隐藏层误差梯度:
注意上述误差梯度公式仅在使用sigmoid函数时成立。事实上,公式左侧两个因式应是激活函数对x的导数。
本程序参考了《人工智能——智能系统指南》(Michael Negnevisky)中实现抑或运算的神经网络拓扑结构:
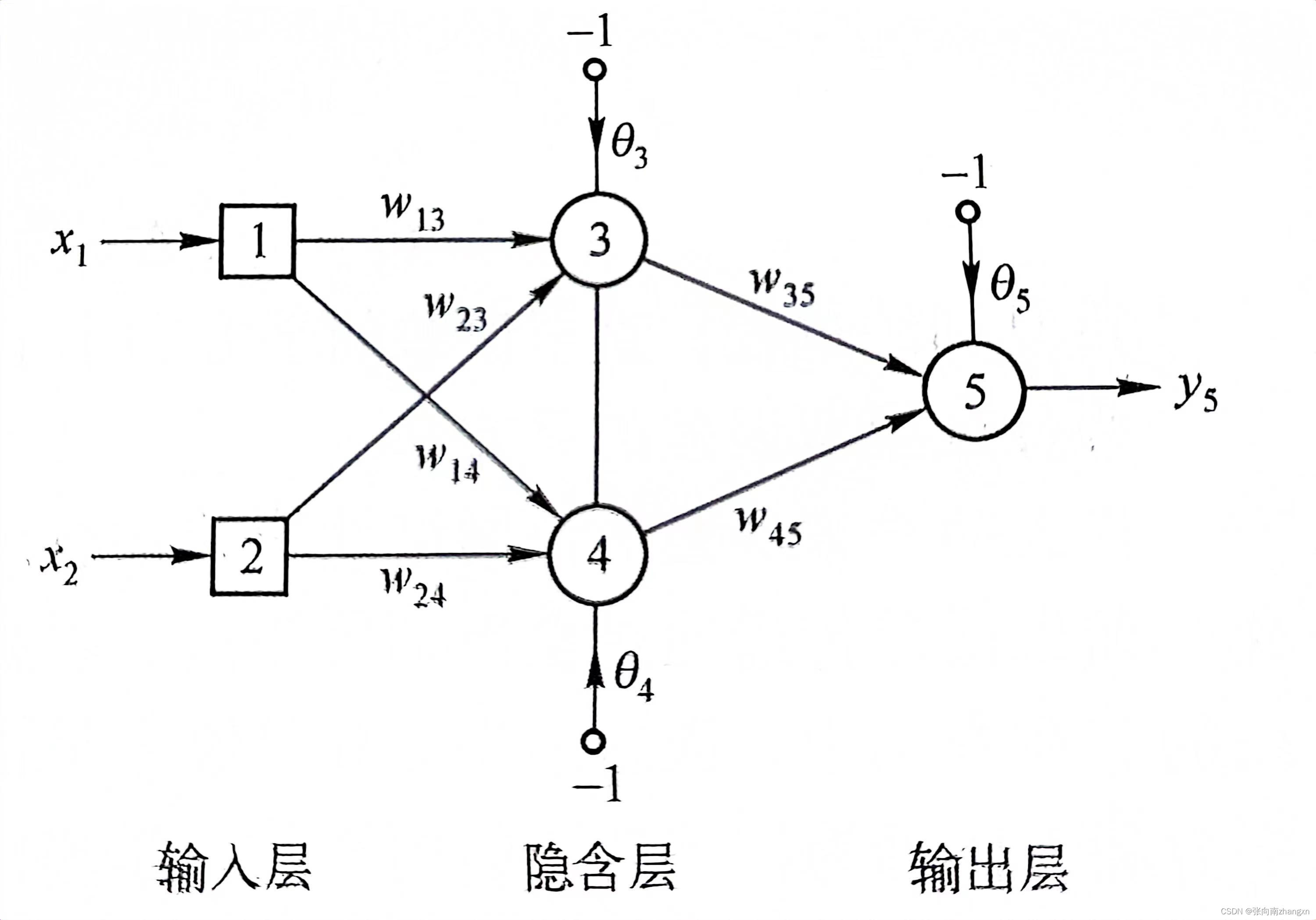
基于上述算法,编写C程序如下:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <math.h>
#include <stdlib.h>
double sigmoid(double x)
{
double Y;
Y = 1 / (1 + exp(-x));
return Y;
}
double delta(double y, double e)
{
float delta;
delta = y * (1 - y) * e;
return delta;
}
int main(void)
{
double x1[4], x2[4];
double Yd[4];
/*逻辑异或运算的真值表*/
x1[0] = 0; x2[0] = 0; Yd[0] = 0;
x1[1] = 0; x2[1] = 1; Yd[1] = 1;
x1[2] = 1; x2[2] = 0; Yd[2] = 1;
x1[3] = 1; x2[3] = 1; Yd[3] = 0;
/*Weight*/
double w13=0.5, w14=0.9, w23=0.4, w24=1.0, w35=-1.2, w45=1.1, s3=0.8, s4=-0.1, s5=0.3;
double cw13, cw14, cw23, cw24, cw35, cw45, cs3, cs4, cs5; /*权重变化量*/
/*搭建神经网络*/
double Y3, Y4, Y5[4] = { -1,-1,-1,-1 }; double e3, e4, e5[4];
double del3, del4, del5; /*误差梯度*/
int i, j=0;
double a = 20; /*学习速率*/
double esquare;
esquare = pow((Yd[0] - Y5[0]), 2) + pow((Yd[1] - Y5[1]), 2) + pow((Yd[2] - Y5[2]), 2) + pow((Yd[3] - Y5[3]), 2);
while (esquare>=0.001) /*控制精确程度*/
{
j = j + 1;
i = 0; /*清零*/
while (i <= 3)
{
Y3 = sigmoid(x1[i] * w13 + x2[i] * w23 - s3);
Y4 = sigmoid(x1[i] * w14 + x2[i] * w24 - s4);
Y5[i] = sigmoid(Y3 * w35 + Y4 * w45 - s5);
e5[i] = Yd[i] - Y5[i];
if (e5 != 0)
