







 本文介绍了在目标检测任务中使用YOLOv5进行数据标注的方法,通过labelImg工具创建XML标注文件。接着,详细阐述了如何使用xml2txt脚本将XML批量转换为YOLO所需的TXT格式,确保train和valid文件夹中的图像和标签文件对应一致,满足深度学习模型训练的要求。
本文介绍了在目标检测任务中使用YOLOv5进行数据标注的方法,通过labelImg工具创建XML标注文件。接着,详细阐述了如何使用xml2txt脚本将XML批量转换为YOLO所需的TXT格式,确保train和valid文件夹中的图像和标签文件对应一致,满足深度学习模型训练的要求。
目录
1.数据标注
利用Yolov5进行目标检测的过程中,我们需要对数据进行标注,这里我们利用的是labelImg脚本进行数据标注的。labelImg主要用于yolov5数据标注工具-深度学习文档类资源-CSDN下载
界面如下所示:

按w键进行数据标注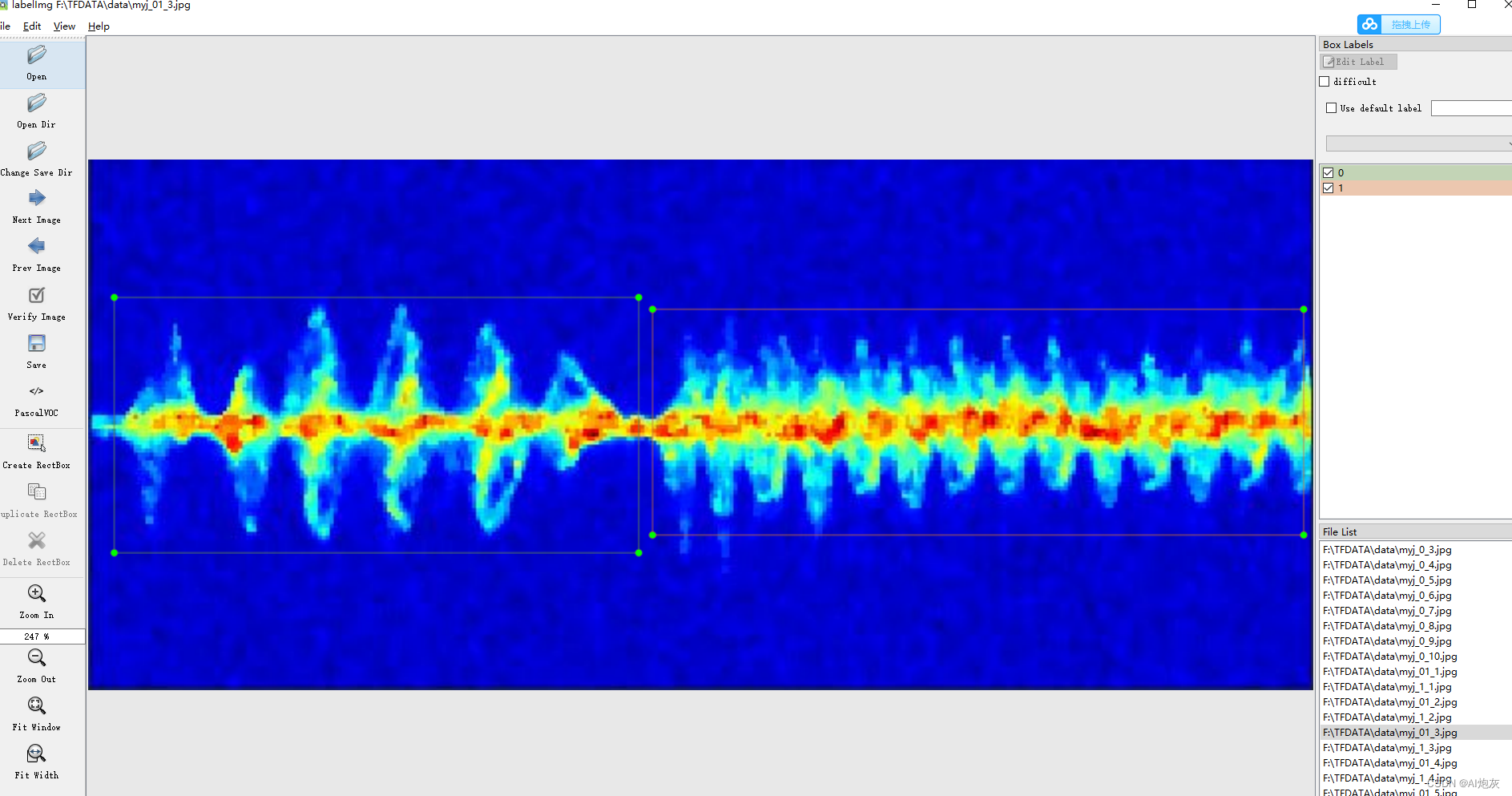
标注后,进行选择保存xml的路径,之后就可以得到标注好的xml文件,如下所示:
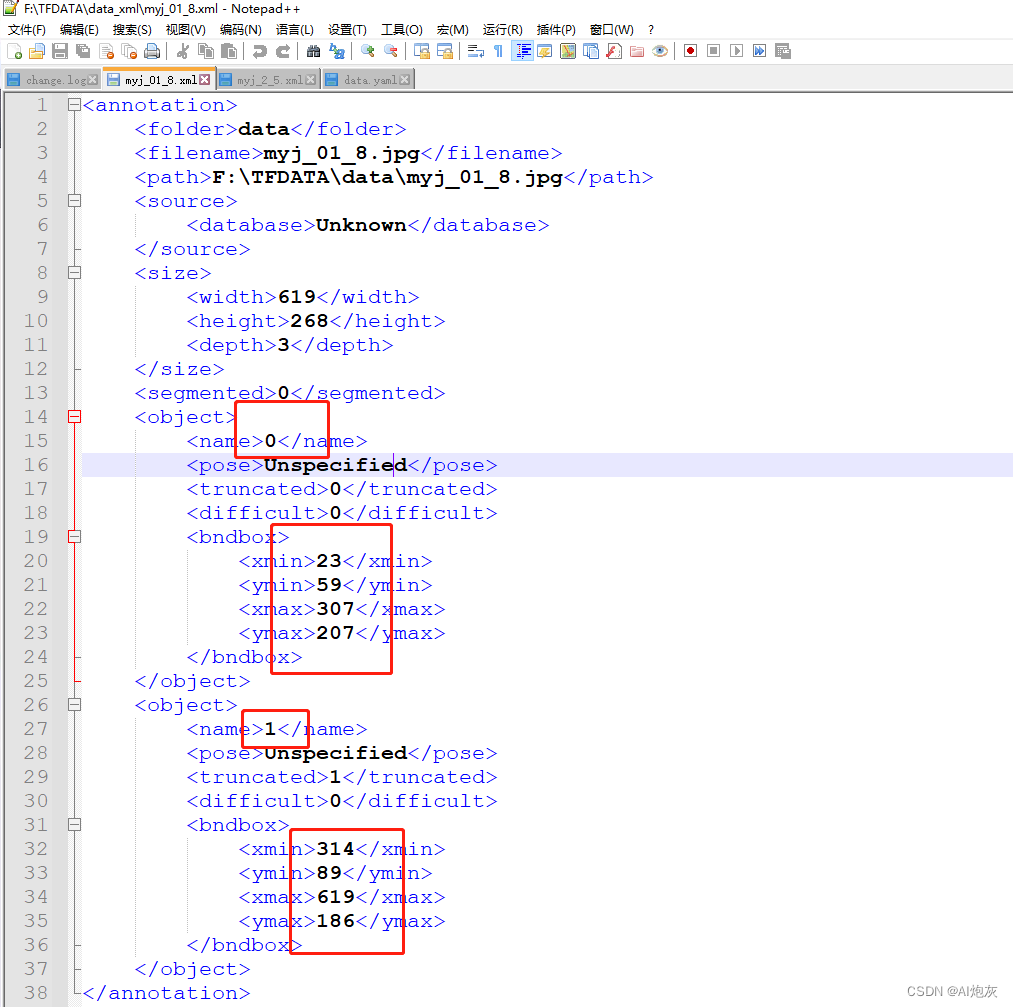
这里面包含了两个类别的不同位置的数据,分别为类别、(x,y,w,h)。对于得到的xml文件进行转为yolo的数据格式即为转为txt文件。这里我们使用了xml2txt脚本。
2.xml批量转为txt文件
文件结构如下所示:
运行yolov5必须要有train、valid、data.yaml配置文件
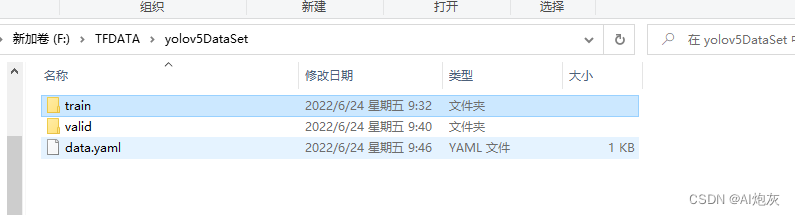
train和valid文件里面必须要有images和labels而且images里面的图片文件(.jpg文件)必须与labels里面的txt文件名字、数量对应
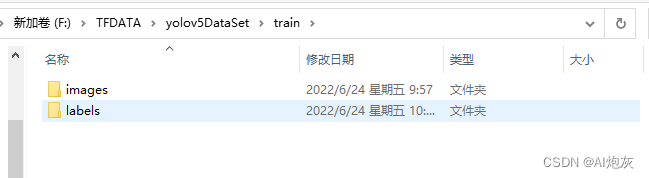
images图像文件如下:
labels中txt标签文件如下所示:
那么xml文件如何批量转化为txt文件呢?如下脚本所示
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import glob
classes = ["0", "1", "2", "3", "4"]
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(image_name):
in_file = open('F:/TFDATA/data_xml/'+image_name[:-3]+'xml') # 保存xml文件的文件夹
out_file = open('F:/TFDATA/yolov5DataSet/train/labels/'+image_name[:-3]+'txt','w') # 保存txt文件的文件夹
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in classes:
print(cls)
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
if __name__ == '__main__':
for image_path in glob.glob("F:/TFDATA/yolov5DataSet/train/images/*.jpg"): # 获取所在文件夹内的文件名
image_name = image_path.split('\\')[-1]
#print(image_path)
convert_annotation(image_name) # 进行转换


















 317
317

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











