






CL-ReLKT: Cross-lingual Language Knowledge Transfer for Multilingual
Retrieval Question Answering
摘要:
跨语言检索问答(CL-REQA)涉及检索用不同语言编写的问题的答案文档或段落。CL-REQA的一种常见方法是创建一个多语言句子嵌入空间,使不同语言的问答对彼此接近。在本文中,我们提出了一种新的CL-REQA方法,该方法利用语言知识迁移的概念和一种新的跨语言一致性训练技术来为REQA创建多语言嵌入空间。为了评估我们工作的有效性,我们对CL-REQA和下游的机器阅读QA进行了全面的实验。我们在三个公共CL-REQA语料库上将我们提出的方法与当前最先进的解决方案进行了比较。在CL-REQA的21个设置中,我们的方法在19个设置上优于竞争对手。当与下游机器阅读问答任务一起使用时,我们的方法在F1中的性能比现有最好的基于语言模型的方法高出10%,而在句子嵌入计算上则快了10倍。代码和模型可在https://github.com/mrpeerat/CL-ReLKT上查阅。
1 介绍
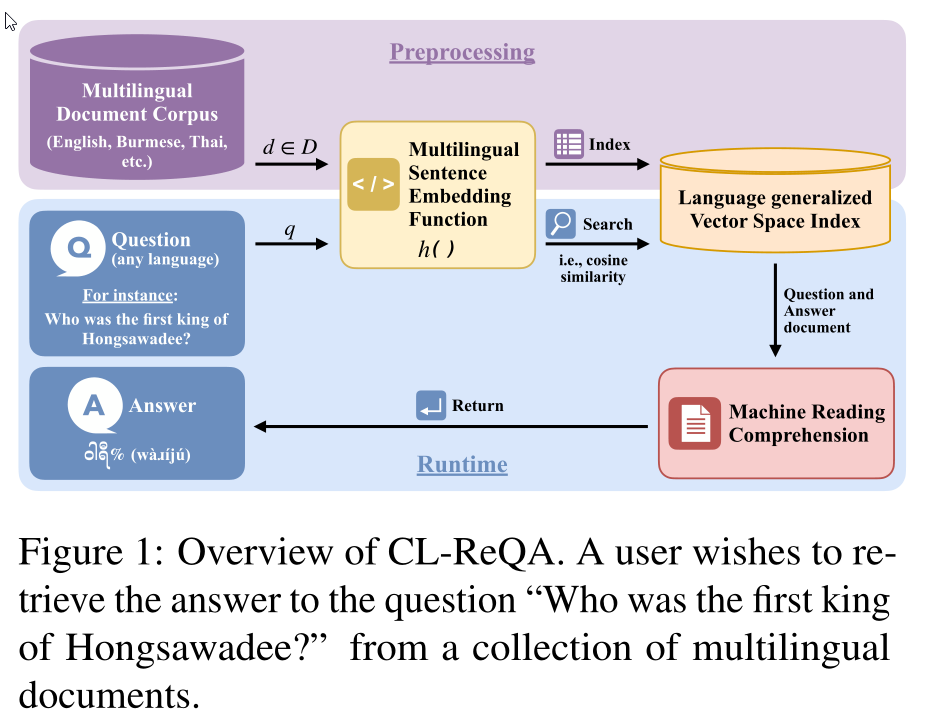
跨语言问答允许使用另一种语言编写的材料回答用一种语言提出的问题。如图1所示,人们可能会问:“谁是洪萨瓦底的第一位国王?”他们的答案可以从缅甸语或其他语言的历史文献中找到。为了支持给定的示例应用程序,我们需要一个能够同时处理多种语言的文档和问题的检索系统。也就是说,我们希望将多种语言的问题和答案映射到同一个空间,以便于检索。该功能也称为跨语言检索问答(CL-REQA)
1.1 现有方法
CL-ReQA的一个突出方法是多语言句子嵌入,即创建一个可以处理不同语言的问题和答案的嵌入空间。这种方法可以进一步分为:
(1)LM-Based: finetuning a language model (LM),比如 mBERT and XLM-R;
Devlin等人(2019)和Conneau等人(2020)分别提出了一种具有多种语言(100多种语言)的预训练大规模语言模型,称为mBERT和XLM-R。这两种解决方案都依赖于将LM部分微调到目标任务。Reimers和Gurevych(2020)在使用双语文本挖掘任务进行微调后,准确性从11.6%提高到88.6%。许多最近的工作已经探索了微调LMs,例如,各种监督学习任务的三重态丢失(Reimers和Gurevych,2019),知识提取(Reimer和Gurevych,2020),密集网络QA编码器(Karpukhin等人,2020),以及为翻译任务提供初始单词嵌入(Feng等人,2020)。尽管如此,微调这些模型需要大量的训练样本(在某些情况下超过100000个句子(Reimers和Gurevych,2020;Zhang等人,2021;Wang等人,2021))才能在多语言环境中提供最佳性能。另一方面,跨语言QA训练语料库通常较小,每种语言只有1000到1500个问题。我们需要一种可以在有限数据量下操作的方法。
