







非比较排序
前面我们介绍过的排序算法都属于比较排序,比较排序需要在排序的过程中对数据的大小进行比较,从而排除正确的顺序;那是不是必须要比较才能给数据进行正确的排序呢?当然不是,今天我们就来介绍一种非比较排序——基数排序。
非比较排序的算法思想##
不进行比较就能排出数据的算法都需要借助哈希直接地址法的思想,开始时把哈希表中的数据初始化为0,先遍历所要排序的数组,遍历到的数组的元素直接作为哈希表的直接地址,对该直接地址中存放的数进行加1操作,当我们遍历完整个数组时,数据也就排除序完毕了。它是按照哈希表的地址升序增长的序列。
这种排序算法的时间复杂度为O(N)(N待排序数组元素的个数),虽然时间复杂度很快,但当数据元素的间隔非常大时,这种算法是很消耗内存空间的。
于是,基数排序算法对其进行了改进,大大降低了其空间的消耗。
基数排序的执行过程
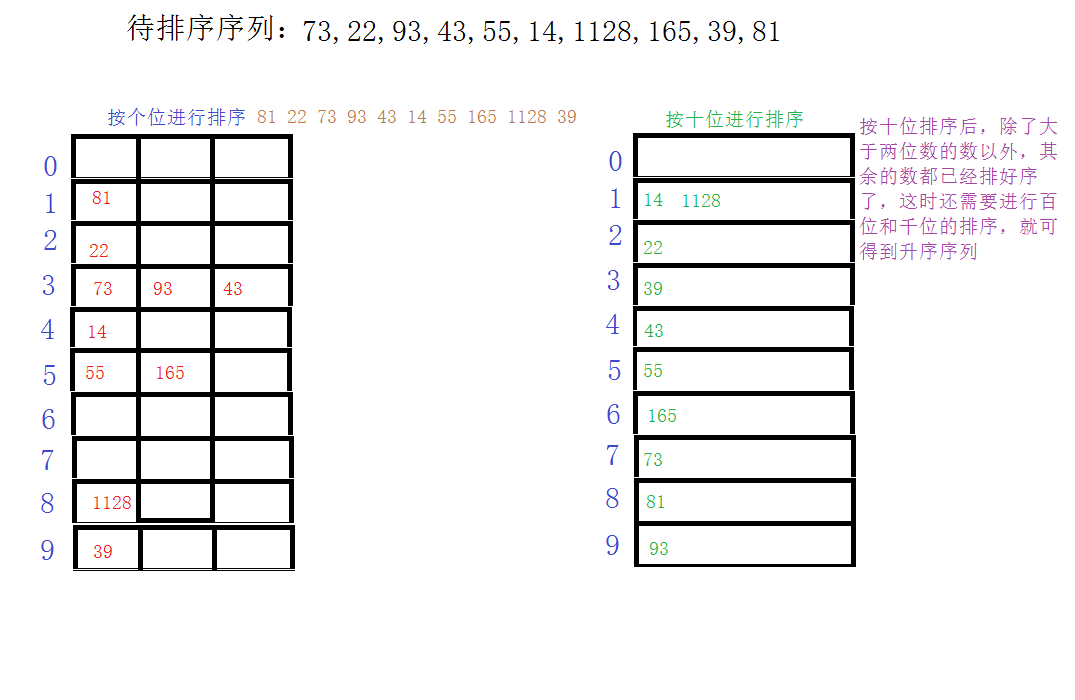
第一趟排序确定出了个位数的序列,同时它也确保了下面的几趟排序如果碰见相同的高位的话,个位的序列在前的会先被遍历到。
但是,如图所示,排序的序列中个位出现的最多的次数是3,所以我们开辟了一个9行3列的二维数组来进行存放数据。但是如果出现某个位的数数字全部相同,那么是非常浪费空间大小的,下面我们实现的对矩阵进行压缩存储的方法来减少空间的浪费。

我们通过记录各个位置上的元
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 233
233











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









