







 本文介绍了Spark计算引擎的核心特性,包括DAG执行和内存管理,并提及Spark支持的运行模式如Hadoop、Mesos和Standalone。相较于MapReduce,Spark在处理多轮迭代计算和容错性方面更具优势,其RDD(弹性分布式数据集)提供了更高效的计算模型。Spark通过Lineage实现数据容错,而MapReduce则主要依赖于磁盘存储和作业级别的容错。
本文介绍了Spark计算引擎的核心特性,包括DAG执行和内存管理,并提及Spark支持的运行模式如Hadoop、Mesos和Standalone。相较于MapReduce,Spark在处理多轮迭代计算和容错性方面更具优势,其RDD(弹性分布式数据集)提供了更高效的计算模型。Spark通过Lineage实现数据容错,而MapReduce则主要依赖于磁盘存储和作业级别的容错。
1.spark计算
引擎:
1.快速 DAG(有向无环图) Memory
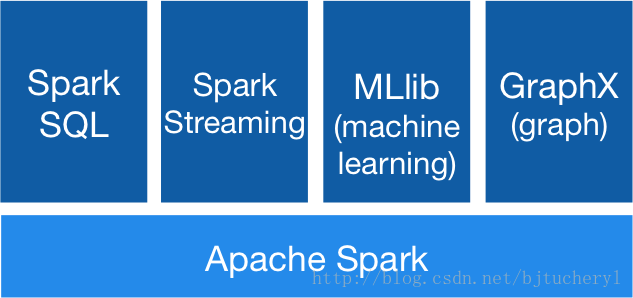
2.通用 spark sparkSQL、SparkStreaming等相当于在spark平台上的 jar包 需要时直接以Jar包的方式导入
2运行模式.
Hadoop、Mesos、standlone。
可以处理任意类型的hadoop数据源 如hbase、hive等
3.MapReduce与Spark相比,有哪些异同点
1.基本原理上
a。MapReduce:基于磁盘的大数据批量处理系统
b。Spark:基于RDD(弹性分布式数据集)数据处理、显示的将RDD数据存储到磁盘和内存中
2.模型上:
a.MapReduce:可以处理超大规模数据,适合日志分析挖掘等较少的迭代的长任务
需求。很好的结合了数据的分布式的存储和分布式的计算。
b.Spark:数据的挖掘、机器学习等多轮迭代式的计算任务
容错性:
a。数据的容错性
b。节点的容错性
Spark Linage
具体内容
在spark中,一个应用程序中包含多个job任务,在mapreduce中一个job就是一个应用
sc.textFile(“hdfs://hadoop:8020/user/sp
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3773
3773

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









