






Transformer 的发展历史
2017年6月,谷歌研究人员为了解决机器翻译任务首次提出了 Transoformer 架构。论文地址如下:
https://arxiv.org/abs/1706.03762
随后在此基础上又衍生了几个著名的模型:
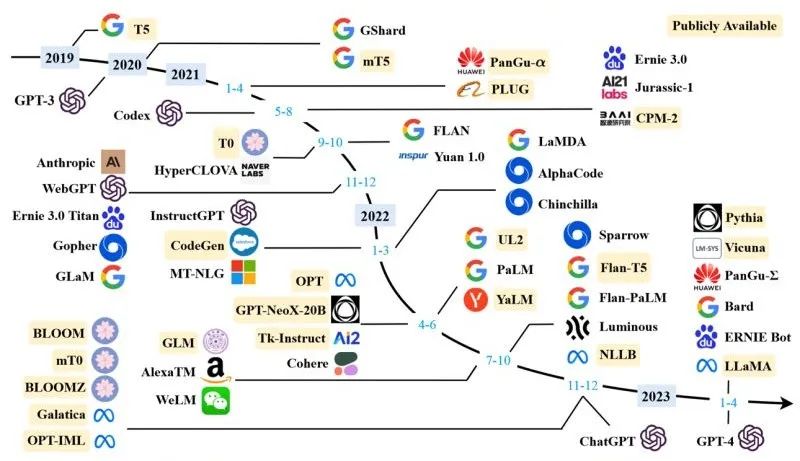
上面的图看起来眼花缭乱,但是大体上这些模型可以分为三种:
- GPT 系列:自回归(auto-regressive)Transformer 模型。
- BERT 系列:自编码(auto-encoding)Transformer 模型。
- BART/T5 系列:序列到序列(sequence-to-sequence)Transformer 模型。
什么是迁移学习
迁移学习(Transfer Learning)是指用模型 A 的参数初始化模型 B 的行为。
简单来说就是我们用大量的数据训练了可以处理任务 Ta 的模型 A。现在又要训练一个模型 B 来处理任务 Tb,我们可以从头开始训练模型 B,也可以将模型 A 学到的知识迁移(transfer)给模型 B,然后用少量的数据集微调(fine-tune)一下模型 B 的参数,使得模型 B 可以更好地处理任务 Tb。
如果我们从头开始训练模型 B,那将是十分耗时且需要大量的数据和计算资源。
迁移学习并不是一件新事物,在计算机视觉领域,迁移学习已经被应用了将近十年了。在计算机视觉领域,模型 A 通常在 ImageNet 数据集上预训练(pretraining)过,这使得模型 A 具有了识别物体边界、轮廓等信息的能力。
Transformer 是语言模型
所有的 Transformer 模型都是作为语言模型(language model)以自监督(self-supervised)的形式在大量的纯文本数据集上被预训练的。自监督学习是一种根据模型的输入自动计算目标的训练,不需要人类来标记数据!