{
del5 = delta(Y5[i], e5[i]);
cw35 = a * Y3 * del5;
cw45 = a * Y4 * del5;
cs5 = a * (-1) * del5;
del3 = delta(Y3, del5*w35);
cw13 = a * x1[i] * del3;
cw23 = a * x2[i] * del3;
cs3 = a * (-1) * del3;
del4 = delta(Y4, del5*w45);
cw14 = a * x1[i] * del4;
cw24 = a * x2[i] * del4;
cs4 = a * (-1) * del4;
w35 = w35 + cw35;
w45 = w45 + cw45;
s5 = s5 + cs5;
w13 = w13 + cw13;
w23 = w23 + cw23;
s3 = s3 + cs3;
w14 = w14 + cw14;
w24 = w24 + cw24;
s4 = s4 + cs4;
}
i = i + 1;
}
esquare = pow((Yd[0] - Y5[0]), 2) + pow((Yd[1] - Y5[1]), 2) + pow((Yd[2] - Y5[2]), 2) + pow((Yd[3] - Y5[3]), 2);
printf("iterations:%d\ne_square=%lf\n", j, esquare);
}
printf("Training completed.\nResult:\nw13=%lf, w14=%lf, \nw23=%lf, w24=%lf,\nw35= %lf, w45=%lf,\ns3=%lf, s4=%lf, s5=%lf\n", w13, w14, w23, w24, w35, w45,s3,s4,s5);
double a1, a2, res; int resR;
printf("Input:");
scanf("%lf %lf", &a1, &a2);
Y3 = sigmoid(a1 * w13 + a2 * w23 - s3);
Y4 = sigmoid(a1 * w14 + a2 * w24 - s4);
res = sigmoid(Y3 * w35 + Y4 * w45 - s5);
/*将输出限定在0与1*/
if (res >= 0.5) resR = 1;
else resR = 0;
printf("%d", resR);
return 0;
}程序中的学习速率a是笔者摸索的结果。当a过小时,每次对权重的修正过小;当a过大时,输出层的输出的波动过大,同样不利于权重的收敛。在该程序中,当a=20时,可以在较少的迭代次数内完成训练。
训练完成后输入0和1,输出结果如下(部分):

















 2861
2861











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