(2)USE-Based: finetuning the Universal Sentence Encoder (USE) for QA
Universal Sentence Encoder(通用句子编码器)
基于通用句子编码器(USE)架构(Cer等人,2018),杨等人(2020)提出了一种利用具有16种不同语言和多个训练目标的多语言语料库的训练方法。他们称他们的预训练网络为多语言使用或mUSE。Trijakwanich等人(2021)的实验结果表明,mUSE的性能优于基于LM的方法。然而,该方法在mUSE训练语料库之外的语言(即不支持的语言)上表现不佳。这种限制阻碍了在有限资源语言上采用mUSE。
1.2 我们的工作
提出的方法
在本文中,我们的目标是提高适用于多种语言(包括训练数据量有限的语言)的多语言句子嵌入的鲁棒性。利用语言知识转移的普遍性,我们提出了一个跨语言检索语言知识转移框架。图1说明了如何通过多语言嵌入函数h()进行跨语言检索。给定任何语言中的问题文档对(q,d),与使用任何相似性度量(例如,余弦相似性)的任何其他文档相比,h(d)更接近h(q)。
学习的目标
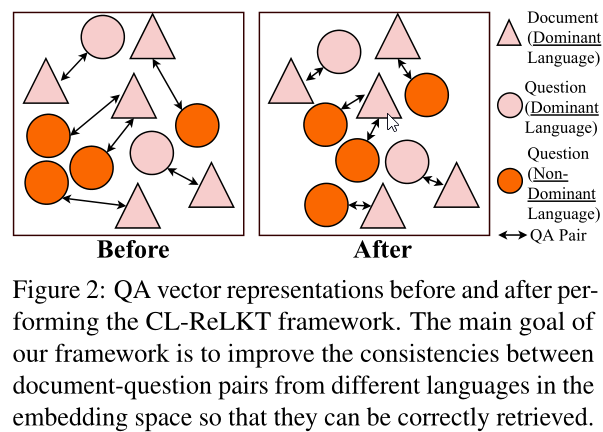
如图2所示,提出的CL-ReLKT框架旨在通过使跨语言问答对彼此更接近来改善嵌入空间。我们提出的框架的关键在于以下两个部分。首先,我们制定了一个LKT(语言知识转移)过程来创建语言泛化学生。特别是,我们利用了这样一个事实,即在一个大型多语言语料库中可能有一种语言主导着所有其他语言。我们使用该语言来帮助提高其他语言的嵌入质量。其次,我们提出了一种新的损失函数,旨在提高多语言环境中问答对之间的跨语言一致性。我们旨在提高教师(主导语言)和学生(其他语言)在以下教师-学生输出对中的一致性:问题-问题、文档-文档和文档-问题。
实验研究
为了确定我们方法的有效性,我们在15种语言的三个数据集上比较了拟议方法与当前最佳实践(在第1.1节中讨论)。实验结果表明,在所有情况下,CL-ReLKT框架在mUSE支持的语言上都优于所有竞争方法。在不支持的语言(即mUSE训练语料库之外的语言)上的结果表明,CL-ReLKT框架在所有情况下都显著提高了mUSE编码器的性能(p<0.05)。此外,在机器阅读QA(MR-QA)的下游任务中,我们的方法在八分之七的情况下获得了比现有最好的基于LM的方法更好的F1和精确匹配分数。最后但并非最不重要的是,我们的方法在句子嵌入计算成本方面也比最先进的基于LM的竞争对手快10倍。
论文贡献
(1)我们提出了一种新的语言知识转移方法,称为跨语言检索语言知识转移(CL ReLKT),将知识从主导语言转移到非主导语言,并构建语言通用编码器。
(2)我们设计了一个新的损失函数,以加强主导和非主导语言向量表示之间的跨语言一致性。
(3)为了评估模型的性能和效率,我们进行了一系列广泛的实验研究,涉及2个任务、15种语言和8个竞争对手。实验结果表明了我们提出的CL-ReLKT框架的优点。此外,我们发现在文档级检索答案比通道级方法有显著改进。
2 背景
2.1 主导语言