一般有两种预训练目标,一种是根据现有的前 n 个词预测句子中下一个词。

这种由于模型的输出取决于当前和之前的输入,所以也叫做因果语言建模(causal language modeling)。比如 GPT(Generative Pre-Training)模型。
另一种是称为 masked language modeling,有点像大家做过的英语完形填空。

随机从句子中掩盖(mask)几个词,用 [MASK] 符号标记,然后让模型预测被掩盖的词。比如 BERT(Bidirectional Encoder Representations from Transformers)模型。
预训练与微调
预训练(Pretraining)指的是从头开始训练模型:所有的参数都随机初始化,训练开始时模型没有任何的先验知识。
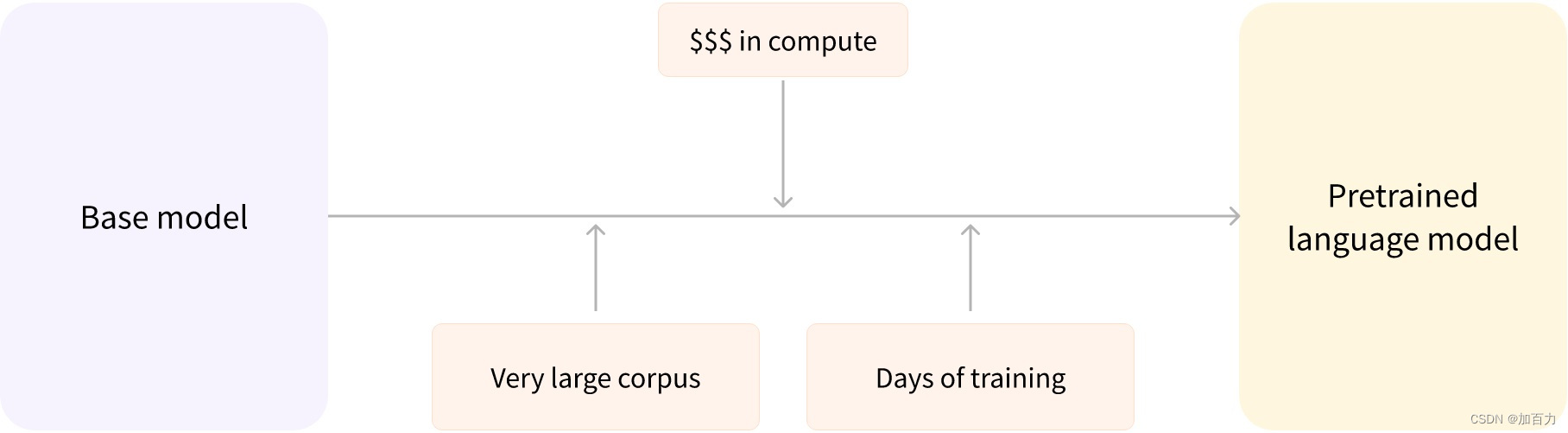
如上图所描述的,我们通常用超大语料库(very large corpus)组成的数据集去训练基座模型(base model)。这期间要花费大量资金去配置计算资源和数周的时间拟合数据。最终得到了一个预训练的语言模型。
据小道消息说 OpenAI 在 GPT-4 的训练中使用了 25,000 个 A100 GPU,训练了 90 到 100 天。
微调(Fine-tuning)就是根据当前手头上的任务对在其他任务上预训练过的语言模型(比如 Llama 2)用当前任务相关的数据集进行针对性的训练。
微调并不是简单的“拿来主义”,有几点需要注意:
- 需要选择一个在与当前任务微调数据集相似的数据集上经过预训练的语言模型。这样微调过程才能够利用预训练模型在预训练期间获得的知识
- 由于预训练模型已经接受了大量数据的训练,因此我们只需要更少的数据就能通过微调来获得不错的结果。
- 出于同样的原因,获得良好结果所需的时间和资源要少得多。
例如,要处理中文的 NLP 问题,那么在大量中文数据集上预训练过的模型获得的对中文的统计数据质量肯定比在大量日文数据集上预训练过的模型要好。这个中文预训练模型将关于中文的知识迁移到了当前的微调模型上了,这也是迁移学习的名称来源。
