









【转】机器学习入门——浅谈神经网络
本文转自:http://tieba.baidu.com/p/3013551686?pid=49703036815&see_lz=1#
个人觉得很全,特别适合接触神经网络的新手。
先从回归(Regression)问题说起。我在本吧已经看到不少人提到如果想实现强AI,就必须让机器学会观察并总结规律的言论。具体地说,要让机器观察什么是圆的,什么是方的,区分各种颜色和形状,然后根据这些特征对某种事物进行分类或预测。其实这就是回归问题。
如何解决回归问题?我们用眼睛看到某样东西,可以一下子看出它的一些基本特征。可是计算机呢?它看到的只是一堆数字而已,因此要让机器从事物的特征中找到规律,其实是一个如何在数字中找规律的问题。

例:假如有一串数字,已知前六个是1、3、5、7,9,11,请问第七个是几?
你一眼能看出来,是13。对,这串数字之间有明显的数学规律,都是奇数,而且是按顺序排列的。
那么这个呢?前六个是0.14、0.57、1.29、2.29、3.57、5.14,请问第七个是几?
这个就不那么容易看出来了吧!我们把这几个数字在坐标轴上标识一下,可以看到如下图形:
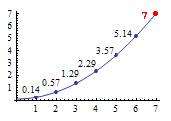
用曲线连接这几个点,延着曲线的走势,可以推算出第七个数字——7。
由此可见,回归问题其实是个曲线拟合(Curve Fitting)问题。那么究竟该如何拟合?机器不可能像你一样,凭感觉随手画一下就拟合了,它必须要通过某种算法才行。
假设有一堆按一定规律分布的样本点,下面我以拟合直线为例,说说这种算法的原理。
其实很简单,先随意画一条直线,然后不断旋转它。每转一下,就分别计算一下每个样本点和直线上对应点的距离(误差),求出所有点的误差之和。这样不断旋转,当误差之和达到最小时,停止旋转。说得再复杂点,在旋转的过程中,还要不断平移这条直线,这样不断调整,直到误差最小时为止。这种方法就是著名的梯度下降法(Gradient Descent)。为什么是梯度下降呢?在旋转的过程中,当误差越来越小时,旋转或移动的量也跟着逐渐变小,当误差小于某个很小的数,例如0.0001时,我们就可以收工(收敛, Converge)了。啰嗦一句,如果随便转,转过头了再往回转,那就不是梯度下降法。
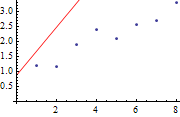
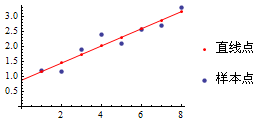
我们知道,直线的公式是y=kx+b,k代表斜率,b代表偏移值(y轴上的截距)。也就是说,k可以控制直线的旋转角度,b可以控制直线的移动。强调一下,梯度下降法的实质是不断的修改k、b这两个参数值,使最终的误差达到最小。
求误差时使用 累加(直线点-样本点)^2,这样比直接求差距 累加(直线点-样本点) 的效果要好。这种利用最小化误差的平方和来解决回归问题的方法叫最小二乘法(Least Square Method)。
问题到此使似乎就已经解决了,可是我们需要一种适应于各种曲线拟合的方法,所以还需要继续深入研究。
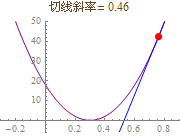
我们根据拟合直线不断旋转的角度(斜率)和拟合的误差画一条函数曲线,如图:
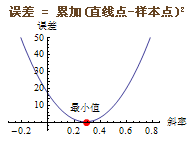
从图中可以看出,误差的函数曲线是个二次曲线,凸函数(下凸, Convex),像个碗的形状,最小值位于碗的最下端。如果在曲线的最底端画一条切线,那么这条切线一定是水平的,在图中可以把横坐标轴看成是这条切线。如果能求出曲线上每个点的切线,就能得到切线位于水平状态时,即切线斜率等于0时的坐标值,这个坐标值就是我们要求的误差最小值和最终的拟合直线的最终斜率。
这样,梯度下降的问题集中到了切线的旋转上。切线旋转至水平时,切线斜率=0,误差降至最小值。
切线每次旋转的幅度叫做学习率(Learning Rate),加大学习率会加快拟合速度,但是如果调得太大会导致切线旋转过度而无法收敛。 [学习率其实是个预先设置好的参数,不会每次变化,不过可以影响每次变化的幅度。]
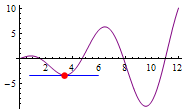
注意:对于凹凸不平的误差函数曲线,梯度下降时有可能陷入局部最优解。下图的曲线中有两个坑,切线有可能在第一个坑的最底部趋于水平。
微分就是专门求曲线切线的工具,求出的切线斜率叫做导数(Derivative),用dy/dx或f’(x)表示。扩展到多变量的应用,如果要同时求多个曲线的切线,那么其中某个切线的斜率就叫偏导数(Partial Derivative),用∂y/∂x表示,∂读“偏(partial)”。由于实际应用中,我们一般都是对多变量进行处理,我在后面提到的导数也都是指偏导数。
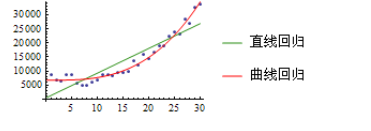
以上是线性回归(Linear Regression)的基本内容,以此方法为基础,把直线公式改为曲线公式,还可以扩展出二次回归、三次回归、多项式回归等多种曲线回归。下图是Excel的回归分析功能。
在多数情况下,曲线回归会比直线回归更精确,但它也增加了拟合的复杂程度。
直线方程y=kx+b改为二次曲线方程y=ax^2+bx+c时,参数(Parameter)由2个(分别是k、b)变为3个(分别是a、b、c),特征(Feature)由1个(x)变为2个(x^2和x)。三次曲线和复杂的多项式回归会增加更多的参数和特征。
前面讲的是总结一串数字的规律,现实生活中我们往往要根据多个特征(多串数字)来分析一件事情,每个原始特征我们都看作是一个维度(Dimension)。例如一个学生的学习成绩好坏要根据语文、数学、英语等多门课程的分数来综合判断,这里每门课程都是一个维度。当使用二次曲线和多变量(多维)拟合的情况下,特征的数量会剧增,特征数=维度^2/2 这个公式可以大概计算出特征增加的情况,例如一个100维的数据,二次多项式拟合后,特征会增加到100*100/2=5000个。
下面是一张50*50像素的灰度图片,如果用二次多项式拟合的话,它有多少个特征呢?——大约有3百万!

