







文章:From movement tracks through events to places: Extracting and characterizing significant places from mobility data
作者:Andrienko G, Andrienko N, Hurter C, et al.
来源:Visual Analytics Science and Technology (VAST), 2011 IEEE Conference on. IEEE, 2011: 161-170.
本文针对如下问题:
从轨迹中提取特定事件(可自己定义,如交通堵塞)频繁发生的地点,即重要地点(significant places)。
贡献:
1,阐述了一个工作流,其中每个步骤都是由已有文献的方法构成的,工作流将其连接起来。
2,本方法可以扩展到不能完全存放到内存中的大数据上。
3,提出了一个距离,考虑了空间、时间和其它属性。
step1:从轨迹中提取事件events
events的定义和提取是由交互可视化工具来完成的。
event的属性可包括:
1,移动数据的瞬时、区间、累积属性
2,其它属性如温度、高度等
3,时间属性
4,与时空上下文的关系:时空邻近区间等
一些动态属性可以利用time graph来提取,交互的指定区间后提取。
step2:确定相关地点
这里的地点是指event频繁发生的区域。
除了考虑空间外,还需要考虑其它属性,比如方向。
例如交通拥堵,对一条道路,可能相反方向有完全不同的拥堵情况。
发现区域可以用密度聚类来做。
这里分两个阶段进行:
1,时空聚类,发现events,这里还可以包含其它特征。
2,对第一阶段的events进行空间密度聚类,发现event频繁发生的区域,即place。
这里的聚类定义了一个距离函数,包括了空间、时间和属性。
聚类使用DBSCAN算法。
聚类结果用凸包或者空间缓冲区表示
step3:聚集events和轨迹
events的时空聚集可以用来研究不同地点事件发生的时间模式。
这里有两种聚集:
1,每个地点的聚集:每个地点的访问次数、不同访问者的人数、访问时间等
