









背景 :
因为工作需要用C/C++实现四参数拟合算法,在网上搜了一圈,没找到合适的现成代码,就是现成其他语言的代码,也没有找到完整实现的,效果最好的要数L4P 的matlab代码,可惜它最终调用的fit函数是matlab内置的,看不到具体实现,大概是采用拟牛顿一类的算法,总之,最后都想到去C++数值算法中找,也无功而返,没办法,只能自己实现了。这里节省时间,只是用matlab验证。
目标 :
给定数据(x,y),找出(A,B,C,D),使得拟合方程的决定系数R最大或者均方根误差(RMSE)达到最小。
y
=
D
+
A
−
D
1
+
(
x
C
)
B
y = D+\tfrac{A-D}{1+(\frac{x}{C})^B}
y=D+1+(Cx)BA−D
算法终止条件:
过程 :
这是一个典型的非线性最小二乘问题,由于参数不多,本想尽可能用简单的算法去实现,结果无论是坐标轮换法还是随机梯度下降法,对某些数据收敛速度实在是慢,在实际中应用会存在问题。循序渐进,先看看牛顿法的效果,后面再扩展到高斯牛顿,L-M,拟牛顿法。这里实现的牛顿法,实际上不是一种最小二乘算法,他的目标和高斯牛顿等算法并不一样,因此结果也有一些出入(对照L4P算法)。
运算流程
牛顿法简介

牛顿方法最早估计是用于求一元方程f(x) = 0的根,它的几何意义也很明显。假设x0作为起点,在方程曲线在x0处画切线,用切线与x轴相交的位置作为下一个迭代点,直到找到方程的根。
假设方程初始值为
x
0
x_0
x0,我们希望找到一个
Δ
\Delta
Δ能使得
f
(
x
0
+
Δ
)
=
0
f(x_0+\Delta )=0
f(x0+Δ)=0
将
f
(
x
0
+
Δ
)
f(x_0+\Delta )
f(x0+Δ)做一阶泰勒展开得到
f
(
x
0
+
Δ
)
≈
f
(
x
0
)
+
f
′
(
x
0
)
Δ
=
0
⇒
x
1
−
x
0
=
Δ
=
−
f
(
x
0
)
f
′
(
x
0
)
⇒
x
1
=
x
0
−
f
(
x
0
)
f
′
(
x
0
)
\\ \\ f(x_0+\Delta )\approx f(x_0)+f^{'}(x_0) \Delta=0 \\ \Rightarrow x_1-x_0 = \Delta = - \frac{f(x_0)}{f^{'}(x_0)} \\ \Rightarrow x_1 = x_0- \frac{f(x_0)}{f^{'}(x_0)}
f(x0+Δ)≈f(x0)+f′(x0)Δ=0⇒x1−x0=Δ=−f′(x0)f(x0)⇒x1=x0−f′(x0)f(x0)
这样不断迭代,可以得到最终的函数解。我们可以大致发现牛顿法存在的两个问题,1. 如果
Δ
\Delta
Δ太大,会·导致泰勒展开严重不准确 2.如果初始点不在方程解附近,有可能导致无法收敛。