它的维度是50*50=2500,特征数=2500*2500/2=3,125,000。如果是彩色图片,维度会增加到原来的3倍,那么特征数将增加到接近3千万了!

这么小的一张图片,就有这么巨大的特征量,可以想像一下我们的数码相机拍下来的照片会有多大的特征量!而我们要做的是从十万乃至亿万张这样的图片中找规律,这可能吗?
很显然,前面的那些回归方法已经不够用了,我们急需找到一种数学模型,能够在此基础上不断减少特征,降低维度。
于是,“人工神经网络(ANN, Artificial Neural Network)”就在这样苛刻的条件下粉墨登场了,神经科学的研究成果为机器学习领域开辟了广阔的道路。
神经元
有一种假说:“智能来源于单一的算法(One Learning Algorithm)”。如果这一假说成立,那么利用单一的算法(神经网络)处理世界上千变万化的问题就成为可能。我们不必对万事万物进行编程,只需采用以不变应万变的策略即可。有越来越多的证据证明这种假说,例如人类大脑发育初期,每一部分的职责分工是不确定的,也就是说,人脑中负责处理声音的部分其实也可以处理视觉影像
下图是单个神经元(Neuron),或者说一个脑细胞的生理结构:
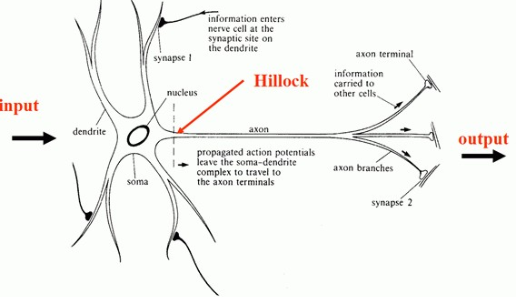
下面是单个神经元的数学模型,可以看出它是生理结构的简化版,模仿的还挺像:
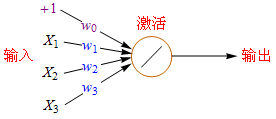
解释一下:+1代表偏移值(偏置项, Bias Units);X1,X2,X2代表初始特征;w0,w1,w2,w3代表权重(Weight),即参数,是特征的缩放倍数;特征经过缩放和偏移后全部累加起来,此后还要经过一次激活运算然后再输出。激活函数有很多种,后面将会详细说明。
举例说明:

