






知识蒸馏(模型压缩)技术
一、什么是知识蒸馏
知识蒸馏(Knowledge Distillation)是一种模型压缩技术,通过训练小型“学生模型”模仿大型“教师模型”的输出分布,实现知识迁移。其核心在于利用教师模型的软标签(概率分布)而非硬标签,传递更丰富的类别间关系信息。14年NIPS上由Google 的Hinton发表的《Distilling the Knowledge in a Neural Network》是首次提出知识蒸馏这个概念。
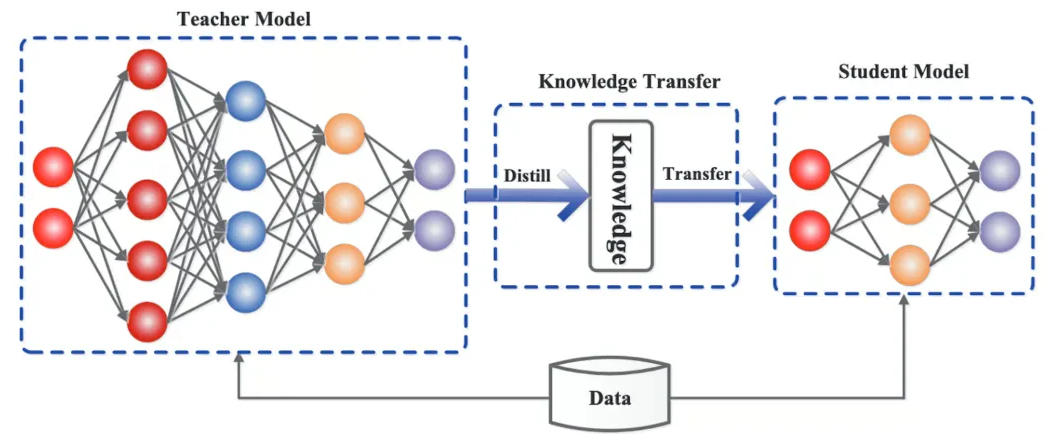
蒸馏过程通常包括以下几个步骤:
- 教师模型训练:首先,训练一个性能强大的大模型,这个模型通常具有大量的参数,能在各种任务上提供优异的性能。这个大模型即为“教师模型”。
- 学生模型设计:学生模型通常较小,参数量比教师模型少得多。其目的是在保证模型精度的同时,减少计算资源消耗,提高推理速度。
- 蒸馏过程:在训练学生模型时,采用教师模型的输出作为监督信号。不同于传统的监督学习,蒸馏技术利用教师模型的软标签(Soft Labels)而非硬标签。软标签通常是教师模型的输出概率分布,它携带了更多的信息,例如类别之间的相似度,这使得学生模型能够在较少的数据和参数的情况下,学到更加丰富的知识。
- 优化与精炼:学生模型通过模拟教师模型的行为,逐渐学习到其潜在的知识结构。通过反复训练,学生模型在大部分情况下能够接近或达到教师模型的性能,同时具有更高的计算效率和更小的内存占用。
二、主要作用
模型压缩: 蒸馏技术可以将大型模型压缩成较小的模型,使得其在移动设备或计算资源有限的环境中依然可以发挥较高的性能。
知识迁移: 学生模型不仅继承了教师模型的知识,还能在一些情况下进行自我优化,提升性能。
推理效率: 由于学生模型的规模较小,它在推理时所需的计算资源和时间都显著减少,有助于加速推理过程,尤其适用于实时应用场景。
大模型在场景落地时,会存在部署推理成本高、专业知识不足、幻觉问题严重等问题,因此在专业级市场,需要基于蒸馏、微调、RAG等手段,提升大模型在垂直领域的表现。
模型量化
一、什么是模型量化
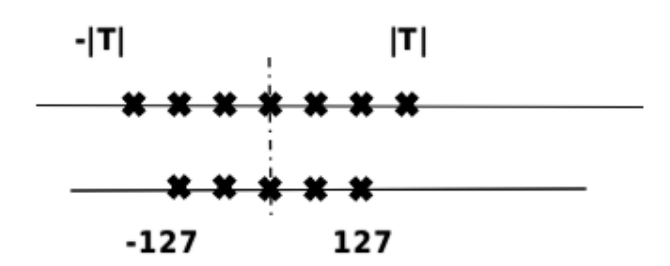
模型量化(Quantization)是指以较低的推理精度损失将连续取值(通常为float32或者大量可能的离散值)的浮点型权重近似为有限多个离散值(通常为int8)的过程。通过以更少的位数表示浮点数据,模型量化可以减少模型尺寸,进而减少在推理时的内存消耗,并且在一些低精度运算较快的处理器上可以增加推理速度。具体如下图所示,[-T, T]是量化前的数据范围,[-127, 127]是量化后的数据范围。
量化将模型参数的表示从浮点数精度降低为整数或低精度形式,以减小模型的存储和计算开销。
二、主要作用
1、减小模型大小
如 int8 量化可减少 75% 的模型大小,int8 量化模型大小一般为 32 位浮点模型大小的 1/4:
- 减少存储空间:在端侧存储空间不足时更具备意义。
- 减少内存占用:更小的模型当然就意味着不需要更多的内存空间。
- 减少设备功耗:内存耗用少了推理速度快了自然减少了设备功耗;
2、加快推理速度
访问一次 32 位浮点型可以访问四次 int8 整型,整型运算比浮点型运算更快;CPU 用 int8 计算的速度更快
3、某些硬件加速器如 DSP/NPU 只支持 int8
比如有些微处理器属于 8 位的,低功耗运行浮点运算速度慢,需要进行 8bit 量化。
模型量化主要意义就是加快模型端侧的推理速度,并降低设备功耗和减少存储空间。
MoE混合专家模型技术
训练大型语言模型(LLM)通常需要大量的计算资源,这对许多组织和研究人员来说是一个很高的门槛。混合专家(MoE)技术通过将大型模型分解成更小的、专门的网络来解决这一难题。
MoE(Mixture of Experts,混合专家模型)是一种通过动态选择子模型(专家)处理输入数据的深度学习架构,旨在提升模型性能与效率。其核心思想是“术业有专攻”,即让不同专家专注于特定任务,通过门控网络动态调度专家资源,在降低计算成本的同时实现高性能输出。
一、什么是MoE
想象一个人工智能模型是一个专家团队,每个人都有自己独特的专业知识。混合专家(MoE)模型通过将复杂任务划分为(称为专家的)更小的专业网络来运行这一原则。每个专家专注于问题的一个特定方面,使模型能够更有效、更准确地解决任务。就像医生负责医疗问题,技师负责汽车问题,厨师负责烹饪一样,每个专家都有自己擅长的事情。通过合作,这些专家可以更有效地解决更广泛的问题。