2,地点pari之间的聚集:地点1到地点2的move数目、地点1到地点2的个体数目等,形成flow。
step4:分析聚集数据
利用统计学、数据挖掘方法来分析。
扩展性问题
这里数据是存储在RAM中的,显示了数据大小。
当然如果数据存放在MOD(移动数据库)中,可以实现其可扩展性。
visual query转化成MOD query进行。聚类可以实现在数据库中,或者用滑动窗口方向实现。
实例分析:
米兰的车辆轨迹
作者:Andrienko G, Andrienko N, Hurter C, et al.
来源:Visual Analytics Science and Technology (VAST), 2011 IEEE Conference on. IEEE, 2011: 161-170.
本文针对如下问题:
从轨迹中提取特定事件(可自己定义,如交通堵塞)频繁发生的地点,即重要地点(significant places)。
贡献:
1,阐述了一个工作流,其中每个步骤都是由已有文献的方法构成的,工作流将其连接起来。
2,本方法可以扩展到不能完全存放到内存中的大数据上。
3,提出了一个距离,考虑了空间、时间和其它属性。
step1:从轨迹中提取事件events
events的定义和提取是由交互可视化工具来完成的。
event的属性可包括:
1,移动数据的瞬时、区间、累积属性
2,其它属性如温度、高度等
3,时间属性
4,与时空上下文的关系:时空邻近区间等
一些动态属性可以利用time graph来提取,交互的指定区间后提取。
step2:确定相关地点
这里的地点是指event频繁发生的区域。
除了考虑空间外,还需要考虑其它属性,比如方向。
例如交通拥堵,对一条道路,可能相反方向有完全不同的拥堵情况。
发现区域可以用密度聚类来做。
这里分两个阶段进行:
1,时空聚类,发现events,这里还可以包含其它特征。
2,对第一阶段的events进行空间密度聚类,发现event频繁发生的区域,即place。
这里的聚类定义了一个距离函数,包括了空间、时间和属性。
聚类使用DBSCAN算法。
聚类结果用凸包或者空间缓冲区表示
