







这几天突然对神经网络有兴趣了,就花了两三天的时间学习了一下BP神经网络。开门见山,先把github上的代码demo放上去,先了解一下他们是如何构建一个BP神经网络的。
然后就是一些我对BP神经网络的算法的一些总结。
- #-*- coding:utf-8 -*-
- import numpy as np
- import matplotlib.pyplot as plt
- import matplotlib
- from sklearn.datasets import make_moons
- from sklearn import linear_model
- import sklearn
- np.random.seed(0)
- X,y=sklearn.datasets.make_moons(200,noise=0.20)
- plt.scatter(X[:,0],X[:,1],s=40,c=y,cmap=plt.cm.Spectral)
- #定义决策边界函数
- def plot_decision_boundary(pred_func):
- # Set min and max values and give it some padding
- x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
- y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
- h = 0.01
- # Generate a grid of points with distance h between them
- xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
- # Predict the function value for the whole gid
- Z = pred_func(np.c_[xx.ravel(), yy.ravel()])
- Z = Z.reshape(xx.shape)
- # Plot the contour and training examples
- plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral)
- plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Spectral)
- #训练逻辑回归分类器
- clf=sklearn.linear_model.LogisticRegressionCV()
- clf.fit(X,y)
- plot_decision_boundary(lambda x:clf.predict(x))
- plt.title('Logistic Regression')
- # plt.show()
- #
- num_examples = len(X) # 训练集大小
- nn_input_dim = 2 # 输入层节点数
- nn_output_dim = 2 # 输出层节点数
- # 梯度下降参数
- epsilon = 0.01 # 学习率
- reg_lambda = 0.01 # 规范化强度
- #定义损失函数
- def calculate_loss(model):
- W1, b1, W2, b2 = model['W1'], model['b1'], model['W2'], model['b2']
- # 用于计算预测值的前向传播
- z1 = X.dot(W1) + b1
- a1 = np.tanh(z1)
- z2 = a1.dot(W2) + b2
- exp_scores = np.exp(z2)
- probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
- # 计算损失
- corect_logprobs = -np.log(probs[range(num_examples), y])
- data_loss = np.sum(corect_logprobs)
- #添加正则化的损失,可选可不选,为了陷入过拟合
- data_loss += reg_lambda/2 * (np.sum(np.square(W1)) + np.sum(np.square(W2)))
- return 1./num_examples * data_loss
- #我们还要实现一个用于计算输出的辅助函数。它会通过定义好的前向传播方法来返回拥有最大概率的类别
- def predict(model, x):
- W1, b1, W2, b2 = model['W1'], model['b1'], model['W2'], model['b2']
- # 正向传播
- z1 = x.dot(W1) + b1
- a1 = np.tanh(z1)
- z2 = a1.dot(W2) + b2
- exp_scores = np.exp(z2)
- probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
- return np.argmax(probs, axis=1)
- #构建模型
- def build_model(nn_hdim, num_passes=20000, print_loss=False):
- #将参数初始化为随机值。我们需要学习这些。
- np.random.seed(0)
- W1 = np.random.randn(nn_input_dim, nn_hdim) / np.sqrt(nn_input_dim)
- b1 = np.zeros((1, nn_hdim))
- W2 = np.random.randn(nn_hdim, nn_output_dim) / np.sqrt(nn_hdim)
- b2 = np.zeros((1, nn_output_dim))
- # 这是用于最终反馈结果的变量
- model = {}
- # 批量梯度下降.
- for i in xrange(0, num_passes):
- # 前向传播
- z1 = X.dot(W1) + b1
- a1 = np.tanh(z1)
- z2 = a1.dot(W2) + b2
- exp_scores = np.exp(z2)
- probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
- # 反向传播
- delta3 = probs
- delta3[range(num_examples), y] -= 1
- dW2 = (a1.T).dot(delta3)
- db2 = np.sum(delta3, axis=0, keepdims=True)
- delta2 = delta3.dot(W2.T) * (1 - np.power(a1, 2))
- dW1 = np.dot(X.T, delta2)
- db1 = np.sum(delta2, axis=0)
- # A添加规范项 (b1 和b2 没有规范项)
- dW2 += reg_lambda * W2
- dW1 += reg_lambda * W1
- # 梯度下降参数更新
- W1 += -epsilon * dW1
- b1 += -epsilon * db1
- W2 += -epsilon * dW2
- b2 += -epsilon * db2
- # 将参数赋到model中
- model = { 'W1': W1, 'b1': b1, 'W2': W2, 'b2': b2}
- # 选择性打印损失
- # 这项操作代价较大,因为它要用到整个数据集,所以我们会降低使用频率。
- if print_loss and i % 1000 == 0:
- print "Loss after iteration %i: %f" %(i, calculate_loss(model))
- return model
- # 创建一个含有三层隐含层的模型
- model = build_model(3, print_loss=True)
- # 绘制决策边界
- plot_decision_boundary(lambda x: predict(model, x))
- plt.title("Decision Boundary for hidden layer size 3")
