







0 前言
认识一个新框架的时候,先要知道这个东西干什么用的,具体有哪些实际应用场景,根据它的应用场景去初步推测它的架构(包括数据结构,设计模式等)是怎样的,而不是上来就看定义概念。
1.1 Kafka应用场景
1.1.1 异步处理
电商网站中,新的用户注册时,需要将用户的信息保存到数据库中,同时还需要额外发送注册的邮件通知、以及短信注册码给用户。但因为发送邮件、发送注册短信需要连接外部的服务器,需要额外等待一段时间,此时,就可以使用消息队列来进行异步处理,从而实现快速响应。

1.1.2 系统解耦

1.1.3 流量削峰

1.1.4 日志处理
大型电商网站(淘宝、京东、国美、苏宁...)、App(抖音、美团、滴滴等)等需要分析用户行为,要根据用户的访问行为来发现用户的喜好以及活跃情况,需要在页面上收集大量的用户访问信息。

1.2 生产者、消费者模型
我们之前学习过Java的服务器开发,Java服务器端开发的交互模型是这样的:

我们之前还学习过使用Java JDBC来访问操作MySQL数据库,它的交互模型是这样的:

它也是一种请求响应模型,只不过它不再是基于http协议,而是基于MySQL数据库的通信协议。
而如果我们基于消息队列来编程,此时的交互模式成为:生产者、消费者模型。
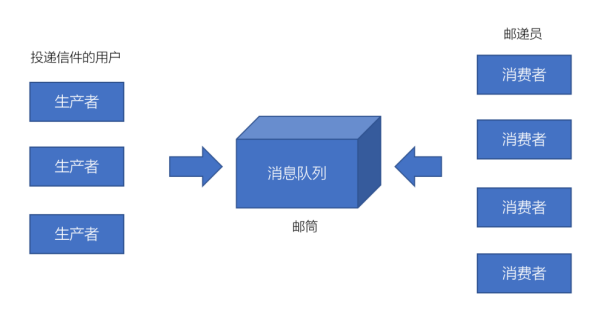
1.3 消息队列的两种模式
1.3.1 点对点模式

消息发送者生产消息发送到消息队列中,然后消息接收者从消息队列中取出并且消费消息。消息被消费以后,消息队列中不再有存储,所以消息接收者不可能消费到已经被消费的消息。
点对点模式特点:
- 每个消息只有一个接收者(Consumer)(即一旦被消费,消息就不再在消息队列中)
- 发送者和接收者间没有依赖性,发送者发送消息之后,不管有没有接收者在运行,都不会影响到发送者下次发送消息;
- 接收者在成功接收消息之后需向队列应答成功,以便消息队列删除当前接收的消息;
1.3.2 发布订阅模式

发布/订阅模式特点:
- 每个消息可以有多个订阅者;
- 发布者和订阅者之间有时间上的依赖性。针对某个主题(Topic)的订阅者,它必须创建一个订阅者之后,才能消费发布者的消息。
- 为了消费消息,订阅者需要提前订阅该角色主题,并保持在线运行;
此时你脑海里想到了一些什么东西?是不是有观察者模式?但他们还是有一些区别的。
(1)从组成成分上看:
- 观察者模式里,只有两个角色:
观察者和目标者(也可以叫被观察者)。其中 被观察者 是重点。 - 发布订阅模式里,不仅仅只有
发布者和订阅者,还有一个事件中心。其中 事件中心 是重点。

(2)从关系上看
- 观察者和目标者,是松耦合的关系
- 发布者和订阅者,则完全不存在耦合
(3)从使用角度上看
- 观察者模式,多用于 单个应用内部 (Vue中的数据响应式变化就是观察者模式)
- 发布订阅模式,更多用于 跨应用的模式(比如我们常用的
消息中间件)
1.4 Kafka的概念
看了它大概是个什么样子的,我们再来看它的概念就很好理解了。
官方文档:Apache Kafka
官方描述:Kafka是由Apache软件基金会开发的一个开源流平台,由Scala和Java编写。
Apache Kafka是一个分布式流平台。一个分布式的流平台应该包含3点关键的能力
1. 发布和订阅流数据流,类似于消息队列或者是企业消息传递系统;
2. 以容错的持久化方式存储数据流;
3. 处理数据流。
英文原版
1. Publish and subscribe to streams of records, similar to a message queue or enterprise
messaging system.
2. Store streams of records in a fault-tolerant durable way.
3. Process streams of records as they occur.
重点关键三个部分的关键词:
Publish and subscribe:发布与订阅
Store:存储
Process:处理
通常将Apache Kafka用在两类程序:
1. 建立实时数据管道,以可靠地在系统或应用程序之间获取数据
2. 构建实时流应用程序,以转换或响应数据流

