







 本文介绍了逻辑回归的梯度下降法,重点讨论了max_iter参数的重要性,它限制了梯度下降的最大迭代次数。通过案例展示了数据预处理、异常值处理、样本不平衡问题的应对策略,并以乳腺癌和鸢尾花数据集为例探讨了不同参数设置的影响。最后,文章通过逻辑回归制作评分卡的案例,阐述了评分卡的制作流程和关键步骤,包括数据处理、特征分箱和模型验证。
本文介绍了逻辑回归的梯度下降法,重点讨论了max_iter参数的重要性,它限制了梯度下降的最大迭代次数。通过案例展示了数据预处理、异常值处理、样本不平衡问题的应对策略,并以乳腺癌和鸢尾花数据集为例探讨了不同参数设置的影响。最后,文章通过逻辑回归制作评分卡的案例,阐述了评分卡的制作流程和关键步骤,包括数据处理、特征分箱和模型验证。
2.3 梯度下降:重要参数max_iter
逻辑回归的数学目的是求解能够让模型最优化,拟合程度最好的参数θ的值,即求解能够让损失函数J(θ)最小化的θ值。对于二元逻辑回归来说,有多种方法可以用来求解参数θ ,最常见的有梯度下降法(Gradient Descent),坐标下降法(Coordinate Descent),牛顿法(Newton-Raphson method)等,其中又以梯度下降法最为著名。每种方法都涉及复杂的数学原理,但这些计算在执行的任务其实是类似的。
2.3.1 梯度下降求解逻辑回归

那我们怎么做呢?我在这个图像上随机放一个小球,当我松手,这个小球就会顺着这个华丽的平面滚落,直到滚到 深蓝色的区域——损失函数的最低点。为了严格监控这个小球的行为,我让小球每次滚动的距离有限,不让他一次性滚到最低点,并且最多只允许它滚动100步,还要记下它每次滚动的方向,直到它滚到图像上的最低点。
可以看见,小球从高处滑落,在深蓝色的区域中来回震荡,最终停留在了图像凹陷处的某个点上。非常明显,我们 可以观察到几个现象:
首先,小球并不是一开始就直向着最低点去的,它先一口气冲到了蓝色区域边缘,后来又折回来,我们已经规定了 小球是多次滚动,所以可见,小球每次滚动的方向都是不同的。
另外,小球在进入深蓝色区域后,并没有直接找到某个点,而是在深蓝色区域中来回震荡了数次才停下。这有两种 可能:1) 小球已经滚到了图像的最低点,所以停下了,2) 由于我设定的步数限制,小球还没有找到最低点,但也只好在100步的时候停下了。也就是说,小球不一定滚到了图像的最低处。
但无论如何,小球停下的就是我们在现有状况下可以获得的唯一点了。如果我们够幸运,这个点就是图像的最低 点,那我们只要找到这个点的对应坐标(θ*1,θ*2,Jmin ),就可以获取能够让损失函数最小的参数取值
[θ*1,θ*2]了。如此,梯度下降的过程就已经完成。
在这个过程中,小球其实就是一组组的坐标点 (θ1,θ2,J);小球每次滚动的方向就是那一个坐标点的梯度向量的方向,因为每滚动一步,小球所在的位置都发生变化,坐标点和坐标点对应的梯度向量都发生了变化,所以每次滚动的方向也都不一样;人为设置的100次滚动限制,就是sklearn中逻辑回归的参数max_iter,代表着能走的最大步数,即最大迭代次数。
所以梯度下降,其实就是在众多(θ1,θ2)可能的值中遍历,一次次求解坐标点的梯度向量,不断让损失函数J的取值逐渐逼近最小值,再返回这个最小值对应的参数取值[θ*1,θ*2]的过程。
2.3.2 梯度下降的概念与解惑


那梯度有什么含义呢?梯度是一个向量,因此它有大小也有方向。它的大小,就是偏导数组成的向量的大小,又叫 做向量的模,
记作d 。它的方向,几何上来说,就是损失函数J(θ) 的值增加最快的方向,就是小球每次滚动的方向的反方向。只要沿着梯度向量的反动坐标,损失函数的取值就会减少得最快,也就最容易找到损失函数的最小值。
在逻辑回归中,我们的损失函数如下所示:



2.3.3 步长的概念与解惑


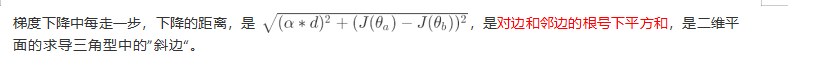
所以,步长不是任何物理距离,它甚至不是梯度下降过程中任何距离的直接变化,它是梯度向量的大小 d 上的一个比例,影响着参数向量 θ 每次迭代后改变的部分。
不难发现,
既然参数迭代是靠梯度向量的大小d * α步长 来实现的,J(θ)而的降低又是靠调节θ 来实现的,所以步长可以调节损失函数下降的速率。在损失函数降低的方向上,步长越长, θ 的变动就越大。相对的,步长如果很短, θ的每次变动就很小。具体地说,如果步长(α)太大,损失函数J(θ)下降得就非常快,需要的迭代次数就很少,但梯度下降过程可能跳过损失函数的最低点,无法获取最优值。而步长太小,虽然函数会逐渐逼近我们需要的最低点,但迭代的 速度却很缓慢,迭代次数就需要很多。