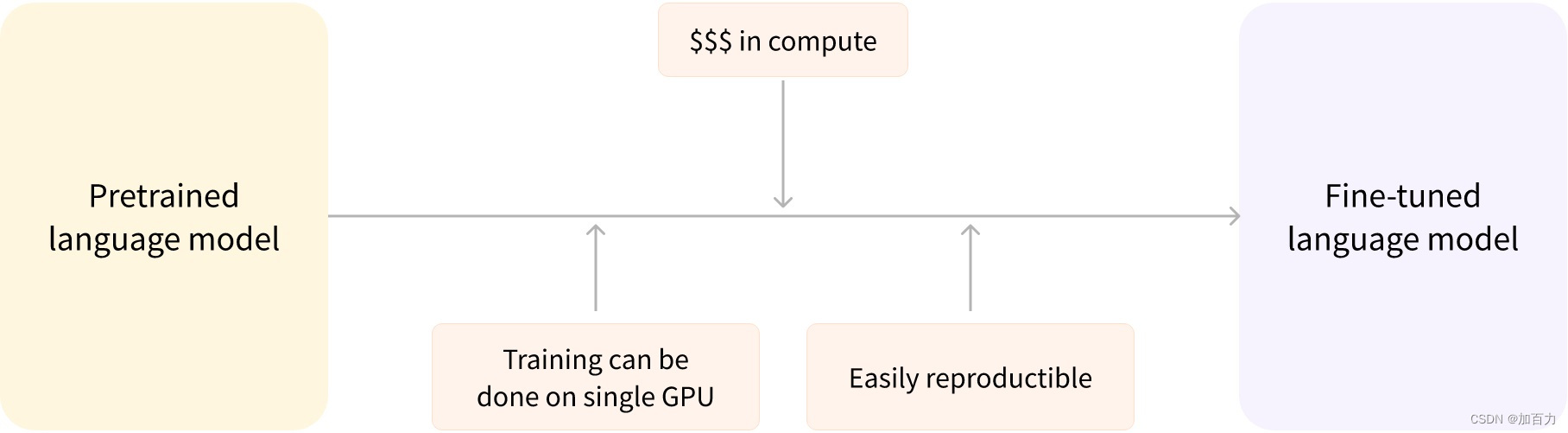
因此,微调模型的时间、数据、财务和环境成本较低。由于训练比完整的预训练限制更少,所以迭代不同的微调方案也更快、更容易。
这个过程还将比从头开始训练获得更好的结果(除非你有大量数据),这就是为什么我们应该始终尝试利用预训练模型(尽可能接近我们手头的任务)并进行微调它。
Transformer 的架构
下图是最开始的《Attention is all you need》论文中展示的 Transformer 架构。在这里我们先了解一个大概,我们可以看到这个架构主要有两部分:Encoder(编码器) 和 Decoder(解码器)。
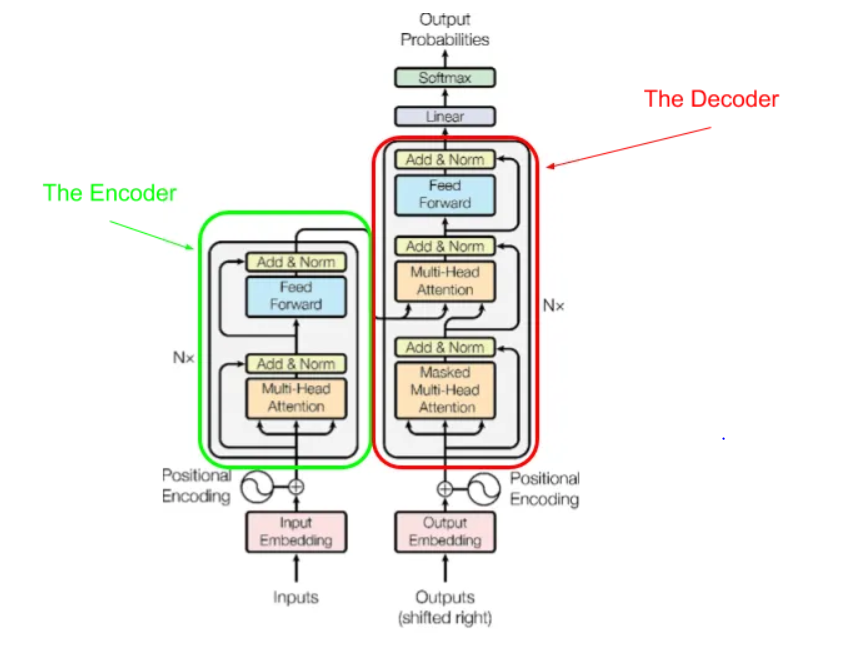
Encoder 接受文本输入,将文本转成数字表示,这些数字表示也称为 Embedding(嵌入)或 Feature(特征)。Encoder 善于理解输入文本。
Decoder 接受 Encoder 生成的表示,并结合其他输入生成目标序列(可以理解成生成句子)。Decoder 善于生成文本。
后来衍生出了以下模型:
- 仅 Encoder 架构模型或 auto-encoding 模型:擅长从句子中提取信息,适合例如文本分类、命名实体识别等需要很好理解输入文本的任务。
- 仅 Decoder 架构模型或 auto-regressive 模型:适合需要生成文本的任务。
- Encoder-Decoder 模型或者称为 Sequence-to-Sequence 模型:这个适合机器翻译或者是文本总结/摘要等输入是文本,输出也是文本的任务。
仅 Encoder 架构模型
BERT 模型就是一个著名的仅 Encoder 架构模型。
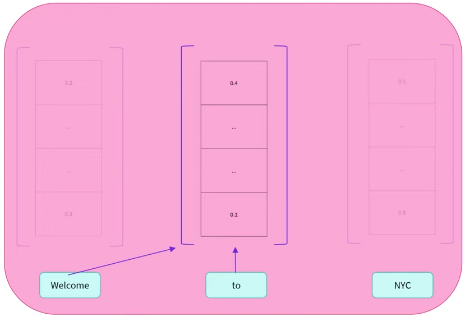
Encoder 将输入的文本序列:Welcome to NYC 转成了数值表示。