X1*w1+X2*w2+…+Xn*wn这种计算方法称为加权求和(Weighted Sum)法,此方法在线性代数里极为常用。加权求和的标准数学符号是,不过为了简化,我在教程里使用女巫布莱尔的符号表示,
刚好是一个加号和一个乘号的组合。
这个数学模型有什么意义呢?下面我对照前面那个 y=kx+b 直线拟合的例子来说明一下。
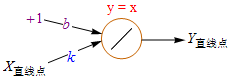
这时我们把激活函数改为Purelin(45度直线),Purelin就是y=x,代表保持原来的值不变。
这样输出值就成了 Y直线点 = b + X直线点*k,即y=kx+b。看到了吧,只是换了个马甲而已,还认的出来吗?下一步,对于每个点都进行这种运算,利用Y直线点和Y样本点计算误差,把误差累加起来,不断地更新b、k的值,由此不断地移动和旋转直线,直到误差变得很小时停住(收敛)。这个过程完全就是前面讲过的梯度下降的线性回归。
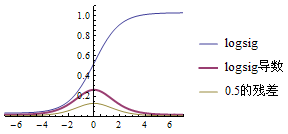
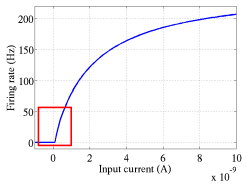
一般直线拟合的精确度要比曲线差很多,那么使用神经网络我们将如何使用曲线拟合?答案是使用非线性的激活函数即可,最常见的激活函数是Sigmoid(S形曲线),Sigmoid有时也称为逻辑回归(Logistic Regression),简称logsig。logsig曲线的公式如下:
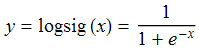
还有一种S形曲线也很常见到,叫双曲正切函数(tanh),或称tansig,可以替代logsig。
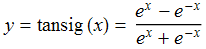
下面是它们的函数图形,从图中可以看出logsig的数值范围是0~1,而tansig的数值范围是-1~1。
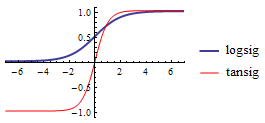
自然常数e
公式中的e叫自然常数,也叫欧拉数,e=2.71828…。e是个很神秘的数字,它是“自然律”的精髓,其中暗藏着自然增长的奥秘,它的图形表达是旋涡形的螺线。

融入了e的螺旋线,在不断循环缩放的过程中,可以完全保持它原有的弯曲度不变,就像一个无底的黑洞,吸进再多的东西也可以保持原来的形状。这一点至关重要!它可以让我们的数据在经历了多重的Sigmoid变换后仍维持原先的比例关系。
e是怎么来的?e = 1 + 1/1! + 1/2! + 1/3! + 1/4! + 1/5! + 1/6! + 1/7! + … = 1 + 1 + 1/2 + 1/6 + 1/24 + 1/120+ … ≈ 2.71828 (!代表阶乘,3!=1*2*3=6)
再举个通俗点的例子:从前有个财主,他特别贪财,喜欢放债。放出去的债年利率为100%,也就是说借1块钱,一年后要还给他2块钱。有一天,他想了个坏主意,要一年算两次利息,上半年50%,下半年50%,这样上半年就有1块5了,下半年按1块5的50%来算,就有1.5/2=0.75元,加起来一年是:上半年1.5+下半年0.75=2.25元。用公式描述,就是(1+50%)(1+50%)=(1+1/2)^2=2.25元。可是他又想,如果按季度算,一年算4次,那岂不是更赚?那就是(1+1/4)^4=2.44141,果然更多了。他很高兴,于是又想,那干脆每天都算吧,这样一年下来就是(1+1/365)^365=2.71457。然后他还想每秒都算,结果他的管家把他拉住了,说要再算下去别人都会疯掉了。不过财主还是不死心,算了很多年终于算出来了,当x趋于无限大的时候,e=(1+1/x)^x≈ 2.71828,结果他成了数学家。
e在微积分领域非常重要,e^x的导数依然是e^x,自己的导数恰好是它自己,这种巧合在实数范围内绝无仅有。

一些不同的称呼:

e^x和e^-x的图形是对称的;ln(x)是e^x的逆函数,它们呈45度对称。
神经网络
好了,前面花了不少篇幅来介绍激活函数中那个暗藏玄机的e,下面可以正式介绍神经元的网络形式了。
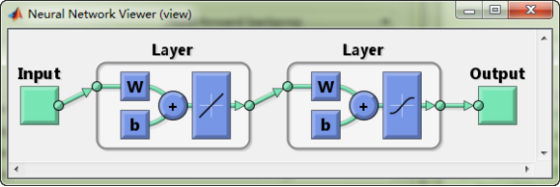
下图是几种比较常见的网络形式:
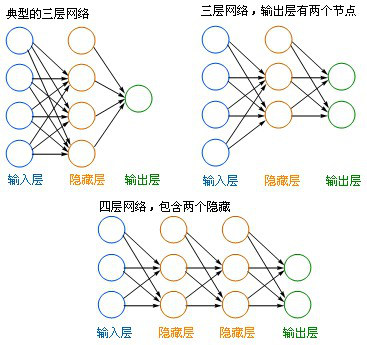
- 左边蓝色的圆圈叫“输入层”,中间橙色的不管有多少层都叫“隐藏层”,右边绿色的是“输出层”。
- 每个圆圈,都代表一个神经元,也叫节点(Node)。
- 输出层可以有多个节点,多节点输出常常用于分类问题。
- 理论证明,任何多层网络可以用三层网络近似地表示。
- 一般凭经验来确定隐藏层到底应该有多少个节点,在测试的过程中也可以不断调整节点数以取得最佳效果。
计算方法:
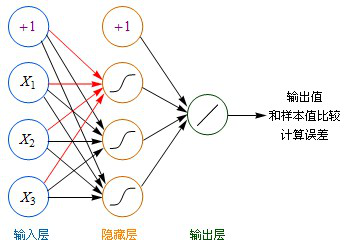
- 虽然图中未标识,但必须注意每一个箭头指向的连线上,都要有一个权重(缩放)值。
- 输入层的每个节点,都要与的隐藏层每个节点做点对点的计算,计算的方法是加权求和+激活,前面已经介绍过了。(图中的红色箭头指示出某个节点的运算关系)
- 利用隐藏层计算出的每个值,再用相同的方法,和输出层进行计算。
- 隐藏层用都是用Sigmoid作激活函数,而输出层用的是Purelin。这是因为Purelin可以保持之前任意范围的数值缩放,便于和样本值作比较,而Sigmoid的数值范围只能在0~1之间。
- 起初输入层的数值通过网络计算分别传播到隐藏层,再以相同的方式传播到输出层,最终的输出值和样本值作比较,计算出误差,这个过程叫前向传播(Forward Propagation)。
前面讲过,使用梯度下降的方法,要不断的修改k、b两个参数值,使最终的误差达到最小。神经网络可不只k、b两个参数,事实上,网络的每条连接线上都有一个权重参数,如何有效的修改这些参数,使误差最小化,成为一个很棘手的问题。从人工神经网络诞生的60年代,人们就一直在不断尝试各种方法来解决这个问题。直到80年代,误差反向传播算法(BP算法)的提出,才提供了真正有效的解决方案,使神经网络的研究绝处逢生。