记得我们在看小球运动时注意到,小球在进入深蓝色区域后,并没有直接找到某个点,而是在深蓝色区域中来回震 荡了数次才停下,这种”震荡“其实就是因为我们设置的步长太大的缘故。但是在我们开始梯度下降之前,我们并不 知道什么样的步长才合适,但梯度下降一定要在某个时候停止才可以,否则模型可能会无限地迭代下去。因此,在sklearn当中,我们设置参数max_iter最大迭代次数来代替步长,帮助我们控制模型的迭代速度并适时地让模型停下。max_iter越大,代表步长越小,模型迭代时间越长,反之,则代表步长设置很大,模型迭代时间很短。
迭代结束,获取到J(θ) 的最小值后,我们就可以找出这个最小值对应的参数向量 θ ,逻辑回归的预测函数也就可以根据这个参
数向量θ 来建立了。
来看看乳腺癌数据集下,max_iter的学习曲线:
| #导库 from sklearn.linear_model import LogisticRegression as LR #导入线性模型中的逻辑回归 from sklearn.datasets import load_breast_cancer #导入乳腺癌数据集 import numpy as np import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split #分测试集和训练集的类 from sklearn.metrics import accuracy_score #矩阵模块导入精确性分数 data = load_breast_cancer() #数据实例化 X = data.data #特征矩阵 y = data.target #标签矩阵 X.shape #569行,30个特征 l2 = [] l2test = [] #划分训练集测试集 Xtrain, Xtest, Ytrain, Ytest = train_test_split(X,y,test_size=0.3,random_state=420) for i in np.arange(1,201,10): #max_iter最大迭代次数,l2正则化 lrl2 = LR(penalty="l2",solver="liblinear",C=0.8,max_iter=i) #实例化 lrl2 = lrl2.fit(Xtrain,Ytrain) l2.append(accuracy_score(lrl2.predict(Xtrain),Ytrain)) #训练集表现结果 l2test.append(accuracy_score(lrl2.predict(Xtest),Ytest)) #测试集表现结果 graph = [l2,l2test] color = ["black","gray"] label = ["L2","L2test"] plt.figure(figsize=(20,5)) for i in range(len(graph)): plt.plot(np.arange(1,201,10),graph[i],color[i],label=label[i]) plt.legend(loc=4) plt.xticks(np.arange(1,201,10)) plt.show() #我们可以使用属性.n_iter_来调用本次求解中真正实现的迭代次数 #最多可以迭代300次,看究竟迭代几次就找到最佳值 lr = LR(penalty="l2",solver="liblinear",C=0.9,max_iter=300).fit(Xtrain,Ytrain) lr.n_iter_ -->array([25], dtype=int32) |
模型最大迭代次数21左右

当max_iter中限制的步数已经走完了,逻辑回归却还没有找到损失函数的最小值,θ参数 的值还没有被收敛,
sklearn就会弹出这样的红色警告:
当参数solver="liblinear":

当参数solver="sag":

虽然写法看起来略有不同,但其实都是一个含义,这是在提醒我们:参数没有收敛,请增大max_iter中输入的数字。但我们不一定要听sklearn的。max_iter很大,意味着步长小,模型运行得会更加缓慢。虽然我们在梯度下降中追求的是损失函数的最小值,但这也可能意味着我们的模型会过拟合(在训练集上表现得太好,在测试集上却不 一定),因此,如果在max_iter报红条的情况下,模型的训练和预测效果都已经不错了,那我们就不需要再增大max_iter中的数目了,毕竟一切都以模型的预测效果为基准——只要最终的预测效果好,运行又快,那就一切都好,无所谓是否报红色警告了。
2.4 二元回归与多元回归:重要参数solver & multi_class
之前我们对逻辑回归的讨论,都是针对二分类的逻辑回归展开,其实sklearn提供了多种可以使用逻辑回归处理多 分类问题的选项。比如说,我们可以把某种分类类型都看作1,其余的分类类型都为0值,和”数据预处理“中的二值 化的思维类似,这种方法被称为"一对多"(One-vs-rest),简称OvR,在sklearn中表示为“ovr"。又或者,我们可以把好几个分类类型划为1,剩下的几个分类类型划为0值,这是一种”多对多“(Many-vs-Many)的方法,简称MvM,在sklearn中表示为"Multinominal"。每种方式都配合L1或L2正则项来使用。
在sklearn中,我们使用参数multi_class来告诉模型,我们的预测标签是什么样的类型。
multi_class
输入"ovr", "multinomial", "auto"来告知模型,我们要处理的分类问题的类型。默认是"ovr"。
'ovr':表示分类问题是二分类,或让模型使用"一对多"的形式来处理多分类问题。
'multinomial':表示处理多分类问题,这种输入在参数solver是'liblinear'(专门处理二分类的)时不可用。
"auto":表示会根据数据的分类情况和其他参数来确定模型要处理的分类问题的类型。比如说,如果数据是二分类,或者solver的取值为"liblinear","auto"会默认选择"ovr"。反之,则会选择"nultinomial"。
注意:默认值将在0.22版本中从"ovr"更改为"auto"。
我们之前提到的梯度下降法,只是求解逻辑回归参数θ 的一种方法,并且我们只讲解了求解二分类变量的参数时的各种原理。sklearn为我们提供了多种选择,让我们可以使用不同的求解器来计算逻辑回归。求解器的选择,由参数"solver"控制,共有五种选择。其中“liblinear”是二分类专用(不支持多分类),也是现在的默认求解器。