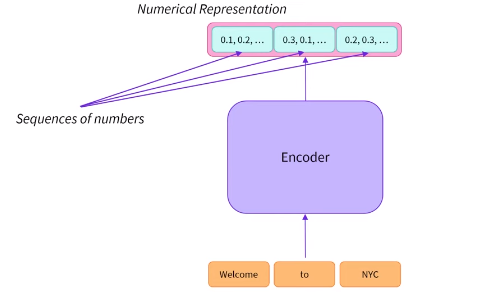
每个单词对应一个称为特征向量(feature vector)或者特征张量(feature tensor)的数值表示。向量的维度由具体的 Encoder 模型决定,对于 BERT 基座模型来说是 768。
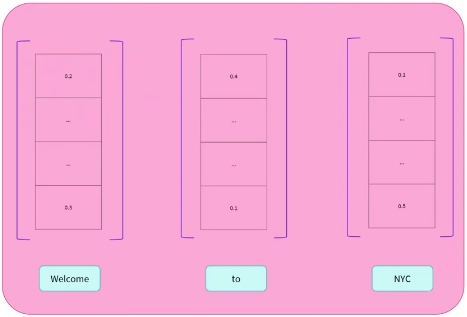
每个词并不是独立地转成对应的向量表示,比如对于 to 来说,BERT 模型考虑 to 周围出现的其他词(context,上下文),然后计算出 to 的数值表示。
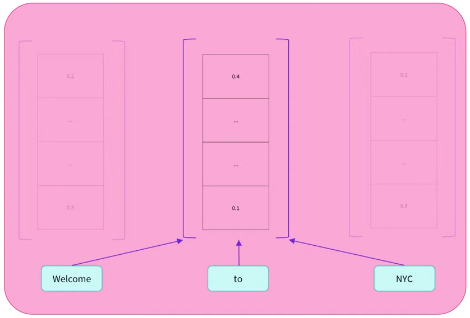
BERT 名字中的 Bidirectional(双向)正是来自于它从 to 的上文 Welcome,和下文 NYC 这两个方向考虑 to 出现的语境。
除了 BERT 之外,还有 ALBERT、DistilBERT、RoBERT 和 ELECTRA 这些著名的模型都是仅 Encoder 架构。
仅 Decoder 架构模型
大家熟知的 GPT 系列模型就是典型的仅
Decoder 架构模型。
Decoder 也会将文本输入转成对应的数值表示。
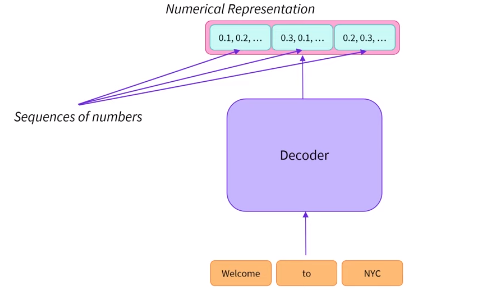
不过 Decoder 是单向的(Uni-directional),在生成 to 的数值表示时,它仅会考虑 to 左边的词。
除了 GPT 系列模型外,还有 CTRL 和 Transformer XL 也是仅 Encoder 架构。
Encoder-Decoder 模型
- 将文本 Welcome to NYC 输入 Encoder
- Encoder 输出文本的数值表示
- 将全部数值表示一次性输入 Decoder
- 将标识序列开始的表示输入 Decoder
- Decoder 开始根据序列开始标识和已经解码(decode)输出的词继续解码 Encoder 生成的数值表示中的剩余词
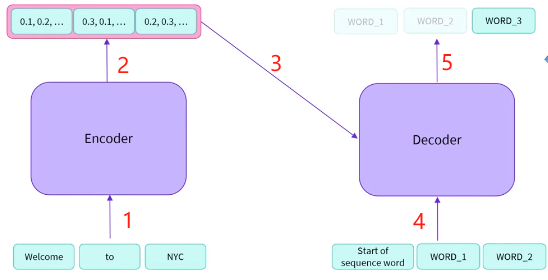