BP算法是一种计算偏导数的有效方法,它的基本原理是:利用前向传播最后输出的结果来计算误差的偏导数,再用这个偏导数和前面的隐藏层进行加权求和,如此一层一层的向后传下去,直到输入层(不计算输入层),最后利用每个节点求出的偏导数来更新权重。
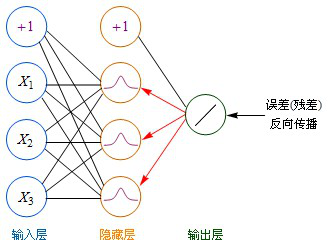
为了便于理解,后面我一律用“残差(error term)”这个词来表示误差的偏导数。
输出层→隐藏层:残差 = -(输出值-样本值) * 激活函数的导数
隐藏层→隐藏层:残差 = (右层每个节点的残差加权求和)* 激活函数的导数
如果输出层用Purelin作激活函数,Purelin的导数是1,输出层→隐藏层:残差 = -(输出值-样本值)
如果用Sigmoid(logsig)作激活函数,那么:Sigmoid导数 = Sigmoid*(1-Sigmoid)
输出层→隐藏层:残差 = -(Sigmoid输出值-样本值) * Sigmoid*(1-Sigmoid) = -(输出值-样本值)输出值(1-输出值)
隐藏层→隐藏层:残差 = (右层每个节点的残差加权求和)* 当前节点的Sigmoid*(1-当前节点的Sigmoid)
如果用tansig作激活函数,那么:tansig导数 = 1 - tansig^2
残差全部计算好后,就可以更新权重了:
输入层:权重增加 = 当前节点的Sigmoid * 右层对应节点的残差 * 学习率
隐藏层:权重增加 = 输入值 * 右层对应节点的残差 * 学习率
偏移值的权重增加 = 右层对应节点的残差 * 学习率
学习率前面介绍过,学习率是一个预先设置好的参数,用于控制每次更新的幅度。
此后,对全部数据都反复进行这样的计算,直到输出的误差达到一个很小的值为止。
以上介绍的是目前最常见的神经网络类型,称为前馈神经网络(FeedForward Neural Network),由于它一般是要向后传递误差的,所以也叫BP神经网络(Back Propagation Neural Network)。
BP神经网络的特点和局限:
- BP神经网络可以用作分类、聚类、预测等。需要有一定量的历史数据,通过历史数据的训练,网络可以学习到数据中隐含的知识。在你的问题中,首先要找到某些问题的一些特征,以及对应的评价数据,用这些数据来训练神经网络。
- BP神经网络主要是在实践的基础上逐步完善起来的系统,并不完全是建立在仿生学上的。从这个角度讲,实用性 > 生理相似性。
- BP神经网络中的某些算法,例如如何选择初始值、如何确定隐藏层的节点个数、使用何种激活函数等问题,并没有确凿的理论依据,只有一些根据实践经验总结出的有效方法或经验公式。
- BP神经网络虽然是一种非常有效的计算方法,但它也以计算超复杂、计算速度超慢、容易陷入局部最优解等多项弱点著称,因此人们提出了大量有效的改进方案,一些新的神经网络形式也层出不穷。
文字的公式看上去有点绕,下面我发一个详细的计算过程图。
参考这个:http://www.myreaders.info/03_Back_Propagation_Network.pdf 我做了整理
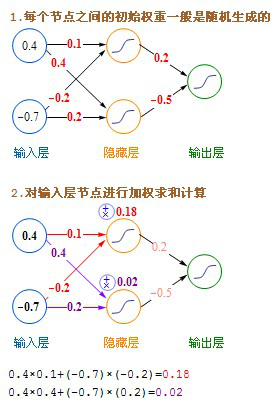

