







 本文深入探讨了B树家族,包括B树、B+树和B*树,这些数据结构特别适用于磁盘I/O操作。由于磁盘访问时间主要由寻道时间、转动延迟和数据传送时间组成,因此减少磁盘访问次数至关重要。B树的特点是节点大小可与磁盘块匹配,每个节点包含多个键值和孩子。B+树则进一步优化,非叶子节点仅用于查找,所有数据在叶子节点,且通过链指针便于遍历。B*树则在B+树基础上增加了指向兄弟节点的指针,以保持节点至少2/3满,避免频繁分解。
本文深入探讨了B树家族,包括B树、B+树和B*树,这些数据结构特别适用于磁盘I/O操作。由于磁盘访问时间主要由寻道时间、转动延迟和数据传送时间组成,因此减少磁盘访问次数至关重要。B树的特点是节点大小可与磁盘块匹配,每个节点包含多个键值和孩子。B+树则进一步优化,非叶子节点仅用于查找,所有数据在叶子节点,且通过链指针便于遍历。B*树则在B+树基础上增加了指向兄弟节点的指针,以保持节点至少2/3满,避免频繁分解。
B树家族
磁盘I/O操作的基本单位为块。从磁盘上读取信息时,会把包含信息的整个块读入内存;将信息存储到磁盘上时,也需要将整个块写到磁盘上。当每次从磁盘上请求信息时,都必须先在磁盘上定位该信息。磁头移动到包含所请求信息的磁盘位置上方。然后,将磁盘旋转,将磁头下方的整个块传送到内存。也就是说,数据访问时间由几个时间段组成:
-
- 访问时间=寻道时间+转动延迟+数据传送时间
与在内存中传送信息相比,这个过程是相当缓慢的,其中寻道时间由于倚赖与磁头在定位到正确的磁道过程中的磁头的机械运动是非常消耗时间的。转动延迟指的是磁头转动到正确的磁盘块所需的时间。
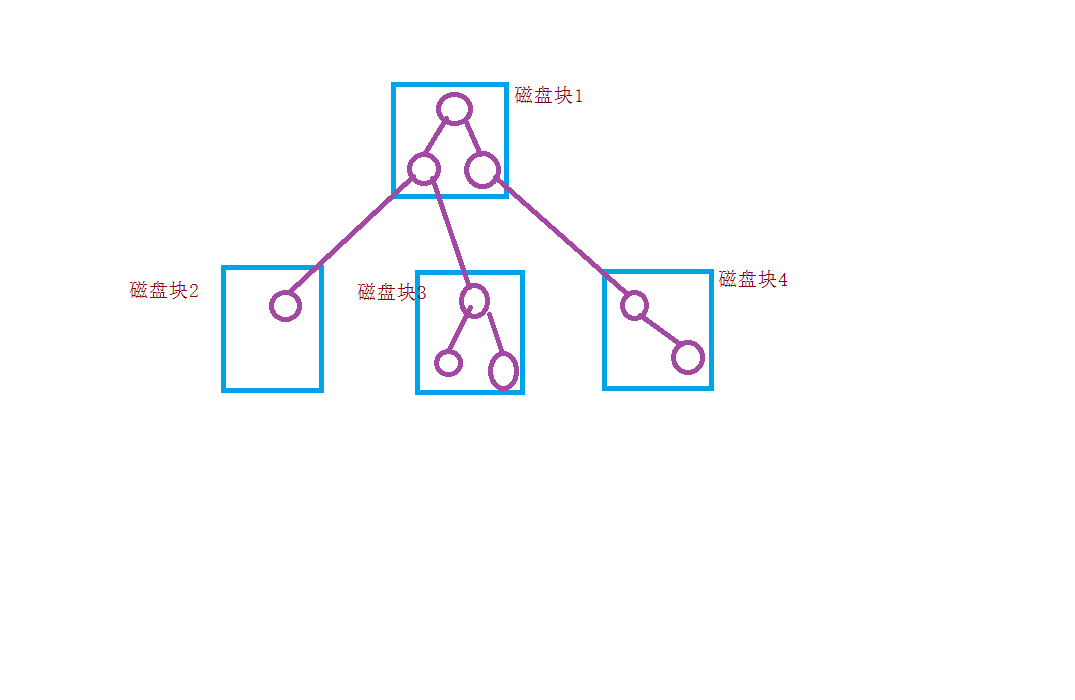
如果程序需要不断的使用辅助存储器上的信息,在设计该程序时就应该考虑这种存储方式的特性。如果用平衡树(AVL,RB)来作为这种存储方式的数据结构,那么平衡树可能分布在磁盘的不同块上,所以平均需要访问两个磁盘块。如果程序经常使用该树,这种访问时间就会显著增加。此外在该树中的插入和删除键值也需要访问多个个磁盘块。可以看出,平衡树在内存中是一种非常高效的工具,而在磁盘上就会变得非常的低效。在涉及辅助存储器时,二叉查找树在其他方面的性能优点会变得微不足道,因为这种方法需要不断的访问辅助存储器,严重降低了性能。
在磁盘上一次存取大量数据比在磁盘上的不同部分存取少量数据更好,比如给磁盘传送10KB数据时:
- 一个10KB片段上:
访问时间=40ms(寻道)+
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 235
235

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









