






知识蒸馏,teacher—student模型的思考
这个方向的学术源头是Rich Caruana2014年的作品《Do Deep Nets Really Need to be Deep?》,后来经过Hinton的《Distilling the Knowledge in a Neural Network》发扬光大。实用价值:可以对大型神经网络进行瘦身以便部署到用户端;理论价值:引发对深度网络的思考:一个网络的表达能力与什么有关(参数量,结构的深浅,学习算法);对于当前的一些问题浅层网络表现不好,是由于表达能力欠缺,还是因为优化算法(SGD及其变体)更加适合深层网络?
Do Deep Nets Really Need to be Deep?
摘要
现阶段,深度网络的在语音识别、CV等问题上都取得了非常好的表现。本文,作者通过实验证明了浅层网络能学习到之前由深层网络学习到的复杂函数,也能实现之前只能由深度网络实现的精度。而且在某些情况下浅层网络能以与最初的深度模型相同的参数量学习到这些深度函数。在TIMIT和CIFAR-10数据集上,浅层网络经过训练能够与那些复杂的,精心设计的,更深的卷积结构相媲美。
introduction
问题提出:
给你一个1M的带有标记点的训练数据集,使用单隐层的全连接前馈神经网络,你最多只能实现86%的测试精度。但是,如果你使用一个拥有卷积层、池化层、三个全连接层的前馈卷积神经网络,可以实现91%的测试精度。
为什么会这样?:
1、深度网络拥有更多的参数
2、相同的参数量,深度网络可以学习到更加复杂的函数
3、深度网络有更好的偏置,能够学习到更加复杂的函数
4、卷积操作起到了重要的作用
5、当前的学习算法以及正则化方法与深度结构结合的更好
本文设计实验证明了浅层网络能够学习到深层网络学习到的函数,而且在一定情况下是以相同参数量实现的。步骤:先训练好一个表现良好的深层网络,接着用一个浅层网络去模拟这个深层网络。
Training Shallow Nets to Mimic Deep Nets
1、模型压缩
主要思想:用一个更加紧凑的模型去拟合一个复杂的模型。