- plt.show()
#-*- coding:utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
from sklearn.datasets import make_moons
from sklearn import linear_model
import sklearn
np.random.seed(0)
X,y=sklearn.datasets.make_moons(200,noise=0.20)
plt.scatter(X[:,0],X[:,1],s=40,c=y,cmap=plt.cm.Spectral)
#定义决策边界函数
def plot_decision_boundary(pred_func):
# Set min and max values and give it some padding
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
h = 0.01
# Generate a grid of points with distance h between them
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
# Predict the function value for the whole gid
Z = pred_func(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# Plot the contour and training examples
plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Spectral)
#训练逻辑回归分类器
clf=sklearn.linear_model.LogisticRegressionCV()
clf.fit(X,y)
plot_decision_boundary(lambda x:clf.predict(x))
plt.title('Logistic Regression')
# plt.show()
#
num_examples = len(X) # 训练集大小
nn_input_dim = 2 # 输入层节点数
nn_output_dim = 2 # 输出层节点数
# 梯度下降参数
epsilon = 0.01 # 学习率
reg_lambda = 0.01 # 规范化强度
#定义损失函数
def calculate_loss(model):
W1, b1, W2, b2 = model['W1'], model['b1'], model['W2'], model['b2']
# 用于计算预测值的前向传播
z1 = X.dot(W1) + b1
a1 = np.tanh(z1)
z2 = a1.dot(W2) + b2
exp_scores = np.exp(z2)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
# 计算损失
corect_logprobs = -np.log(probs[range(num_examples), y])
data_loss = np.sum(corect_logprobs)
#添加正则化的损失,可选可不选,为了陷入过拟合
data_loss += reg_lambda/2 * (np.sum(np.square(W1)) + np.sum(np.square(W2)))
return 1./num_examples * data_loss
#我们还要实现一个用于计算输出的辅助函数。它会通过定义好的前向传播方法来返回拥有最大概率的类别
def predict(model, x):
W1, b1, W2, b2 = model['W1'], model['b1'], model['W2'], model['b2']
# 正向传播
z1 = x.dot(W1) + b1
a1 = np.tanh(z1)
z2 = a1.dot(W2) + b2
exp_scores = np.exp(z2)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
return np.argmax(probs, axis=1)
#构建模型
def build_model(nn_hdim, num_passes=20000, print_loss=False):
#将参数初始化为随机值。我们需要学习这些。
np.random.seed(0)
W1 = np.random.randn(nn_input_dim, nn_hdim) / np.sqrt(nn_input_dim)
b1 = np.zeros((1, nn_hdim))
W2 = np.random.randn(nn_hdim, nn_output_dim) / np.sqrt(nn_hdim)
b2 = np.zeros((1, nn_output_dim))
# 这是用于最终反馈结果的变量
model = {}
# 批量梯度下降.
for i in xrange(0, num_passes):
# 前向传播
z1 = X.dot(W1) + b1
a1 = np.tanh(z1)
z2 = a1.dot(W2) + b2
exp_scores = np.exp(z2)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
# 反向传播
delta3 = probs
delta3[range(num_examples), y] -= 1
dW2 = (a1.T).dot(delta3)
db2 = np.sum(delta3, axis=0, keepdims=True)
delta2 = delta3.dot(W2.T) * (1 - np.power(a1, 2))
dW1 = np.dot(X.T, delta2)
db1 = np.sum(delta2, axis=0)
# A添加规范项 (b1 和b2 没有规范项)
dW2 += reg_lambda * W2
dW1 += reg_lambda * W1
# 梯度下降参数更新
W1 += -epsilon * dW1
b1 += -epsilon * db1
W2 += -epsilon * dW2
b2 += -epsilon * db2
# 将参数赋到model中
model = { 'W1': W1, 'b1': b1, 'W2': W2, 'b2': b2}
# 选择性打印损失
# 这项操作代价较大,因为它要用到整个数据集,所以我们会降低使用频率。
if print_loss and i % 1000 == 0:
print "Loss after iteration %i: %f" %(i, calculate_loss(model))
return model
# 创建一个含有三层隐含层的模型
model = build_model(3, print_loss=True)
# 绘制决策边界
plot_decision_boundary(lambda x: predict(model, x))
plt.title("Decision Boundary for hidden layer size 3")
plt.show()
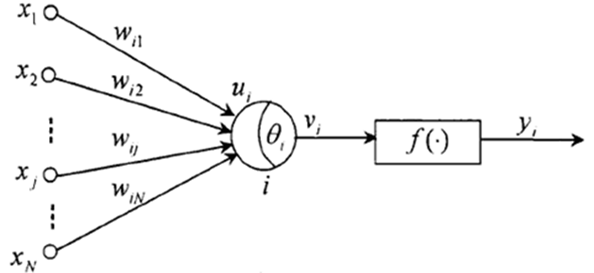
其中xj(j=1,2……n)为神经元i的输入信号,wij为连接权,ui是由输入信号线性组合后的输出,是神经元i的净输入。θi为神经元的阀值,vi为经偏差调整过的值,称为神经元的局部感应区。f(.)是激励函数,yi是神经元i的输出
我个人认为,BP神经网络的算法核心是让全局网络误差达到最小,当误差为0的时候也就是模型最准确的时候,当然误差很可能不是0,为了逼近最小误差,我们要不断的去调节参数w,这个w的调节过程,就是不断迭代权值修去过过程。而这个权值修正,要用到梯度下降的方法,也是BP神经网络的一个核心思想,虽然梯度下降法可以有效的快速收敛,但当函数越来越复杂以后,会特别容易收敛到非最小值点,这就需要有一个更加好的初值和更加合适的学习率。所以说梯度下降的方法并不是完美的,它很有可能会导致寻求的误差最小值是局部最小值而非全局最小值,不过现在已经有了不少的改进方法,如随机梯度下降,批量梯度下降等等。最终在训练完模型后,这个模型就具有类似的预测能力。

