







1、介绍
hadoop起源
源于Google的MapReduce论文(发表与2004年,Hadoop MapReduce是Google MapReduce的克隆版)
Hadoop最早起源于Nutch,一个开源的网络搜索引擎;Nutch目标是构建一个大型的全网搜索引擎;但随着抓取网页数量的增加,遇到了严重的扩展性问题;
Google发表的2片论文提供了可行方案:Google分布式文件系统;Google分布式计算机框架MapReduce;
Nutch根据Google发表的论文,设计了开源实现,即为hadoop项目;
mapreduce设计目标
MapReduce起源于搜索领域,主要解决搜索引擎面临的海量数据处理扩展性差的问题,很大程度上借鉴了Google MapReduce的设计思想;
Hadoop MapRedcue设计目标:
1)易于编程
传统的分布式程序,需要考虑的问题很多,包括数据切分,数据传输,节点间通信;Hadoop一个重要的设计目标是简化分布式程序设计,将分布式程序的细节抽象出由系统完成,用户专注于自己的应用程序逻辑实现;
2)良好的扩展性
计算能力、存储能力
3)高容错性
2、MapReduce特点
良好的扩展性;
高容错性;
适合PB级以及海量数据的离线处理;
3、编程模型
简介
MapReduce由2个阶段组成:Map阶段和Reduce阶段;用户只需要编写map()和reduce()2个函数,即可完成简单的分布式程序;
Map()以key/value为输入,产生另外一些key/value对作为中间输出写入本地系统;MapReduce框架会自动将这些中间数据按照key值进行聚集,key值相同的交给同一reduce()处理;
Reduce()以key和对应的value列表为输入,合并key相同的value,将输出保存到hdfs中;
Hadoop 将输入数据切分成若干个输入分片(input split,后面简称split),并将每个split 交给一个Map Task 处理;Map Task 不断地从对应的split 中解析出一个个key/value,并调用map() 函数处理,处理完之后根据Reduce Task 个数将结果分成若干个分片(partition)写到本地磁盘;同时,每个Reduce Task 从每个Map Task 上读取属于自己的那个partition,然后使用基于排序的方法将key 相同的数据聚集在一起,调用reduce() 函数处理,并将结果输出到文件中。

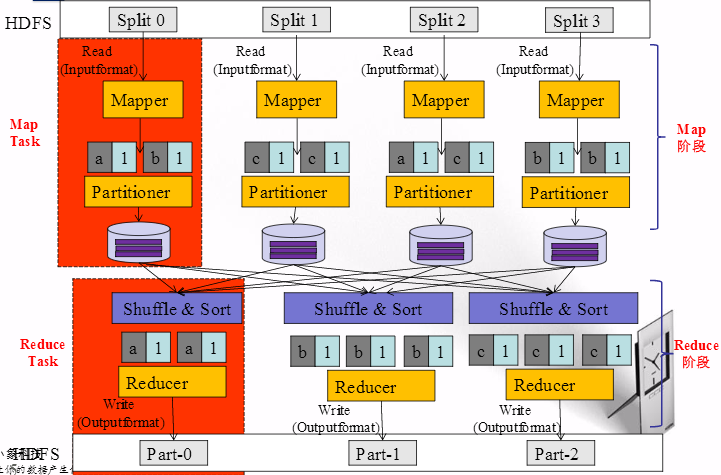
Map阶段:
InputFormat
Mapper
Combiner(local reducer)
partitioner
Reduce阶段:
reducer
outputFormat
编程实例
MapReduce 能够解决的问题有一个共同特点:任务可以被分解为多个子问题,且这些子问题相对独立,彼此之间不会有牵制,待并行处理完这些子问题后,任务便被解决;
InputFormat
数据切分:按照某种策略将输入数据切分成若干个split,以确定map task个数和每个map task对应的split;
为mapper提供输入数据:给定某个split,将其解析成一个个key/value对;
4、MapReduce基本架构
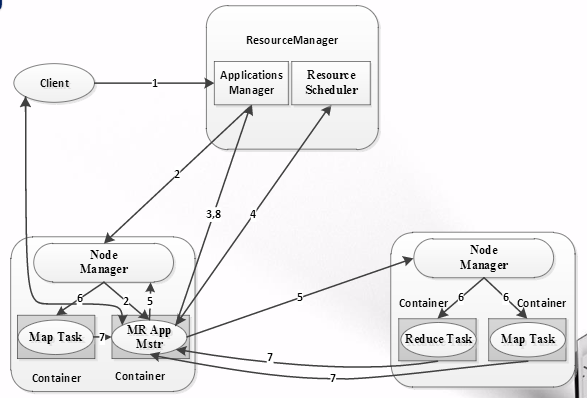
Client
与Yarn交互,提交MapReduce作业,查询作业运行状态,管理作业;
MRAppMaster
类似于MR1.0中的JobTracker,但不负责资源管理;
功能:任务划分,资源申请并将之二次分配给Map task和Reduce task,任务状态监控和容错;
5、MapReduce作业运行过程
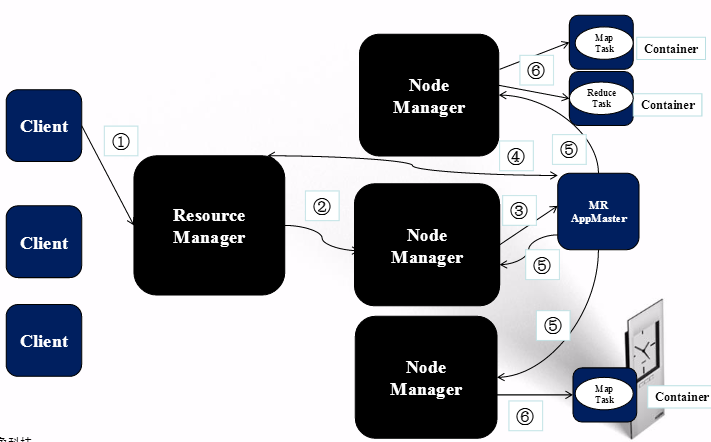
MapReduce内部机制
1)本地性
什么是本地性?
任务运行在它将处理的数据所在的节点上;
本地性分类?
同节点
同机架
其他
2)执行机制

3)任务并行
多个map task并行
多个reduce task并行















 1451
1451

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