本文做法:先用带标签的训练集训练出一个复杂的模型,然后用这个模型对一些无标签的数据集进行预测,预测值与无标签数据集构成新的训练集以训练浅的模型。
2、利用回归对数值的L2损失进行模型学习
通常深度模型利用cross-entropy作为目标损失函数,但是softmax输出的数值所蕴含的信息对于teacher模型来说是容易学习的,对student模型来说是困难的。比如:第一种情况,teacher模型给出的三个概率预测值是[2e-9,4e-5,0.9999],如果我们直接把他们当做目标来最小化cross-entropy损失函数,student模型会更加关注第三个值而忽略掉了前两个值。但如果我们使用teacher模型输出的对数值(网络最后一层的输出,未经过softmax),新的目标为[10,20,30],情况则会大大的不同。第二种情况,经过softmax函数[-10,0,10]与[10,20,30]有着相同的概率值,对于学生模型来说是很难分辨出这是两种不同的情况。另外本文作者还尝试KL散度等其他损失函数,发现L2效果是最好的。
3、通过引入一个线性层来加速模型的收敛
为了达到与深度模型相当的参数量,浅层模型必须要加宽,随之而来的就是计算量增加的问题。假如输入时D维,H是隐藏层的个数,那么两层间矩阵的计算次数是O(HD)的。为此,本文在输入与隐层之间假如了一个线性层(等同加了一个隐藏层,节点为K个,k<<D,H,只是没有非线性函数),计算次数则变成了O(k(H+D))。
实验
1、TIMIT数据集上
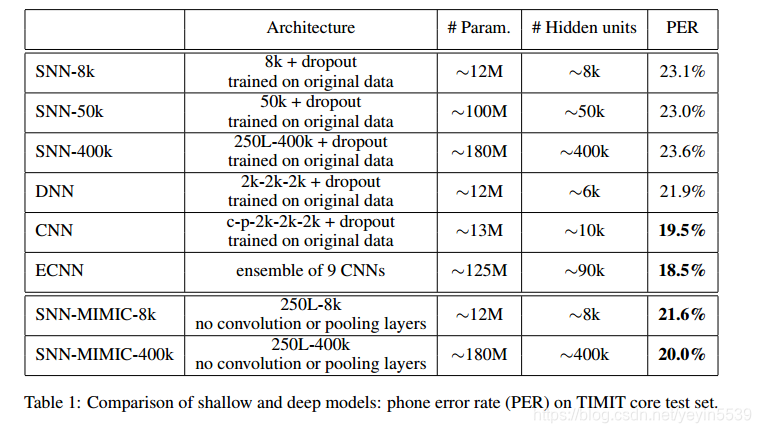
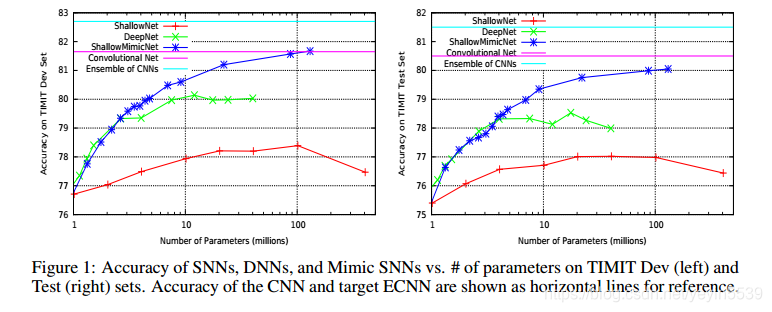
2、CIFAR-10数据集上
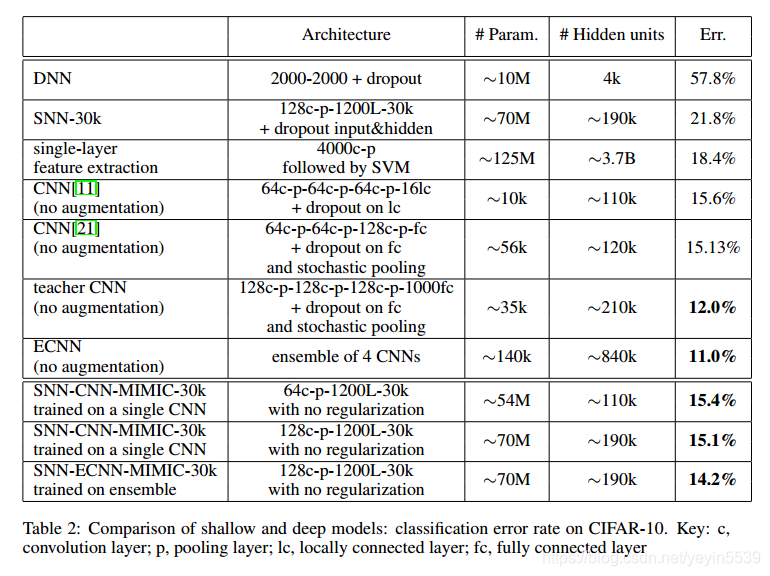
实验反映了两个事实:
1、浅层模型可以模仿出深层模型的行为,实现相当的精度。侧面说明浅层网络并不像我们想象中的那样表达能力不足,只是现有的学习算法无法从原始的数据集上找到这样的解。
2、同一个浅层模型,模拟深度网络得出的结果,直接从原始数据集上是训练不出来的。
思考
1、为什么在原始训练集上训练不出效果好的浅层网络?