这里的w都是权值,x是输入数据,b是阈值,f(x)代表的就是激活函数。如代码部分的demo中,也是按照这个算法来构建误差函数的。

给定n个样本,误差就是训练中给出的分类和学习后分类函数输出的分类的差值,然后平方再加和。这个过程与求方差差不多,反正最后的原则很清楚,方差尽可能小,最好是0。开始的时候会在隐含层和输出层设置两套w,这个w的设定是随机的,因为第一次设置的w极有可能不会是整个网络误差最小,所以超过误差范围就要调整。而图中的函数本身是没有1/2的,这里特意配一个1/2是因为:1,不会影响函数的单调性,2,在求导的时候能够去掉,式子会看上去比较整洁。
图中的d是期望输出,y是实际输出。
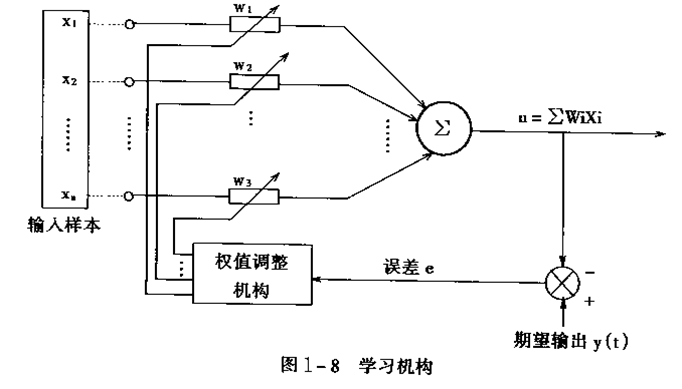
整个机制就是如上图这样的。

反向传播。然后对这个误差函数进行求导求偏微分。上图是输出层的误差偏微分。

上图是隐含层偏微分,方法和输出层的推导完全一样。
最后就是权值的修正过程:

总结:我们会先设置两套w作为两层网络各自的“超平面”的系数,然后输入一次完整的训练过程,就会有一个误差值出现,因为在给出的w很可能不合适。接着就是一次一次的进行w的调整。调整的方法是,首先找到一个误差和自变量的关系,然后求误差极值。误差存在的点就是误差最小的点,这和回归分析的最小二乘法的思想几乎一样。只是在最后的w迭代的两个公式中,用的就是试探的方法。思想就是往误差小的一边走一小步,如果还不够小就在走一步,这就是一次一次的迭代过程。直到最后找到一个误差满足要求的点,把这一点的w都记录下来,或者达到设定的训练次数,网络就训练完毕了。上图的η(学习率)就是这个每次走的“一小步”。
github中代码demo:https://github.com/NSAryan12/nn-from-scratch/blob/master/nn-from-scratch.ipynb
参考书籍:白话大数据与机器学习---高扬,卫峥,尹会生著。















 4451
4451

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