四参数拟合之牛顿法思路
牛顿法目标,对于所有数据
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi),找到一组参数
[
A
,
B
,
C
,
D
]
[A,B,C,D]
[A,B,C,D]
满足以下方程
F
(
A
,
B
,
C
,
D
,
x
i
)
=
f
(
A
,
B
,
C
D
,
x
i
)
−
y
i
=
0
f
(
A
,
B
,
C
,
D
,
x
i
)
=
D
+
A
−
D
1
+
(
x
i
C
)
B
F(A,B,C,D,x_i) = f(A,B,CD,x_i)-y_i = 0\\ f(A,B,C,D,x_i)= D+\tfrac{A-D}{1+(\frac{x_i}{C})^B}
F(A,B,C,D,xi)=f(A,B,CD,xi)−yi=0f(A,B,C,D,xi)=D+1+(Cxi)BA−D
将
F
(
A
,
B
,
C
,
D
,
x
i
)
F(A,B,C,D,x_i)
F(A,B,C,D,xi)做一阶泰勒展开
F
(
A
+
Δ
A
,
B
+
Δ
B
,
C
+
Δ
C
,
D
+
Δ
D
,
x
i
)
=
F
(
A
,
B
,
C
,
D
,
x
i
)
+
∂
F
∂
A
Δ
A
+
∂
F
∂
B
Δ
B
+
∂
F
∂
C
Δ
C
+
∂
F
∂
D
Δ
D
=
0
F(A+\Delta A,B+\Delta B,C+\Delta C,D+\Delta D,x_i) = F(A,B,C,D,x_i)+\frac{\partial F }{\partial A}\Delta A+\frac{\partial F }{\partial B}\Delta B+\frac{\partial F }{\partial C}\Delta C+\frac{\partial F }{\partial D}\Delta D = 0
F(A+ΔA,B+ΔB,C+ΔC,D+ΔD,xi)=F(A,B,C,D,xi)+∂A∂FΔA+∂B∂FΔB+∂C∂FΔC+∂D∂FΔD=0
对于每一个数据
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi),我们可以计算得到它的偏导数,作为一个矩阵JM的第i行数据,假设有m组数据,则有
J
M
=
[
∂
F
∂
A
1
⋯
∂
F
∂
D
1
⋮
⋱
⋮
∂
f
∂
A
m
⋯
∂
F
∂
D
m
]
JM=\begin{bmatrix} \frac{\partial F}{\partial A_1}&\cdots&\frac{\partial F}{\partial D_1}\\ \vdots&\ddots&\vdots\\ \frac{\partial f}{\partial A_m}&\cdots&\frac{\partial F}{\partial D_m} \end{bmatrix}