原始训练集可能存在标记错误,教师模型能够消除这种错误;
教师模型提供的软标签相比于1/0这种硬标签有更丰富的信息,让学生模型更容易学习。
2、教师-学生模型,对于浅层网络来说相当于一个正则化手段
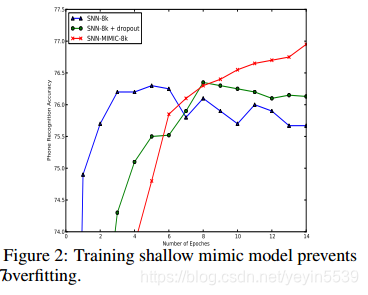
可以看到,随着训练层数的增多,只有模拟网络的精度一直在增加。模拟网络的精度上限或许就是被模拟深度模型的精度。
3、浅层模型的表示能力
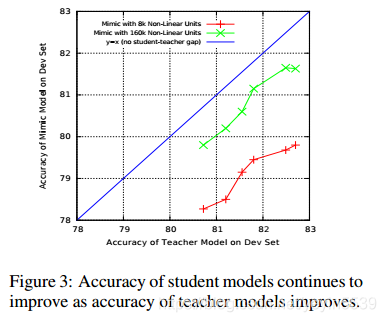
去模拟相同精度的教师网络,拥有160K参数量的浅层网络,要比只有80k参数量的浅层网络表现好(说明相同的学习算法条件下,参数量体现了网络的表示能力)。但是当80k参数量的网络去模拟精度更好的深度网络时,就能在测试集上实现与160k网络相当的精度(说明老师模型提供的软标签非常重要,足以弥补参数量的不足)。
小结
teacher-student模型的实用价值巨大,即使部分情况下浅层网络的参数量可能多一些,但是计算消耗依然比深度模型小很多,方便部署到个体用户端。在理论方面,可以知道的是:当前的学习算法、正则化算法等训练手段与深度模型更加匹配;相比于结构(深层、浅层)参数量更加能体现一个网络的表示能力;
Distilling the Knowledge in a Neural Network?
摘要
对于大多数机器学习算法来说,提高其性能的一个简单的方法就是在相同的数据集上训练出多个不同的模型然后对它们的结果取平均。不幸的是,使用整个模型组合比较笨重,而且对于大多数用户来说计算代价太大,特别是当单个模型都是比较大的神经网络的时候。Caruana和他的合作者已经证明了将模型组合的知识压缩到一个简单的单个模型中的可行性(Model Compression 2006),本文作者延续这个思路提出了不同的压缩方法。作者在MNIST数据集上实现了实现了一些令人惊讶的结果,并且通过将模型组合中知识蒸馏到一个单一的模型中,显著地提升了在商业系统中广泛应用的声音模型的性能。
不同点
Hinton这篇文章的思路跟前一篇无差,只是将损失函数变成了cros-entropy损失函数(他加了一个温度T来控制训练,并且证明了在T较大时,训练过程与L2损失函数一样)。这篇文章中,Hinton将知识蒸馏的可行性归功于教师模型的提供的软标签。
1、软标签有更多的信息量。比如说,对于一个分类问题(宝马车,拖拉机,狗)教师模型给出的预测概率是(0.8,0.19,0.01),0.19/0.0.1概率虽然很小但是体现了教师模型的泛化倾向,某些角度可能会识别成拖拉机但是不会识别成狗,而这些是硬标签(1,0,0)提供不了的。
2、使用软标签有很好的泛化能力。
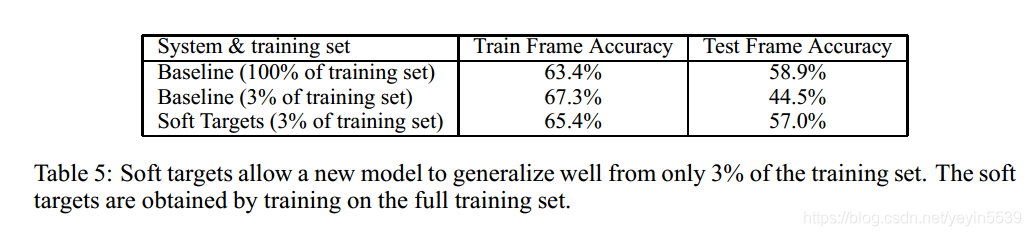
注:Basline(3%of training set)使用了提前终止来防止过拟合,而Soft Targets(3%of training set)里并没有使用。
用更少的训练数据,得到精度更高的网络,进一步提升了它的实用价值。
总结
1、teacher-student模型能够对大型网络进行瘦身,且不会失去太多的精度,将网络分布到用户端成为可能
2、现有的学习优化体系下与深度网络更加匹配
3、现在主流的网络有大量的冗余,相对而言,训练数据集的量还是不够大,完全可以用一个浅层的网络解决, SGD方法还有很远一段路走
4、一个网络的表示能力跟其参数量有很大关系

















 3878
3878

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