二、主要作用
计算高效性。 MoE通过动态分配任务,减少冗余计算。例如,DeepSeek-MoE 16B的推理仅激活2.8B参数,计算量比同等性能的稠密模型降低60%。
参数可扩展性。一是专家的多样化能力使MoE模型具有高度的灵活性,通过召集具有专业能力的专家,MoE模式可以承担更广泛的任务。二是将复杂的问题分解成更小、更易于管理的任务,有助于MoE模型处理日益复杂的输入。三是支持扩展到数百甚至上千个专家,模型容量大幅提升(如谷歌的Switch Transformer达1.6万亿参数),同时保持分布式并行计算的可行性。
任务适应性。一是MoE的“分而治之”方法,其中任务分别执行,增强了模型对故障的容错弹性。如果一个专家遇到问题,并不一定会影响整个模型的功能。二是在多模态、复杂推理等场景中,MoE通过专家分工实现精准处理,例如GPT-4的MoE架构能分别处理文本生成、逻辑推理和图像分析任务。
MHA多头注意力机制技术
多头注意力机制(Multi-Head Attention)是深度学习领域中一种重要的技术,最早由Vaswani等人在2017年的论文《Attention is All You Need》中提出。
多头注意力(Multi-Head Attention)是一种在Transformer模型中被广泛采用的注意力机制扩展形式,它通过并行地运行多个独立的注意力机制来获取输入序列的不同子空间的注意力分布,从而更全面地捕获序列中潜在的多种语义关联。
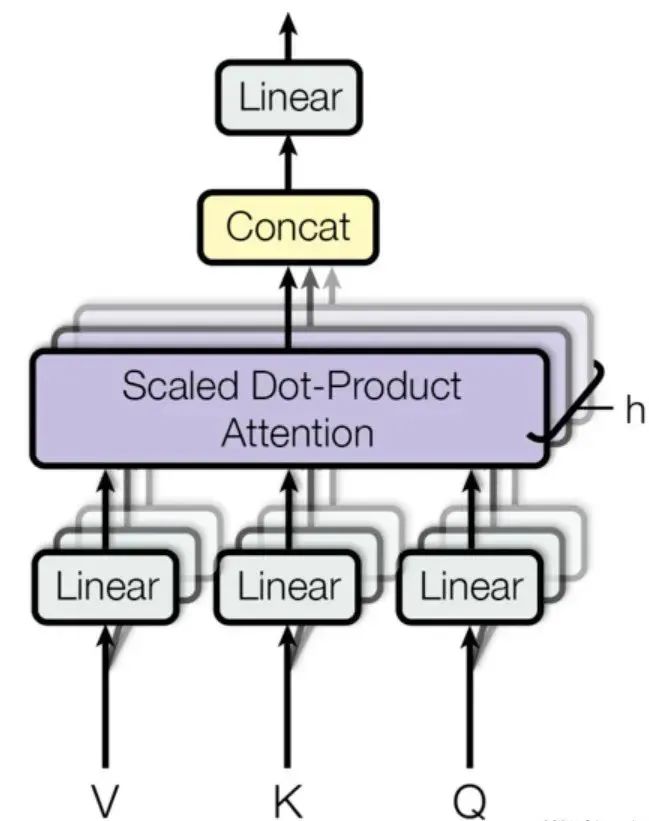
在多头注意力中,输入序列首先通过三个不同的线性变换层分别得到Query、Key和Value。然后,这些变换后的向量被划分为若干个“头”,每个头都有自己独立的Query、Key和Value矩阵。对于每个头,都执行一次Scaled Dot-Product Attention(缩放点积注意力)运算,即:
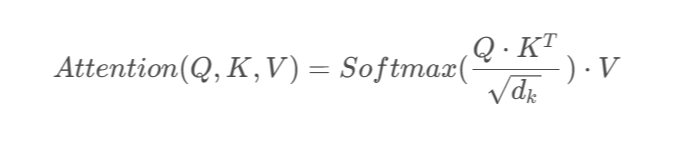
最后,所有头的输出会被拼接(concatenate)在一起,然后再通过一个线性层进行融合,得到最终的注意力输出向量。
通过这种方式,多头注意力能够并行地从不同的角度对输入序列进行注意力处理,提高了模型理解和捕捉复杂依赖关系的能力。在实践中,多头注意力能显著提升Transformer模型在自然语言处理和其他序列数据处理任务上的性能。
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~

👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。


👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。

👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。

👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。

👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

















 415
415

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









