







整体来看,transformer由Encoder和Decoder两部分组成,即编码和解码两部分,上图左边即是编码过程,右边即使解码过程,而图中N*表示有N个encoder和decoder。
先说明encoder部分
由input进行编码得到input embedding再与其位置编码positional encoding相加,得到n_input,该操作后,我们的input即有了每个input的意义又有了每个input相互的位置信息,即n_input即有了局部信息又包含全局信息。
input embedding的获取(假设一个词的编码由d个值来表示)
positional encoding的获取
一个词的位置编码也应由d个值来表示。
pos词第偶数个编码由sin获取,pos词第奇数个编码由cos获取。
P
E
(
p
o
s
,
2
i
)
=
s
i
n
(
p
o
s
1000
0
2
i
d
)
P
E
(
p
o
s
,
2
i
+
1
)
=
c
o
s
(
p
o
s
1000
0
2
i
d
)
PE_{(pos,2i)}=sin(\frac{pos}{10000^{\frac{2i}{d}}})\\ \quad PE_{(pos,2i+1)}=cos(\frac{pos}{10000^{\frac{2i}{d}}})
PE(pos,2i)=sin(10000d2ipos)PE(pos,2i+1)=cos(10000d2ipos)
d
d
d为编码的维度,
p
o
s
pos
pos为该词语的位置。
式中d表示编码的维度。
理由:
为了描述一个句子中两个词之间的位置关系,那么其positional encoding必须满足一下几个要求:1.对于每个位置的词语而言,其都能提供一个独一无二的编码。
2.对于不同长度的句子而言,词语之间的间隔表达的含义应该相同,即PE(pos1)+PE(pos2)在不同句子中的值应该相同。
3. 编码可以根据不同句子长度,任意伸长。
如何证明利用上述方式可以满足上面3个条件
假设输入的为一维字符串m1,通过上述步骤获取的n_input的维度为md。若输入的为一张图片chw,则n_input的维度为chwd。
下面以一维字符串m1为例说明。
Self-Attention

对n_input(m*d)分别进行
Q
=
n
_
i
n
p
u
t
⋅
w
Q
K
=
n
_
i
n
p
u
t
⋅
w
K
V
=
n
i
n
p
u
t
⋅
w
V
Q=n\_input \cdot w_Q\\ K=n\_input\cdot w_K\\ V=n_input\cdot w_V
Q=n_input⋅wQK=n_input⋅wKV=ninput⋅wV

问题:
w
Q
,
w
K
,
w
V
w_Q,w_K,w_V
wQ,wK,wV如何确定。
获取
Q
,
K
,
V
Q,K,V
Q,K,V向量后,通过
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
K
T
d
)
V
Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d}})V
Attention(Q,K,V)=softmax(dQKT)V
获得该句子各词的关注度。
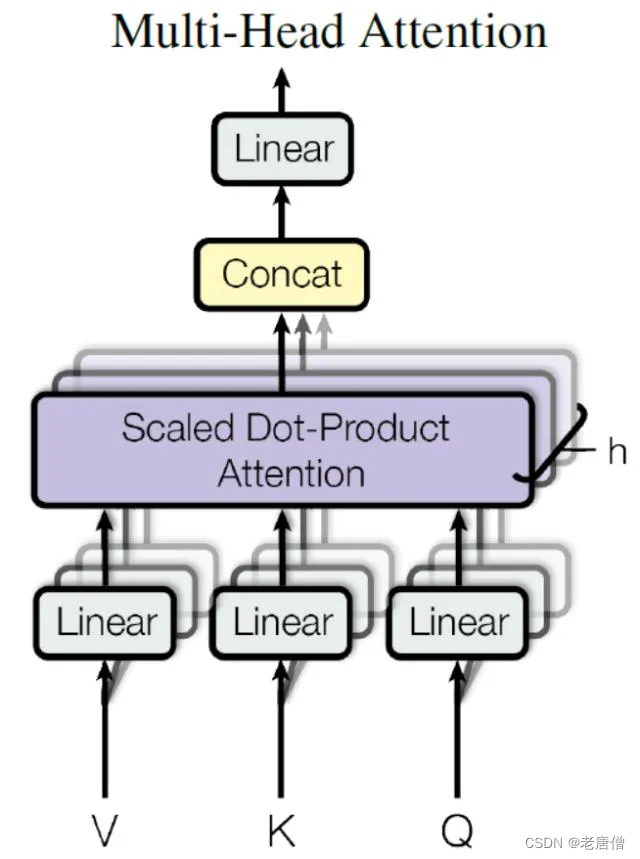
Multi-Head Attention
Multi-Head Attention中包含了多个self-attention。Multi-Head Attention将每个self-attention的结果拼接(Concat)起来,再经过一个linear将拼接的结果转换至m*d维度,结果为m_input。
Add and Norm
Add表示残差连接(Residual Connection)用于防止网络退化,Norm表示Layer Normalizaion,用于对每一层的激活值进行归一化。
Add为
A
d
d
_
i
n
p
u
t
=
m
i
n
p
u
t
+
i
n
p
u
t
Add\_input=m_input+input
Add_input=minput+input,可避免因为连乘效应而导致梯度为0的情况。
Norm为Layer Normalization,Layer Normalization可将每一层神经元的输入都转换为均值方差一致的,加快模型收敛速度,具体原理可以参考最速梯度下降法。
Feed Forward
该层为一个两层的全连接层,第一层的激活函数Relu,第二层无激活函数。
F
_
i
n
p
u
t
=
m
a
x
(
0
,
X
W
1
+
b
1
)
W
2
+
b
2
F\_input=max(0,XW_1+b_1)W_2+b_2
F_input=max(0,XW1+b1)W2+b2
经过Encoding操作后得到编码encoding(m*d).
Decoder
关注Decoder方面,其与Encoding相比多了一个Marked Multi-Head Attention的操作
Marked Multi-Head Attention
Marked Multi-Head Attention在Multi-Head Attention的基础上进行了一个Marked的操作。
感性的认识是,对于NLP问题,翻译“老唐僧”,在训练时(未marked),编码‘老’时使用了‘唐’、‘僧’的信息,而在解码时(使用marked),解码‘老’时,未使用‘唐’、‘僧’的信息。即在解码时,‘唐’、‘僧’的信息被marked了。
进行完Transforms后。















 248
248











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