JM=⎣⎢⎡∂A1∂F⋮∂Am∂f⋯⋱⋯∂D1∂F⋮∂Dm∂F⎦⎥⎤
使用
F
(
A
,
B
,
C
,
D
,
x
i
)
F(A,B,C,D,x_i)
F(A,B,C,D,xi),计算得到剩余函数向量Res
R
e
s
(
i
)
=
F
(
A
,
B
,
C
,
D
,
x
i
)
Res(i) = F(A,B,C,D,x_i)
Res(i)=F(A,B,C,D,xi)
利用最小二乘法,估计更新梯度值
J
M
∗
[
Δ
A
Δ
B
Δ
C
Δ
D
]
=
−
R
e
s
JM*\begin{bmatrix}\Delta A\\\Delta B\\\Delta C\\\Delta D\end{bmatrix} = -Res
JM∗⎣⎢⎢⎡ΔAΔBΔCΔD⎦⎥⎥⎤=−Res
具体实现
- 初始点估计
可以参考文献1,2的做法。关于A,D的估计值都差不多,就是用分别用min(y),max(y), B,C的估计就不太一样。文献1是估计出A,D后,对B,C做一个最小二乘预测,里面的一些公式应该是错误的。而文献2的做法不太直观,没理解它的思路,而且测试效果不太好。
我这里的牛顿算法实现算法还是很依赖初始点的,用的是文献1的初始算法,用文献2的算法,有一些数据存在无法收敛。L4P算法很稳定,不知道是如何做到的 - 更新权值速度上,加入了一个λ系数,跟机器学习的学习速率其实是一回事情。这里的λ是一个常数,介于0~1之间,还有更好的更新方法,后面再做介绍。
- 达到收敛或者最大运算次数,退出
代码使用matlab的symbolic运算,速度要慢一些,将这些替换后,速度会快很多
以下是matlab测试代码
clear;
load census;
syms A B C D x;
y =D+(A-D)/(1+(x/C)^B);
%grad
py_A = diff(y,A);
py_B = diff(y,B);
py_C = diff(y,C);
py_D = diff(y,D);
x1 = cdate ;
y1 = pop ;
lamda = 0.3;
%init a,b,c,d
d = max(y1)+1;
a = min(y1)-0.1;
y2 = log((y1-d)./(a-y1));
x2 = log(x1);
[curve2,gof2] = fit(x2,y2, 'poly1');
b = -curve2.p1;
c = exp(curve2.p2/b);
%newton
for k = 1:1:1000
fy = [];
JacobiMatrix = ones(length(x1),4);
w=[a,b,c,d];
[res,R,fit] = evaluateFit(y1,x1,w);
if R>0.997
return;
end