从第 4 步开始,首先 Decoder 根据序列开始标识开始从左向右逐个解码被编码(encode)成数值表示中的每个词,首先解码生成 WORD_1,然后 Decoder 根据已经解码的词继续解码剩余的词。
Encoder-Decoder 模型有 T5(Transfer Text-to-Text Transformer )、BART(Bidirectional and Auto-Regressive Transformers)、mBART 和 Marian 等。
注意力机制
从原始的论文标题《Attention is all you need》就能看出来 Transformer 是基于注意力机制(attention mechanism)的。
Transformer 模型中的关键之一就是注意力层(attention layer)。我们已经知道将一段文本输入模型时,Encoder 会将文本转成数值表示,这其实是将文本中的每个词(更专业的说法其实是 token)转成唯一的数值表示,注意力层告诉模型在处理这些数值表示时应该特别注意哪些词(这当然会或多或少忽略了其他不怎么重要的词)。
Transformer 架构最初是为了翻译任务而设计的,例如将英文翻译成中文。
Encoder 接受英文的句子输入,通过考虑每个词出现在句子中的上下文语境,输出了合适的数值表示。
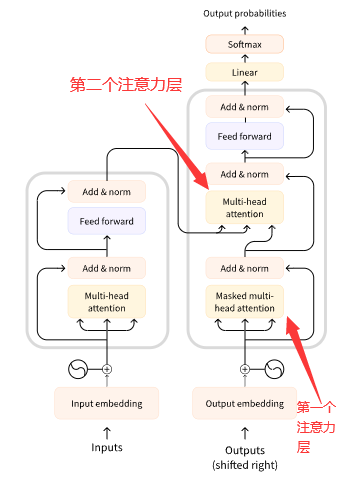
Decoder 的第一个注意力层关联它已经生成的中文输出,第二个注意力层关联 Encoder 输出的整个英文句子表示,这样 Decoder 会根据当期已经生成的中文输出再考虑整个原始英文句子去更好地预测下一个中文字/词。这一点非常有用,因为中文和英文的语法顺序不同,需要考虑到整个原始英文句子才能更好地将当前的词翻译出来。















 627
627

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









