







堆排序基本思想
1. 将待排序的各元素(假设为n个)构建成一个完全二叉树,如果是从小到大排序则构造一个大顶堆,如果是从大到小排序,则构建一个小顶堆。
2. 以大顶堆为例,层级遍历大顶堆,将各元素存储区数组,其中根节点也就是数组的第一个元素为最大值,将其与数组的最后一个元素进行交换,则最大值被放在数组的最后,再将剩下的n-1个元素按照步骤1的方法重新构造大顶堆,取出根节点则为第二大数组,将其添加到数组的倒数第二个位置。
3. 依次类推,可以将数组中的其他元素排序。
基本概念
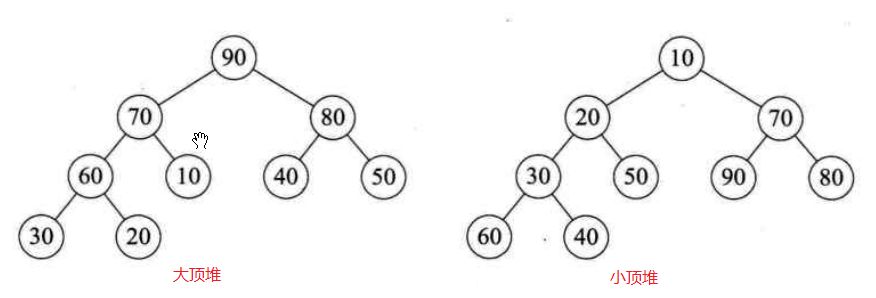
堆:
1. 完全二叉树
2. 根节点的值是所有元素的最大值–大顶堆,反之则为小顶堆。
3. 每个节点的值都大于或等于其左右孩子节点的值–大顶堆,反之则为小顶堆。
按照层序遍历的方式给结点从1开始编号,则满足以下关系:
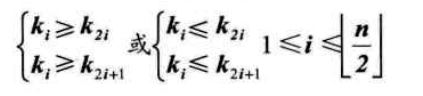
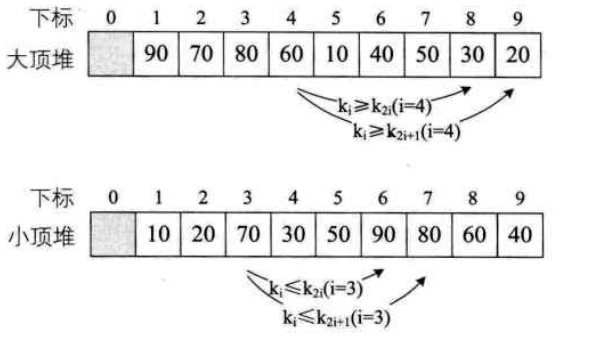
如下:
好了,原理讲到这里,下面是代码实现:
#include <iostream>
void swap(int k[],int i,int j)
{
int tmp ;
tmp = k[i];
k[i] = k[j];
k[j] = tmp;
}
//s表示根节点的序号,从1开始
void HeadAdjust(int k[],int s,int n)
{
int i,tmp;
tmp = k[s];//双亲节点
//s指向双亲节点
for (i = 2 * s; i <= n ; i*=2)
{
if( i < n && k[i] < k[i+1] )
{
i++;//i指向最大孩子的下标
}
//至此,i表示最大孩子节点,可能是左孩子也可能是右孩子
if(tmp >= k[i])
{
break;
}
//执行到这里,说明双亲节点没有孩子节点大,则需要调整
k[s] = k[i];
s = i;
}
k[s] = tmp;//将双亲节点的值赋值给孩子节点,此时,s指向孩子节点。因为前面 s = i
}
void HeadSort(int k[],int n)
{
int i ;
//构建大顶堆,从下层开始,n表示元素个数
for (i = n/2 ; i>0 ; i--)
{
//堆调整,i表示大顶堆最下层根节点的序号
HeadAdjust(k,i,n);
}
//交换大顶堆层序遍历数组的第一个元素(最大值)和最后一个元素
for (i=n;i>1;i--)
{
swap(k,1,i);
//这里第二个参数总是传递1,因为前面的大顶堆已经构建好了,这里只是将根节点(序号为1)与最后一个叶子节点交换,且最后一个叶子节点不在参与计算,所以,接下来只需要调整根节点的位置即可。所以第二个参数传递1,表示当前的双亲节点是根节点。
HeadAdjust(k,1,i-1);
}
}
void main()
{
int i ;
int a[10] = {-1,5,2,6,0,3,9,1,7,4};
HeadSort(a,9);
printf("排序后的结果是:");
for(int i = 1; i < 10; i++)
{
printf("%d ",a[i]);
}
system("pause");
}堆排序的时间复杂度:
O(nlogn)
优点:
1. 对原始记录的排序状态并不敏感,因此它无论是最好、最坏和平均时间复杂度都是O(nlogn),在性能上要远远好于冒泡、简单选择、直接插入的O(n^2)的时间复杂度。
缺点:
1. 记录的比较与交换是跳跃式进行,导致堆排序是一种不稳定的排序方法。
2. 初始构建堆所需的比较次数较多,因此,它并不适合待排序序列个数较少的情况。















 23万+
23万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