for i = 1:1:length(x1)
fy(i,:) = d+(a-d)/(1+(x1(i)/c)^b);
JacobiMatrix(i,1) = double(subs(py_A,symvar(py_A),[b,c,x1(i)]));
JacobiMatrix(i,2) = double(subs(py_B,symvar(py_B),[a,b,c,d,x1(i)]));
JacobiMatrix(i,3) = double(subs(py_C,symvar(py_C),[a,b,c,d,x1(i)]));
JacobiMatrix(i,4) = double(subs(py_D,symvar(py_D),[b,c,x1(i)]));
end
delta_w = JacobiMatrix\(y1-fy);
%update a b c d
a = a +lamda*delta_w(1);
b = b+lamda*delta_w(2);
c = c +lamda*delta_w(3);
d= d +lamda*delta_w(4);
end
function [res,R2,fit] = evaluateFit(y,x,w)
fit = getFittingValue(x,w);
res = norm(y-fit)/sqrt(length(fit));
yu = mean(y);
R2 = 1 - norm(y-fit)^2/norm(y - yu)^2;
end
function fit = getFittingValue(x,w)
len = length(x);
fit = ones(len,1);
for i = 1:1:len
fit(i) = hypothesis(x(i),w);
end
end
function val = hypothesis(x,w)
a = w(1);b= w(2);c= w(3);d= w(4);
val = d+(a-d)/(1+(x/c)^b);
end
结果
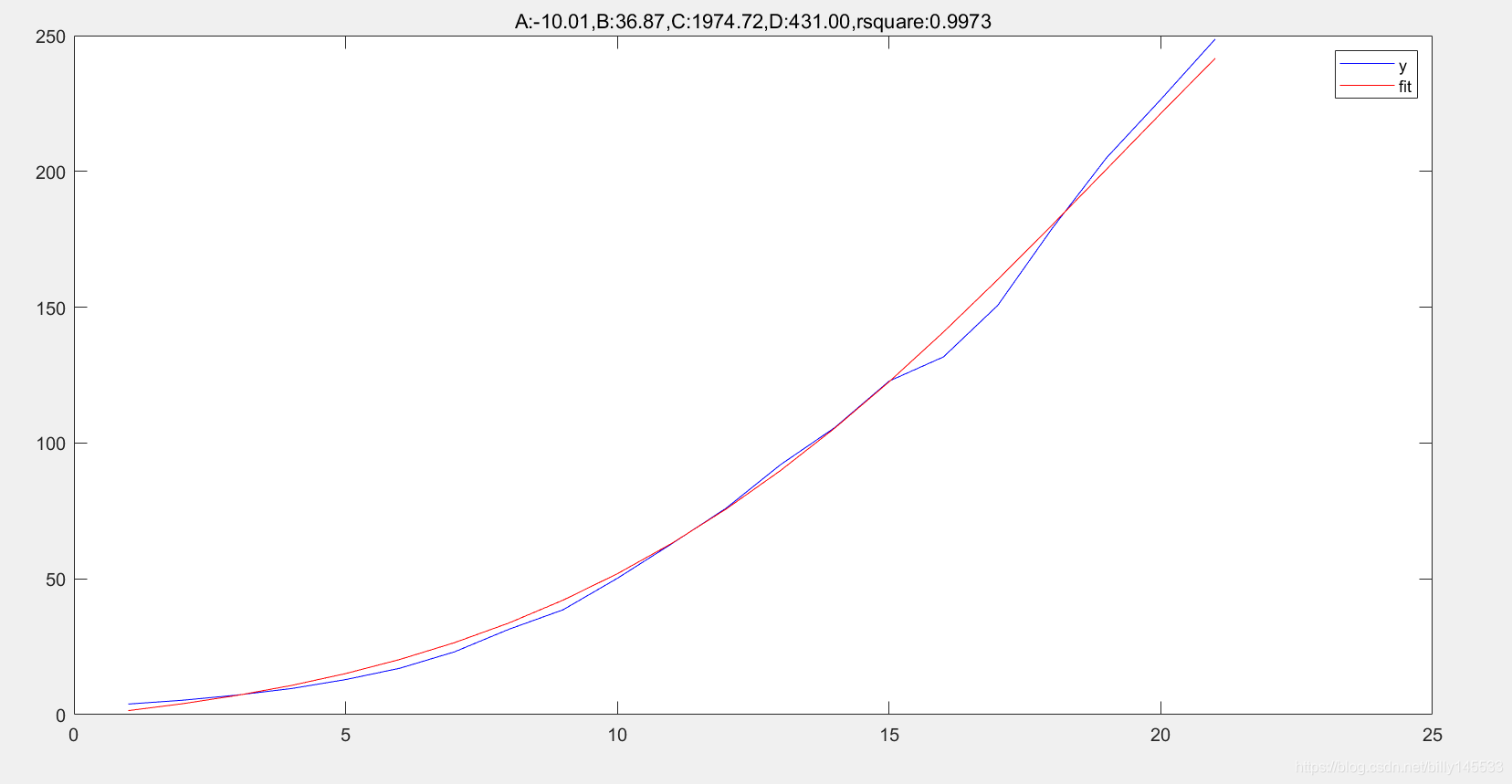
对比L4P的执行结果

尽管在拟合程度上,两者差不多,但是由于目标并不相同,二者的结果还是存在比较大的出入
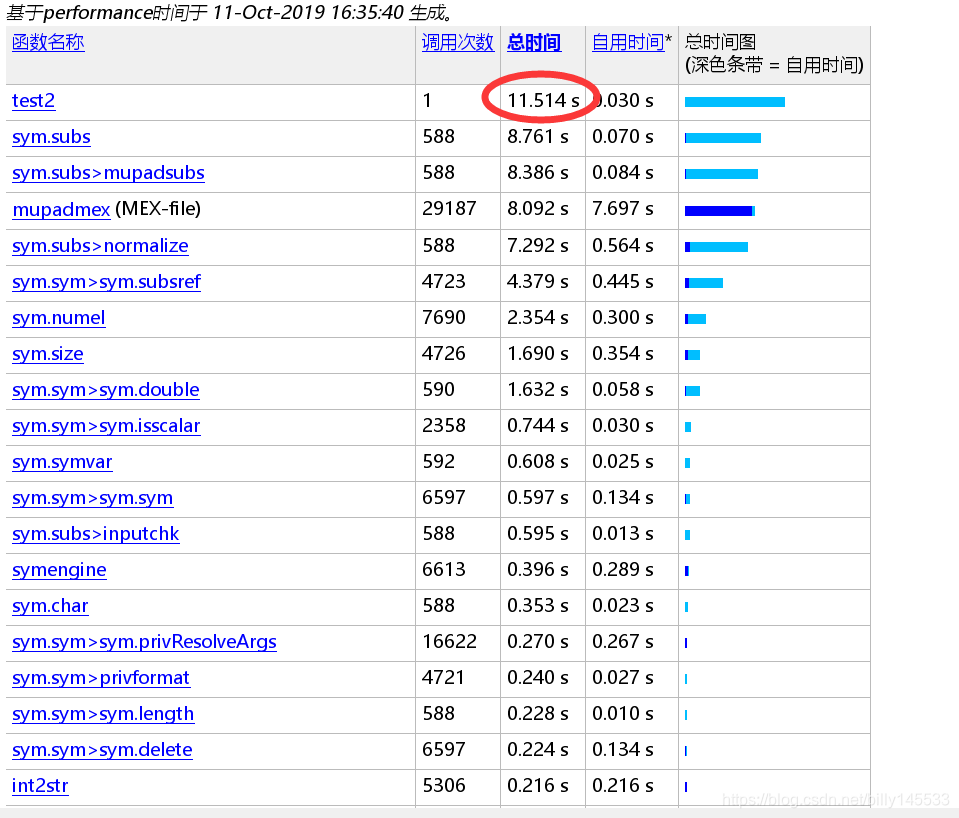
在时间上,大部分时间都耗费在symbolic运算上,后续在高斯牛顿法上把symbolic运算去掉再试试。
上述算法,只在两笔数据上测试过,所以,稳不稳定也不好说,想要转为C/C++的慎用
参考文献
[^1]1. 四参数拟合需求及详细算法
2. L4P代码

















 2907
2907

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