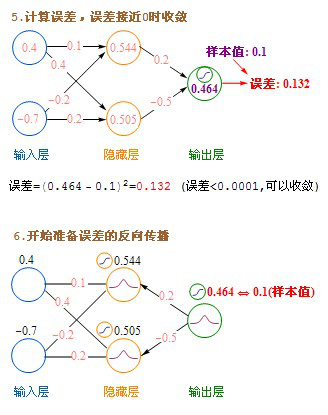
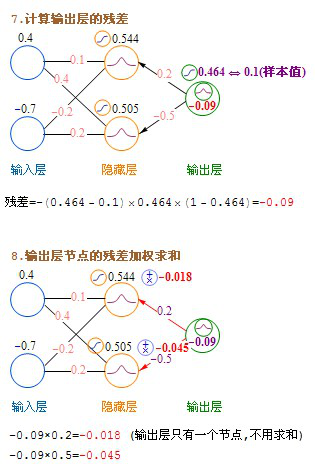
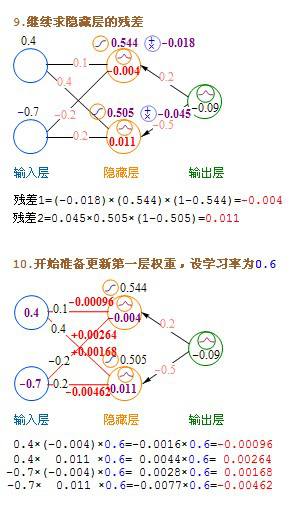