在多语言数据集中,语言的分布往往不平衡。如图3所示,英语句子数量约占语料库中用于构建mUSE的所有句子的50%(杨等人,2020年)。
由于所述语言不平衡,具有大量数据的语言中的模型性能往往大大优于其他语言(Arivazhagan等人,2019;Wang等人,2020)。当我们希望模型性能在多种语言之间保持一致时,这个问题可能会有问题。
对于mUSE,如图3所示,我们可以看到,就可用的训练数据而言,英语是主导语言。因此,英语-英语检索性能往往优于所有其他语言对。为了验证这一性能差距,我们使用非英语提问和英语回答文档进行了CL-ReQA实验研究;mUSE用于对问题和文件进行编码。实验结果表明,当将问题翻译成英语而不是使用原始的非英语问题时,即将问题从俄语翻译成英语时,性能显著提高,将at-1的精度从43.3%提高到52.8%。完整结果见附录A.3。
2.2 语言知识转移
有许多技术可以使用从丰富资源语言获得的结构来提高低资源语言上的模型性能。迁移和多任务学习是利用丰富资源语言的流行范例。这些方法通常依赖于共享编码器策略,以便使用同一模型在所有其他语言中共享用一种语言学习的语言模式(Lin等人,2019;Nooralahzadeh等人,2020;Zoph等人,2016;Schwenk和Douze,2017;Neubig和Hu,2018;Yang等人,2020年;Feng等人,2020)。这类技术通常被称为语言知识转移(LKT)。通过共享编码器,对一种语言的改进往往也有利于其他语言。让我们考虑一个场景,其中英语中有大量问答对,而其他语言(例如俄语、法语和德语)中的问答对数量要少得多。通过在使用英语数据进行训练时更新编码器权重,让其他语言共享相同的编码器,我们还可以提高模型在其他语言中的一般编码性能。
3 提出的方法
在本节中,我们利用前一节讨论的两个概念,即主导语言和语言知识转移,制定了我们提出的方法。特别是,我们进行语言知识转移,将知识从主导语言转移到其他语言。我们提出的方法包括两个阶段:教师模型准备和跨语言检索语言知识转移(CL-ReLKT),具体描述如下。
3.3 第一阶段:教师模型准备
这一阶段的目的是为下一阶段的语言知识转移创造一个强有力的教师。对于基本模型,出于效率和性能考虑,我们使用mUSEsmall![]() .
.
有几种技术可以用来创建教师模型mUSEteacher![]() ,我们的消融研究表明,triplet loss是一个合理的选择。如等式一所示,triplet loss Ltp
,我们的消融研究表明,triplet loss是一个合理的选择。如等式一所示,triplet loss Ltp![]() 是一个训练目标,该目标最大化锚正对(anchor-positive)(a,p)之间的余弦相似性cos(·),并使锚负对(anchor-negative)(a,n)之间的相似性小于所有训练数据M的给定阈值α.
是一个训练目标,该目标最大化锚正对(anchor-positive)(a,p)之间的余弦相似性cos(·),并使锚负对(anchor-negative)(a,n)之间的相似性小于所有训练数据M的给定阈值α.