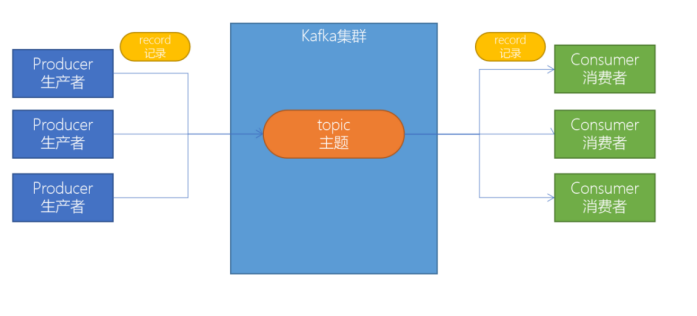
上图,我们可以看到:
1. Producers:可以有很多的应用程序,将消息数据放入到Kafka集群中;
2. Consumers:可以有很多的应用程序,将消息数据从Kafka集群中拉取出来;
3. Connectors:Kafka的连接器可以将数据库中的数据导入到Kafka,也可以将Kafka的数据导出到数据库中;
4. Stream Processors:流处理器可以Kafka中拉取数据,也可以将数据写入到Kafka中。
前面我们了解到,消息队列中间件有很多,为什么我们要选择Kafka?
| 特性 | ActiveMQ | RabbitMQ | Kafka | RocketMQ |
| 所属社区/公司 | Apache | Mozilla Public License | Apache | Apache/Ali |
| 成熟度 | 成熟 | 成熟 | 成熟 | 比较成熟 |
| 生产者-消费者模式 | 支持 | 支持 | 支持 | 支持 |
| 发布-订阅 | 支持 | 支持 | 支持 | 支持 |
| REQUEST-REPLY | 支持 | 支持 | - | 支持 |
| API完备性 | 高 | 高 | 高 | 低(静态配置) |
| 多语言支持 | 支持JAVA优先 | 语言无关 | 支持,JAVA优先 | 支持 |
| 单机呑吐量 | 万级(最差) | 万级 | 十万级 | 十万级(最高) |
| 消息延迟 | - | 微秒级 | 毫秒级 | - |
| 可用性 | 高(主从) | 高(主从) | 非常高(分布式) | 高 |
| 消息丢失 | - | 低 | 理论上不会丢失 | - |
| 消息重复 | - | 可控制 | 理论上会有重复 | - |
| 事务 | 支持 | 不支持 | 支持 | 支持 |
| 文档的完备性 | 高 | 高 | 高 | 中 |
| 提供快速入门 | 有 | 有 | 有 | 无 |
| 首次部署难度 | - | 低 | 中 | 高 |
在大数据技术领域,一些重要的组件、框架都支持Apache Kafka,不论成成熟度、社区、性能、可靠性,Kafka都是非常有竞争力的一款产品。
2.1 Kafka的基本配置与使用(已完成,可忽略)
1. 将Kafka的安装包上传到集群,并解压
cd /export/software/
tar -xvzf kafka_2.12-2.4.1.tgz -C ../server/
cd /export/server/kafka_2.12-2.4.1/2. 修改 server.properties
cd /export/server/kafka_2.12-2.4.1/config
vim server.properties
# 指定broker的id
broker.id=0
# 指定Kafka数据的位置
log.dirs=/export/server/kafka_2.12-2.4.1/data
# 配置zk的三个节点
zookeeper.connect=node1.sjxy.cn:2181,node2.sjxy.cn:2181,node3.sjxy.cn:21813. 将安装好的kafka复制到另外两台服务器
cd /export/server
scp -r kafka_2.12-2.4.1/ node2:$PWD
scp -r kafka_2.12-2.4.1/ node3:$PWD
修改另外两个节点的broker.id分别为1和2
---------node2.sjxy.cn--------------
cd /export/server/kafka_2.12-2.4.1/config
vim server.properties
broker.id=1
--------node3.sjxy.cn--------------
cd /export/server/kafka_2.12-2.4.1/config
vim server.properties
broker.id=2另外,kafka数据位置目录里面有个meta文件也需要对应修改broker.id(下面是node2的)
vim /export/server/kafka/data/meta.properties
cluster.id=xgr8_xgpTiG8GUZZzUUt5Q
version=0
broker.id=14. 配置KAFKA_HOME环境变量
vim /etc/profile
export KAFKA_HOME=/export/server/kafka_2.12-2.4.1
export PATH=:$PATH:${KAFKA_HOME}
分发到各个节点
scp /etc/profile node2:$PWD
scp /etc/profile node3:$PWD
每个节点加载环境变量
source /etc/profile5. 启动服务器
# 启动ZooKeeper
nohup bin/zookeeper-server-start.sh config/zookeeper.properties &
# 启动Kafka
cd /export/server/kafka_2.12-2.4.1
nohup bin/kafka-server-start.sh config/server.properties &
# 测试Kafka集群是否启动成功
bin/kafka-topics.sh --bootstrap-server node1.sjxy.cn:9092 --list2.2 Kafka本课程中使用步骤
2.2.1 启动Kafka集群
在/export/onekey中有一键启停Kafka集群的脚本
./start-kafka.sh
./stop-kafka.sh2.2.2 创建topic
Kafka中所有的消息都是保存在主题中,要生产消息到Kafka,首先必须要有一个确定的主题。
# 创建名为test的主题
bin/kafka-topics.sh --create --bootstrap-server node1.sjxy.cn:9092 --topic test
# 查看目前Kafka中的主题
bin/kafka-topics.sh --list --bootstrap-server node1.sjxy.cn:90922.2.3 生产消息到Kafka
使用Kafka内置的测试程序,生产一些消息到Kafka的test主题中
bin/kafka-console-producer.sh --broker-list node1.sjxy.cn:9092 --topic test2.2.4 从Kafka消费消息
使用下面的命令来消费 test 主题中的消息
bin/kafka-console-consumer.sh --bootstrap-server node1.sjxy.cn:9092 --topic test --from-beginning2.3 使用Kafka Tools操作Kafka
配置见下面