这里介绍的是计算完一条记录,就马上更新权重,以后每计算完一条都即时更新权重。实际上批量更新的效果会更好,方法是在不更新权重的情况下,把记录集的每条记录都算过一遍,把要更新的增值全部累加起来求平均值,然后利用这个平均值来更新一次权重,然后利用更新后的权重进行下一轮的计算,这种方法叫批量梯度下降(Batch Gradient Descent)。
推荐的入门级学习资源:
Andrew Ng的《机器学习》公开课: https://class.coursera.org/ml
Coursera公开课笔记中文版(神经网络的表示): http://52opencourse.com/139/coursera公开课笔记-斯坦福大学机器学习第八课-神经网络的表示-neural-networks-representation
Coursera公开课视频(神经网络的学习): http://52opencourse.com/289/coursera公开课视频-斯坦福大学机器学习第九课-神经网络的学习-neural-networks-learning
斯坦福深度学习中文版: http://deeplearning.stanford.edu/wiki/index.php/UFLDL教程
谢谢大家的支持。
今天先发个实际编程操作教程,介绍一下Matlab神经网络工具箱的用法,后面有空再加些深入点的知识。
关于Matlab的入门教程,参看这个帖子:http://tieba.baidu.com/p/2945924081
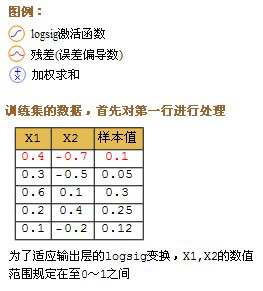
例1:我们都知道,面积=长*宽,假如我们有一组数测量据如下:
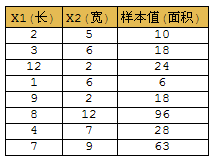
我们利用这组数据来训练神经网络。(在Matlab中输入以下的代码,按回车即可执行)
p = [2 5; 3 6; 12 2; 1 6; 9 2; 8 12; 4 7; 7 9]’; % 特征数据X1,X2
t = [10 18 24 6 18 96 28 63]; % 样本值
net = newff(p, t, 20); % 创建一个BP神经网络 ff=FeedForward
net = train(net, p, t); % 用p,t数据来训练这个网络
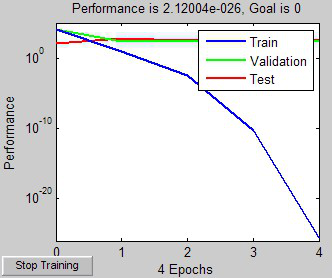
出现如下的信息,根据蓝线的显示,可以看出最后收敛时,误差已小于10^-20。
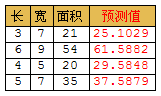
你也许会问,计算机难道这样就能学会乘法规则吗?不用背乘法口诀表了?先随便选几个数字,试试看:
s = [3 7; 6 9; 4 5; 5 7]’; % 准备一组新的数据用于测试
y = sim(net, s) % 模拟一下,看看效果
% 结果是:25.1029 61.5882 29.5848 37.5879
看到了吧,预测结果和实际结果还是有差距的。不过从中也能看出,预测的数据不是瞎蒙的,至少还是有那么一点靠谱。如果训练集中的数据再多一些的话,预测的准确率还会大幅度提高。
你测试的结果也许和我的不同,这是因为初始化的权重参数是随机的,可能会陷入局部最优解,所以有时预测的结果会很不理想。
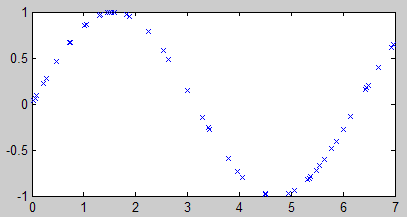
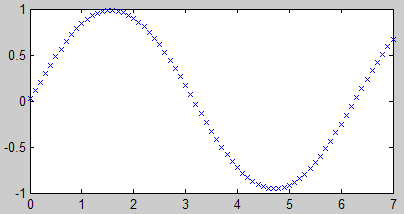
例2:下面测试一下拟合正弦曲线,这次我们随机生成一些点来做样本。
p = rand(1,50)*7 % 生成1行50个0~7之间的随机数
t = sin(p) % 计算正弦曲线
s = [0:0.1:7]; % 生成0~7的一组数据,间隔0.1,用于模拟测试
plot(p, t, ‘x’) % 画散点图
net = newff(p, t, 20); % 创建神经网络
net = train(net, p, t); % 开始训练
y = sim(net, s); % 模拟
plot(s, y, ‘x’) % 画散点图
从图中看出,这次的预测结果显然是不理想的,我们需要设置一些参数来调整。
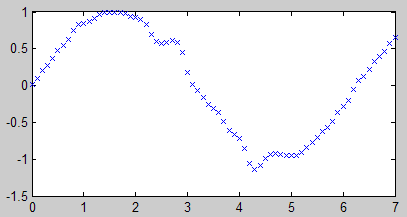
下面的设置是一种标准的批量梯度下降法的配置。
% 创建3层神经网络 [隐藏层10个节点->logsig, 输出层1个节点->purelin] traingd代表梯度下降法
net = newff(p, t, 10, {‘logsig’ ‘purelin’}, ‘traingd’); % 10不能写成[10 1]
% 设置训练参数
net.trainparam.show = 50; % 显示训练结果(训练50次显示一次)
net.trainparam.epochs = 500; % 总训练次数
net.trainparam.goal = 0.01; % 训练目标:误差<0.01
net.trainParam.lr = 0.01; % 学习率(learning rate)
net = train(net, p, t); % 开始训练
注意:newff的第三个参数10不能写成[10 1],否则就是4层网络,两个隐藏层,分别是10个和1个节点。这个很容易弄错。(输出层的节点数程序会自动根据t的维度自动判断,所以不用指定)
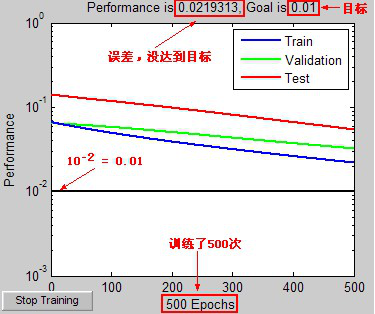
y = sim(net, s); % 模拟
plot(s, y, ‘x’) % 画散点图
这时的效果显然更差了。
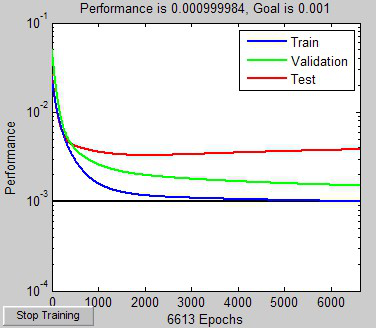
把精度调高一点看看。训练次数加到9999,误差<0.001;学习率调到0.06,希望能加快点速度。
% 创建2层神经网络 [隐藏层10个节点->logsig, 输出层1个节点->purelin] traingd代表梯度下降法
net = newff(p, t, 10, {‘logsig’ ‘purelin’}, ‘traingd’);
% 设置训练参数
net.trainparam.show = 50; % 每间隔50次显示一次训练结果
net.trainparam.epochs = 9999; % 总训练次数
net.trainparam.goal = 0.001; % 训练目标:误差<0.001
net.trainParam.lr = 0.06; % 学习率(learning rate)
net = train(net, p, t); % 开始训练
标准的批量梯度下降法的速度确实够慢,这次计算花了一分多钟。
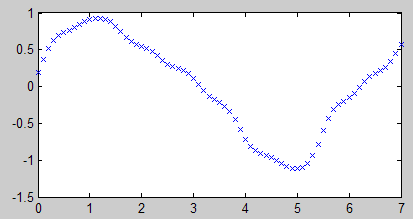
y = sim(net, s); % 模拟
plot(s, y, ‘x’) % 画散点图
效果比上次稍好一点。不过这条曲线显得坑坑洼洼的很难看,这是一种过拟合(Overfitting)现象,与之相反的是欠拟合(Underfitting)。
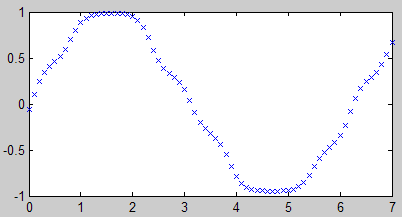
先来解决速度问题,把traingd改为trainlm即可。trainlm使用LM算法,是介于牛顿法和梯度下降法之间的一种非线性优化方法,不但会加快训练速度,还会减小陷入局部最小值的可能性,是Matlab的默认值。
net = newff(p, t, 10, {‘logsig’ ‘purelin’}, ‘trainlm’);
… 后面的代码不变
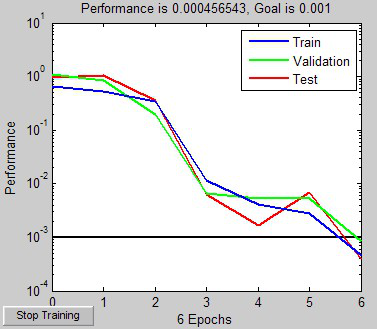
这个速度比较惊叹了,1秒钟之内完成,只做了6轮计算,效果也好了一些。不过,LM算法也有弱点,它占用的内存非常大,所以没把其它算法给淘汰掉。
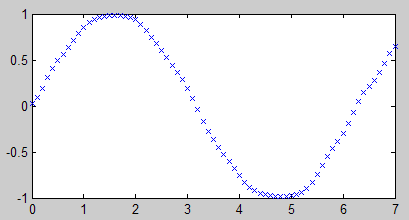
下面解决过拟合问题,把隐藏层的节点数目设少一点就行了。
net = newff(p, t, 3, {‘logsig’ ‘purelin’}, ‘trainlm’);
… 后面的代码不变
这回终于达到满意的效果了。(有时会出现局部最优解,可以多试几次)
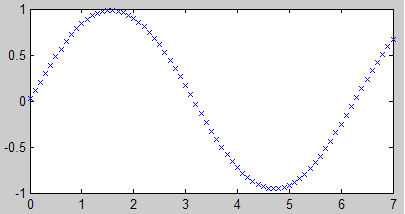
如果节点数目太少,会出现欠拟合的情况。
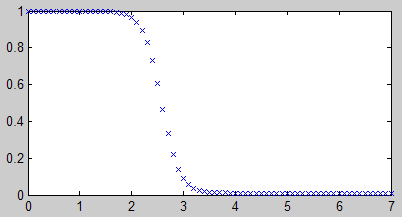
关于隐藏层的节点个数,一般是要凭感觉去调的。如果训练集的维数比较多,调节起来比较耗时间,这时可以根据经验公式上下浮动地去调整。
下面给出几个经验公式供参考:

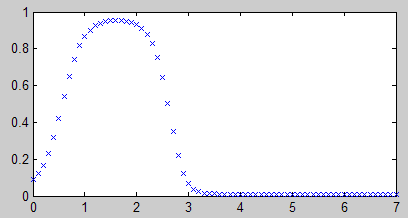
如果把输出层改为logsig激活会是什么样子呢?
net = newff(p, t, 3, {‘logsig’ ‘logsig’}); % 创建神经网络
net = train(net, p, t); % 开始训练
y = sim(net, s); % 模拟
plot(s, y, ‘x’) % 画散点图
可以看出,-1~0范围之间的点都变为0了。使用logsig输出时要想得到完整数值范围的效果,必须先对数据进行归一化才行。
归一化(Normalization),也叫标准化,就是把一堆数字按比例缩放到0~1或-1~1的范围。
虽然用Purelin输出可以不必归一化,但归一化能在一定程度上加快收敛速度,因此被许多教程定为训练前的必须步骤。
公式为:归一值 = (当前值x-最小值min)/(最大值max-最小值min)
如果限定了范围,公式为:y = (ymax-ymin)*(x-xmin)/(xmax-xmin) + ymin;
0.1~0.9的范围:(0.9-0.1)(x-min)/(max-min)(0.9-0.1)+0.1
把5, 2, 6, 3这四个数归一化:
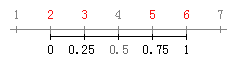
Matlab的归一化命令为:mapminmax
注:网上的不少教程里用premnmx命令来归一化,要注意Matlab版本R2007b和R2008b,premnmx在处理单列数据时有bug,Matlab已给出了警告,R2009a版才修正。因此推荐使用mapminmax。mapminmax的输入输出值和premnmx是行列颠倒的,使用时要注意代码中是否添加转置符号。
a = [5, 2, 6, 3];
b = mapminmax(a, 0, 1) % 归一化到0~1之间
% b = 0.7500 0 1.0000 0.2500
c = mapminmax(a) % 归一化到-1~1之间
% c = 0.5000 -1.0000 1.0000 -0.5000
反归一化(Denormalization)就是按归一化时的比例还原数值。
a = [5, 2, 6, 3];
[c,PS] = mapminmax(a); % PS记录归一化时的比例
mapminmax(‘reverse’, c, PS) % 利用PS反归一化
% ans = 5 2 6 3
神经网络的归一化(0~1范围)代码:
p = rand(1,50)*7; % 特征数据
t = sin(p); % 样本值
s = [0:0.1:7]; % 测试数据
[pn, ps] = mapminmax(p, 0, 1); % 特征数据归一化
[tn, ts] = mapminmax(t, 0, 1); % 样本值归一化
sn = mapminmax(‘apply’, s, ps); % 测试数据,按ps比例缩放
net = newff(pn, tn, [5 1], {‘logsig’ ‘logsig’}); % 创建神经网络
net = train(net, pn, tn); % 开始训练
yn = sim(net, sn); % 模拟
y = mapminmax(‘reverse’, yn, ts); % 按ps的比例还原
plot(s, y, ‘x’) % 画散点图
神经网络工具箱还有一个UI图形操作界面,执行nntool就可以打开。我觉得不如写代码方便,所以不怎么用。我提供一个相关的教程链接,有兴趣的可以看一下:matlab神经网络工具箱创建神经网络 - http://blog.新浪.com.cn/s/blog_8684880b0100vxtv.html (新浪替换成sina)
关于Sigmoid的由来,中文的网站上很少有提及的。下面简单讲一下,希望能给大家拓展一下思路。
PS: 这里的公式我都给出了求解过程,但如今这个年头,用手工解题的人越来越少了,一般的方程用软件来解就行了。
例如解Sigmoid微分方程,可以用Matlab去解:
dsolve(‘Dx=x*(1-x)’)
% ans = 1/(1+exp(-t)*C1)
如果想得到求解的步骤或更详细的信息,推荐使用Wolfram:http://www.wolframalpha.com
在Wolfram的搜索框输入 x’=x(1-x) 即可。
logsig
Sigmoid函数(S形函数,Logistic Function)是受统计学模型的启发而产生的激活函数。
基于生物学的神经元激活函数是这样的:
参看:http://eprints.pascal-network.org/archive/00008596/01/glorot11a.pdf
实践证明了基于统计学的Sigmoid函数激活效果要比基于生物学的模型好,而且计算起来很方便,所以说不能以机器和人的相似度为标准来判断AI算法的好坏。
Sigmoid函数原先是个描述人口增长的数学模型,1838提出,给出的是导数形式(概率密度)。人口增长规律:起初阶段大致是指数增长;然后逐渐开始变得饱和,增长变慢;达到成熟时几乎停止增长;整个过程形如一条S型曲线。