来看看鸢尾花数据集上,multinomial和ovr的区别怎么样:
| from sklearn.linear_model import LogisticRegression as LR #导入线性模型中的逻辑回归 from sklearn.datasets import load_iris #鸢尾花数据集 import numpy as np from sklearn.metrics import accuracy_score iris = load_iris() for multi_class in ('multinomial', 'ovr'): #两种参数'multinomial', 'ovr' lr = LR(solver='sag', max_iter=100, random_state=42, multi_class=multi_class).fit(iris.data, iris.target) #打印两种multi_class模式下的训练分数 print("training score : %.3f (%s)" % (lr.score(iris.data, iris.target), multi_class)) #%的用法,用%来代替打印的字符串中,想由变量替换的部分。%.3f表示,保留三位小数的浮点数。%s表示,字符串。 #字符串后的%后使用元祖来容纳变量,字符串中有几个%,元祖中就需要有几个变量 |
2.5 样本不平衡与参数class_weight
样本不平衡是指在一组数据集中,标签的一类天生占有很大的比例,或误分类的代价很高,即我们想要捕捉出某种 特定的分类的时候的状况。
什么情况下误分类的代价很高?例如,我们现在要对潜在犯罪者和普通人进行分类,如果没有能够识别出潜在犯罪 者,那么这些人就可能去危害社会,造成犯罪,识别失败的代价会非常高,但如果,我们将普通人错误地识别成了 潜在犯罪者,代价却相对较小。所以我们宁愿将普通人分类为潜在犯罪者后再人工甄别,但是却不愿将潜在犯罪者 分类为普通人,有种"宁愿错杀不能放过"的感觉。
再比如说,在银行要判断“一个新客户是否会违约”,通常不违约的人vs违约的人会是99:1的比例,真正违约的人 其实是非常少的。这种分类状况下,即便模型什么也不做,全把所有人都当成不会违约的人,正确率也能有99%, 这使得模型评估指标变得毫无意义,根本无法达到我们的“要识别出会违约的人”的建模目的。
因此我们要使用参数class_weight对样本标签进行一定的均衡,给少量的标签更多的权重,让模型更偏向少数类,向捕获少数类的方向建模。该参数默认None,此模式表示自动给与数据集中的所有标签相同的权重,即自动1:1。当误分类的代价很高的时候,我们使用”balanced“模式,我们只是希望对标签进行均衡的时候,什么都不填就可以解决样本不均衡问题。
但是,sklearn当中的参数class_weight变幻莫测,大家用模型跑一跑就会发现,我们很难去找出这个参数引导的模型趋势,或者画出学习曲线来评估参数的效果,因此可以说是非常难用。我们有着处理样本不均衡的各种方法,其 中主流的是采样法,是通过重复样本的方式来平衡标签,可以进行上采样(增加少数类的样本),比如SMOTE, 或者下采样(减少多数类的样本)。对于逻辑回归来说,上采样是最好的办法。在案例中,会给大家详细来讲如何 在逻辑回归中使用上采样。
3 案例:用逻辑回归制作评分卡
在银行借贷场景中,评分卡是一种以分数形式来衡量一个客户的信用风险大小的手段,它衡量向别人借钱的人(受 信人,需要融资的公司)不能如期履行合同中的还本付息责任,并让借钱给别人的人(授信人,银行等金融机构) 造成经济损失的可能性。一般来说,评分卡打出的分数越高,客户的信用越好,风险越小。
这些”借钱的人“,可能是个人,有可能是有需求的公司和企业。对于企业来说,我们按照融资主体的融资用途,分 别使用企业融资模型,现金流融资模型,项目融资模型等模型。而对于个人来说,我们有”四张卡“来评判个人的信 用程度:A卡,B卡,C卡和F卡。而众人常说的“评分卡”其实是指A卡,又称为申请者评级模型,主要应用于相关融 资类业务中新用户的主体评级,即判断金融机构是否应该借钱给一个新用户,如果这个人的风险太高,我们可以拒 绝贷款。
一个完整的模型开发,需要有以下流程:

今天我们以个人消费类贷款数据,来为大家简单介绍A卡的建模和制作流程,由于时间有限,我们的核心会在”数据 清洗“和“模型开发<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 113
113











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