创建topic

编写代码并运行
package com.sjxy.flink.stream.source.customsource
import java.util.Properties
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
import org.apache.kafka.clients.consumer.ConsumerConfig
/*
验证flinkkafkaconsumer如何消费kafka中的数据
*/
object TestFlinkKafkaConsumer {
def main(args: Array[String]): Unit = {
//1 创建一个流处理的运行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 2 添加自定义的数据源 ,泛型限定了从kafka读取数据的类型
//2.1 构建properties对象
val prop = new Properties()
//kafka 集群地址
prop.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "node1:9092,node2:9092")
//消费者组
prop.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "flink")
//动态分区检测
prop.setProperty("flink.partition-discovery.interval-millis", "5000")
//设置kv的反序列化使用的类
prop.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
prop.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
//设置默认消费的偏移量起始值
prop.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest") //从最新处消费
//定义topic
val topic = "test"
//获得了kafkaconsumer对象
val flinkKafkaConsumer: FlinkKafkaConsumer[String] = new FlinkKafkaConsumer[String](topic, new SimpleStringSchema(), prop)
val kafkaDs: DataStream[String] = env.addSource(flinkKafkaConsumer)
//3 打印数据
kafkaDs.print()
//4 启动
env.execute()
}
}
在集群中使用下面命令(生产消息)
/export/server/kafka/bin/kafka-console-producer.sh --broker-list node1:9092 --topic test产生一些数据
 观察IDEA中控制台输出
观察IDEA中控制台输出

数据在源源不断过来表示成功了。















 834
834











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