导数的形式知道了,那么它的原函数是什么样子呢?已知导数求原函数,用统计学的话来讲,即根据概率密度函数(PDF)求累积分布函数(CDF),不定积分(Indefinite Integral)就是专门用来做这个的工具。
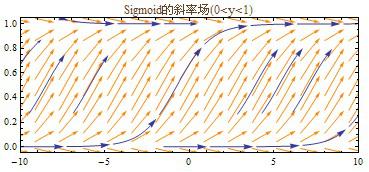
根据不定积分的知识可知,由于常数项是可变的,所以存在无数个原函数的可能。让我们先用图解法看一下:既然导数是函数曲线的斜率,那么可以把一定数值范围内的斜率,都画成一根根的短斜线,组成斜率场(Slope Fields, Direction Fields),然后根据这些斜线的走势,画出积分曲线。
Matlab可以用quiver命令来画斜率场。
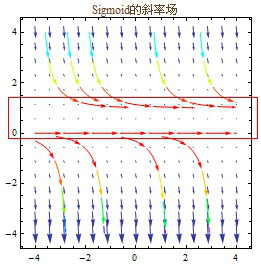
从上图中可以看出,在y轴的0~1之间是个分水岭,0和1处的方向趋于水平。下面放大0~1的范围看看是什么样子的。
看到了吧,我们要的Logistic Sigmoid就在这里呢。
下面给出符号求解的过程:

tansig
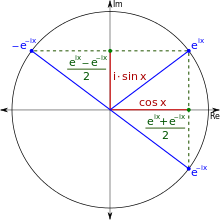
双曲正切函数(双极S形函数, tanh, Hyperbolic Tangent),读tanch,18世纪就已经出现了。它的定义是:tanh(x)=sinh(x)/cosh(x),可以由著名的欧拉公式(Euler’s formula)推导出来。
用tanh作激活函数,收敛比较快,效果比Logistic函数还要好。
欧拉公式: i是虚数(Imaginary Number)单位,它的定义是: (即i^2 = -1)
题外话:根据上面的公式变换,可以得出史上最美的数学公式: 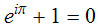

求tanh的导数:

logsig和tansig的关系:
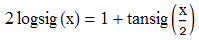















 904
904

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