step3:聚集events和轨迹
events的时空聚集可以用来研究不同地点事件发生的时间模式。
这里有两种聚集:
1,每个地点的聚集:每个地点的访问次数、不同访问者的人数、访问时间等
2,地点pari之间的聚集:地点1到地点2的move数目、地点1到地点2的个体数目等,形成flow。
step4:分析聚集数据
利用统计学、数据挖掘方法来分析。
扩展性问题
这里数据是存储在RAM中的,显示了数据大小。
当然如果数据存放在MOD(移动数据库)中,可以实现其可扩展性。
visual query转化成MOD query进行。聚类可以实现在数据库中,或者用滑动窗口方向实现。
实例分析:
米兰的车辆轨迹
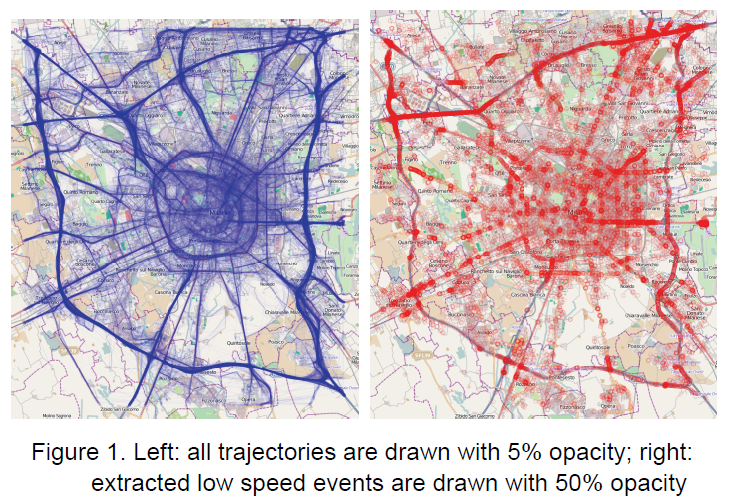
下图为米兰车辆轨迹,左为所有车辆,用透明度可视化数据,右为提取出的低速events。
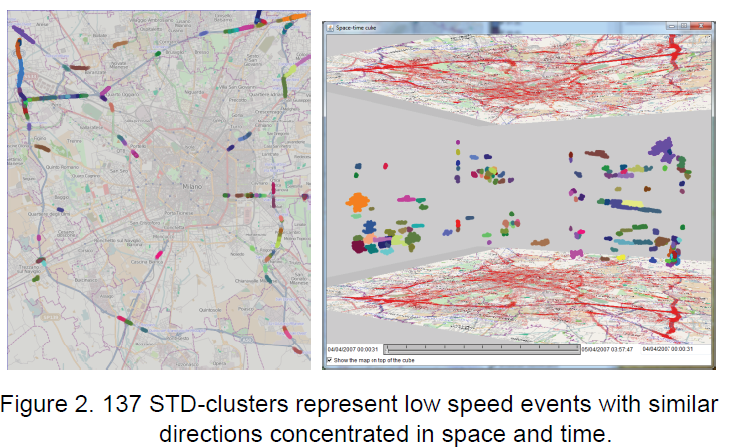
下图为提取的时空聚簇,考虑了低速和方向,并且在时空上邻近。
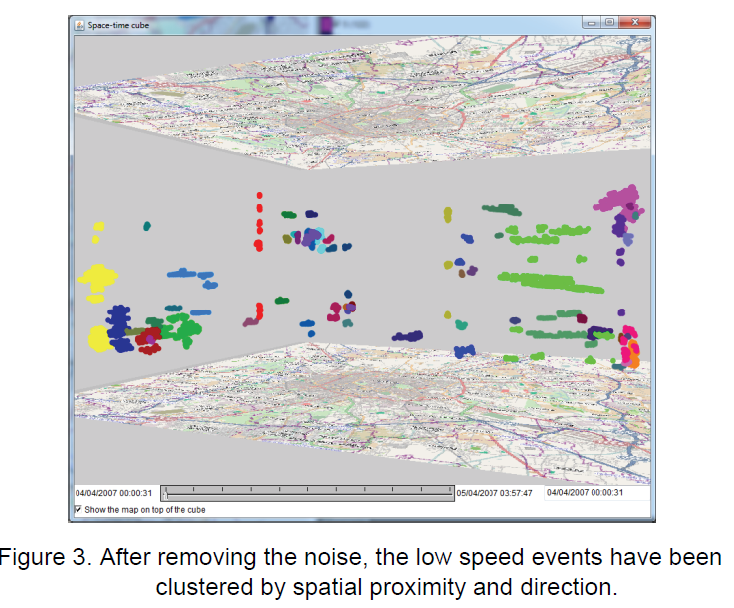
下图为移除了时空聚簇异常后,对时空聚簇进行空间聚类的结果。
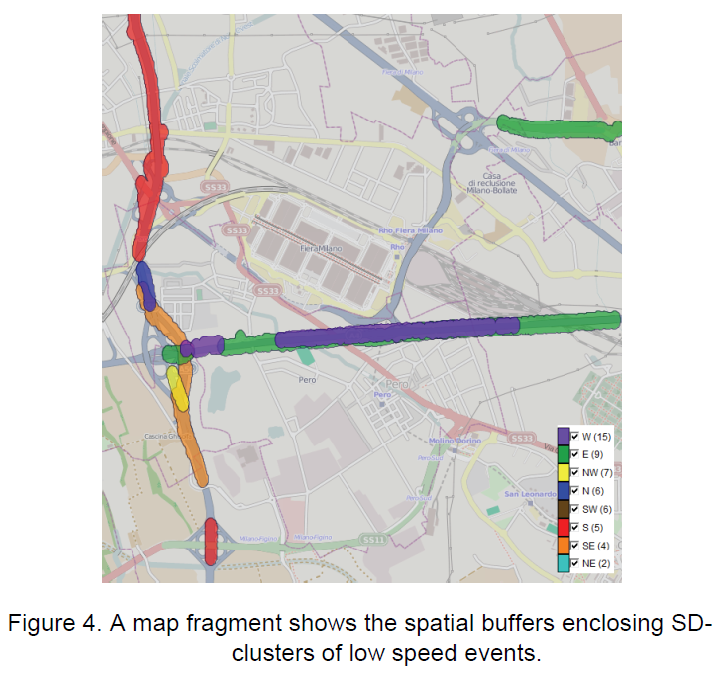
下图在地图上显示低速的空间聚簇形状。
时空聚集后,某一区域的events的不同方向的events的时间模式。
八个颜色是八个不同的方向。
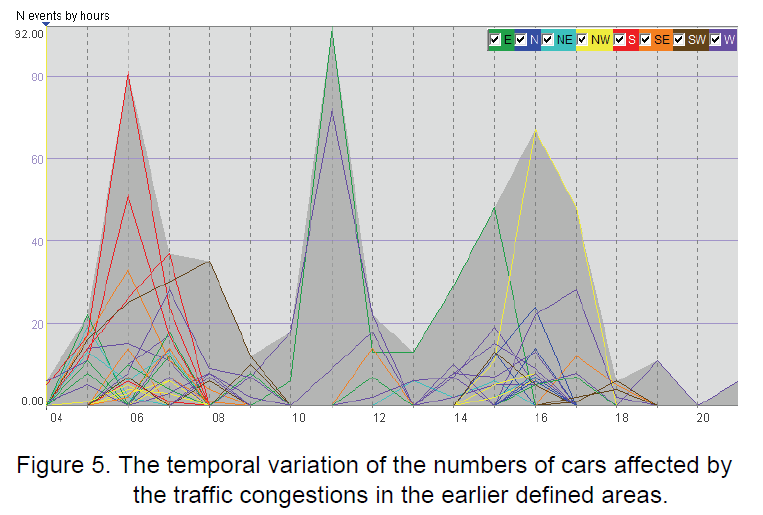
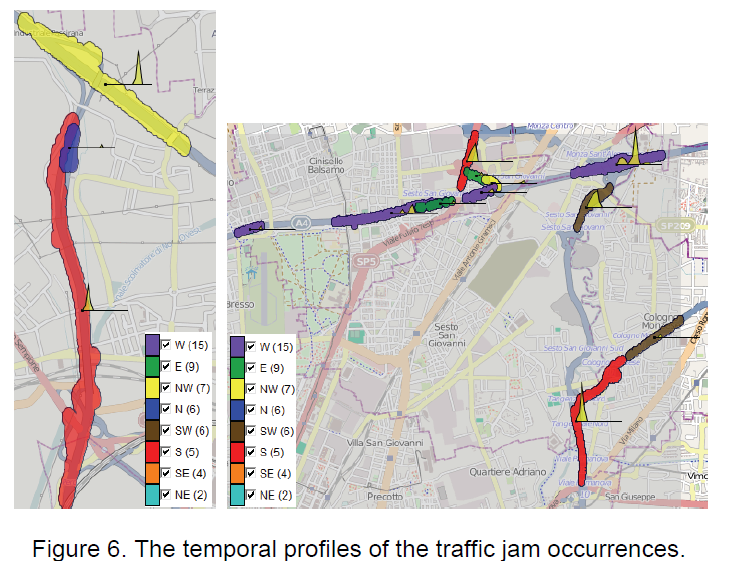
下图为交通拥堵聚簇的时间模式,每个聚簇上面的time graph显示了其时间的变化。
该方法还可以对其它数据适用,海洋上面,可以定义anchoring areas 和areas of major turns and crossings。
未来:
将该功能与MOD进行集成。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