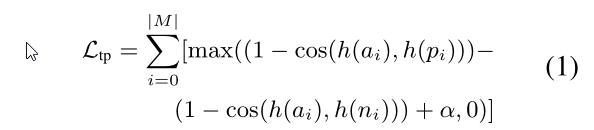
虽然锚a可以从问题中随机抽样,但我们需要CL-ReQA模型来帮助选择正p和负n。对于负样本分类,我们考虑两种选择。首先,我们可以直接使用原始mUSEsmall![]() 模型根据当前嵌入空间(online fishion)对负样本进行分类(Kaya和Bilge,2019)。其次,我们可以应用Karpukhin等人(2020)提出的方法,该方法利用BM25(Trotman等人,2014)来生成文本相似性分数。根据附录A.5.1中给出的消融研究,结果表明,前三个阶段在进行五个阶段的在线挖掘(Kaya和Bilge,2019)之前使用了三重挖掘的初始策略(Kaya and Bilge),产生了最佳性能。
模型根据当前嵌入空间(online fishion)对负样本进行分类(Kaya和Bilge,2019)。其次,我们可以应用Karpukhin等人(2020)提出的方法,该方法利用BM25(Trotman等人,2014)来生成文本相似性分数。根据附录A.5.1中给出的消融研究,结果表明,前三个阶段在进行五个阶段的在线挖掘(Kaya和Bilge,2019)之前使用了三重挖掘的初始策略(Kaya and Bilge),产生了最佳性能。
3.2 第二阶段:CL-ReLKT
现在,我们描述了使用语言知识转移(LKT)的概念来提高一般CL-ReQA性能的方法。正如我们在第2.2节中提到的,LKT是一种技术,使用同一种模型,在一种语言中学习的语言模式可以在所有其他语言中共享。将相同的概念应用到我们的问题中,我们可以设置LKT过程来提高主语言和其他语言之间的嵌入一致性。特别是,我们将LKT环境设置为:
(i)教师使用主导语言,即英语;
(ii)该学生使用非主导语言;
(iii)学生试图模仿教师的嵌入输出。
在下文中,我们描述了教师和学生模型、输入以及培训过程的损失函数。
教师和学生模型
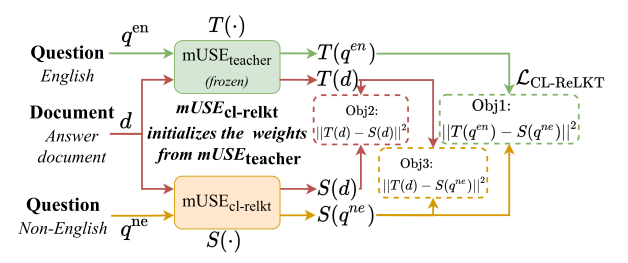
如图4所示,跨语言检索语言知识转移(CL ReLKT)过程由教师、学生和损失函数组成。最初,将学生的参数初始化为与第1阶段培训的教师相同的值。在培训过程中,教师的参数是固定的;我们只根据损失函数调整学生的参数。
输入
现在让我们考虑一下培训过程的输入问题和答案文档。如图4所示,教师和学生模型都接受相同的文档输入d。然而,每个问题有两个不同的版本,英语![]() 和非英语
和非英语![]() 。英语问题是原文
。英语问题是原文![]() 的翻译。这为我们提供了一个问题对(
的翻译。这为我们提供了一个问题对(![]() ,
,![]() ),用于不同语言之间的语言知识转移。为了简单起见,我们使用谷歌神经机器翻译(GNMT)将
),用于不同语言之间的语言知识转移。为了简单起见,我们使用谷歌神经机器翻译(GNMT)将![]() 翻译成
翻译成![]() 。注意,如果可用,也可以使用人工翻译的平行问题。
。注意,如果可用,也可以使用人工翻译的平行问题。
教师模型T()接受作为输入,而学生模型S()接受作为输入。换言之,![]() 作为LKT过程的“参考”。根据我们的评估(附录A.5.3),英语表现最好,因此被选为培训过程的主导语言。注意,这一发现也符合图3所示的数据分布
作为LKT过程的“参考”。根据我们的评估(附录A.5.3),英语表现最好,因此被选为培训过程的主导语言。注意,这一发现也符合图3所示的数据分布
损失函数
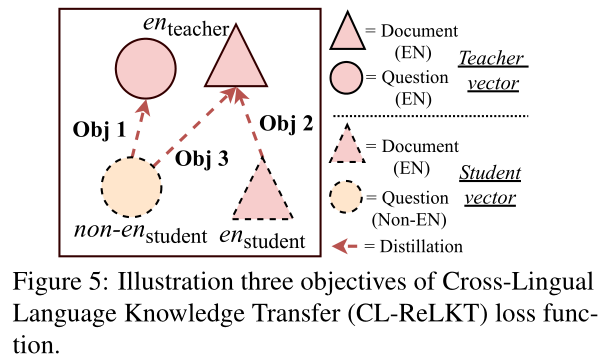
我们的CL ReLKT损失函数的目标是让学生模仿教师的知识,从主导语言到学生的目标语言。如图5所示,我们的损失函数![]() 有三个一致性目标,即question-question, document-document, and document-question.。我们将其描述如下:
有三个一致性目标,即question-question, document-document, and document-question.。我们将其描述如下:
①目标一:question-question. 第一个目标是在分别编码用英![]() 和非英语
和非英语![]() 表达的相同问题时,加强S()和T()之间的一致性。
表达的相同问题时,加强S()和T()之间的一致性。
②目标二:document-document. 在为第一个目标调整student S()的同时,我们还希望保持其答案文档编码不变。因此,我们希望保持T(d)和S(d)之间的一致性。
③目标三:document-question. 为了适应查找过程,嵌入空间还应保持问答对彼此一致。作为我们的第三个目标,我们最小化学生问题向量S(![]() )和教师文档向量T(d)之间的差异。
)和教师文档向量T(d)之间的差异。
我们将损失函数![]() 表示为这三个一致性目标的线性组合。使用平方L2范数作为差异度量,我们得到以下损失函数:
表示为这三个一致性目标的线性组合。使用平方L2范数作为差异度量,我们得到以下损失函数:
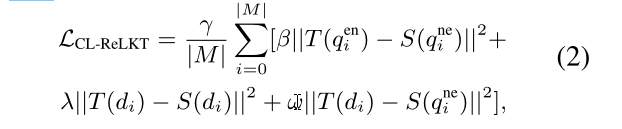
M是给定批次中使用的训练样本集,β、λ和ω是加权系数。
讨论
如前所述,损失函数的目标是将教师的知识传递给使用目标语言的学生。由于教师主导语言的表现是广义的,在LKT过程之后,其他语言将具有相同的属性。实验结果表明,与教师模型相比,学生可以更好地处理不支持的语言,并提高支持语言的性能。这种改进来自损失函数中的跨语言一致性目标Obj1和Obj3,而Obj2保持了单语一致性。此外,![]() 不要求教师和学生模型具有相同的架构;它可以应用于任何预训练模型。(有关更多信息,请参阅附录A.4)
不要求教师和学生模型具有相同的架构;它可以应用于任何预训练模型。(有关更多信息,请参阅附录A.4)
实验
1、实验证明基于文档的答案检索单元的Mashine Reading QA(MR-QA) (即检索结果是文档)比基于段落的效果更好,故在其他的嵌入实验中使用该设置。
2、在我们模型支持的语言(支持的语言,即训练数据中包含的语言)上进行跨语言检索问答 (CL-ReQA)。我们提出的模型![]() 和比基础模型
和比基础模型![]() 有显著改进。此外,我们的模型也优于最大的预先训练的mUSE变体
有显著改进。此外,我们的模型也优于最大的预先训练的mUSE变体![]() 。我们提出的所有模型也明显优于基于LM的竞争对手。结果还表明,我们的一致性增强方法CL-ReLKT在除AR语言外的所有情况下对MLQA数据集都是有效的。
。我们提出的所有模型也明显优于基于LM的竞争对手。结果还表明,我们的一致性增强方法CL-ReLKT在除AR语言外的所有情况下对MLQA数据集都是有效的。
3、在不支持的语言上进行跨语言检索问答(CL-ReQA)。![]() 和
和![]() 之间的性能差距证明了所提出的CL-ReLKT框架的有效性。我们可以使用CL-ReLKT来生成基本语句嵌入模型,以处理最初未包含在训练过程中的语言。CL-ReLKT在印地语上表现不佳是因为:印地语是唯一在原始训练数据中没有表示其家族的语言。
之间的性能差距证明了所提出的CL-ReLKT框架的有效性。我们可以使用CL-ReLKT来生成基本语句嵌入模型,以处理最初未包含在训练过程中的语言。CL-ReLKT在印地语上表现不佳是因为:印地语是唯一在原始训练数据中没有表示其家族的语言。















 414
414











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









