






实验设计的思路、主要算法步骤
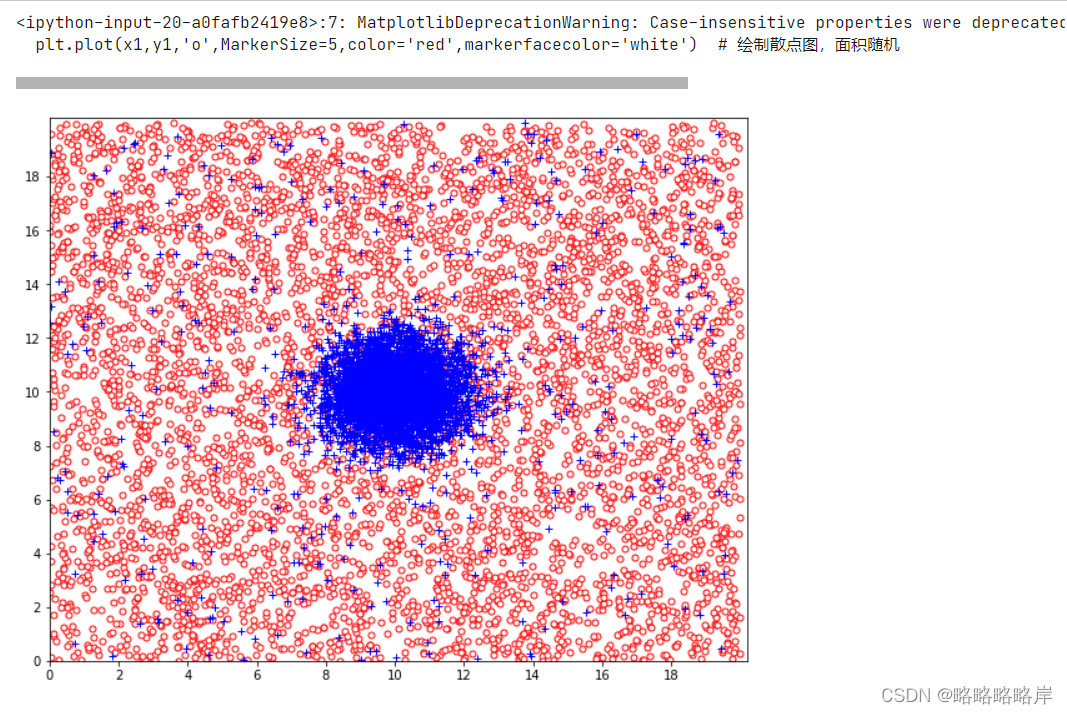
生成随机的高斯分布和均匀分布
num, dim = 10800, 2
np.random.seed(13)#表示种子相同,从而生成的随机数相同。
#o类的实例服从均匀分布
plt.figure(figsize=(10,8))
x1=np.random.uniform(0,20,5400)#获取开始值0和结束值20作为参数,返回一个浮点型的随机数
y1=np.random.uniform(0,20,5400)
plt.plot(x1,y1,'o',MarkerSize=5,color='red',markerfacecolor='white') # 绘制散点图,面积随机
#高斯分布数据点
#“+”类中,5000个实例的生成服从二元高斯分布
mean = [10,10]#平均值
cov = [[1,0.0],[0.0,1]]#协方差矩阵
gdata = np.random.multivariate_normal(mean,cov,5000)
#print('gdata数据',gdata[:,0])
plt.plot(gdata[:,0],gdata[:,1],'+',c='blue')
#"+"类中其余400个实例的采样与“o”类一样服从均匀分布
x2=np.random.uniform(0,20,400)#获取开始值0和结束值20作为参数,返回一个浮点型的随机数
y2=np.random.uniform(0,20,400)
#绘图
plt.plot(x2,y2,'+',color='blue')
plt.xlim(x1.min()*1.01,x1.max()*1.01)# 调整坐标轴,减小上下左右的留白
plt.ylim(y1.min()*1.01,y1.max()*1.01)
x=range(0,20,2)
y=range(0,20,2)
plt.xticks(x)#重新划分x轴坐标刻度
plt.yticks(y)
plt.show()
#print(np.corrcoef(gdata[:,0],gdata[:,1]))
数据处理
#合并数据,'o','+'
label1=[]
for i in range(5400):
i=0
label1.append(i)
A=[x1,y1,label1]
#print('x1数据',y1)
label2=[]
for i in range(5000):
i=1
label2.append(i)
B=[gdata[:,0],gdata[:,1],label2]
label3=[]
for i in range(400):
i=1
label3.append(i)
C=[x2,y2,label3]
#print('x2数据',x2)
#将其转化成dataframe格式
data_1 = DataFrame(A).T
data_2 = DataFrame(B).T
data_3 = DataFrame(C).T
#data_1.head()
frames=[data_1,data_2,data_3]
data=pd.concat(frames)
#将列名改成x1和x2
data.columns = ['x','y','labels']
data = data.reset_index(drop = True)#将这个index重新排列
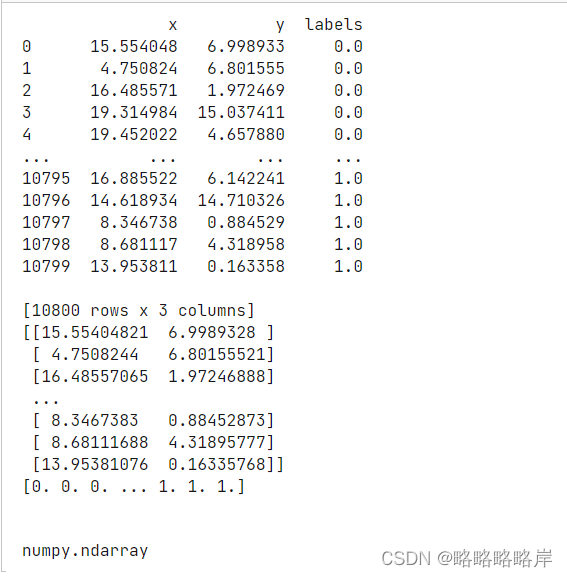
print(data)
#
X=data[['x','y']].values#将DataFrame的特定列x,y转换为ndarray
y=data['labels'].values
print(X)
print(y)
type(y)
划分数据集,标准化
from sklearn.model_selection import train_test_split
#0%的数据进行训练,剩余90%用于测试。
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.9, random_state=0,stratify=y)
#标准化
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
sc.fit(X)
X_train_std = sc.transform(X_train)
X_test_std = sc.transform(X_test)
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier(criterion='entropy', max_depth=3, random_state=0)
tree.fit(X_train, y_train)
X_combined = np.vstack((X_train, X_test))
y_combined = np.hstack((y_train, y_test))
plot_decision_regions(X_combined, y_combined,
classifier=tree, test_idx=range(105,150))
plt.xlabel('x')
plt.ylabel('y')
plt.legend(loc='upper left')
plt.tight_layout()
plt.show()
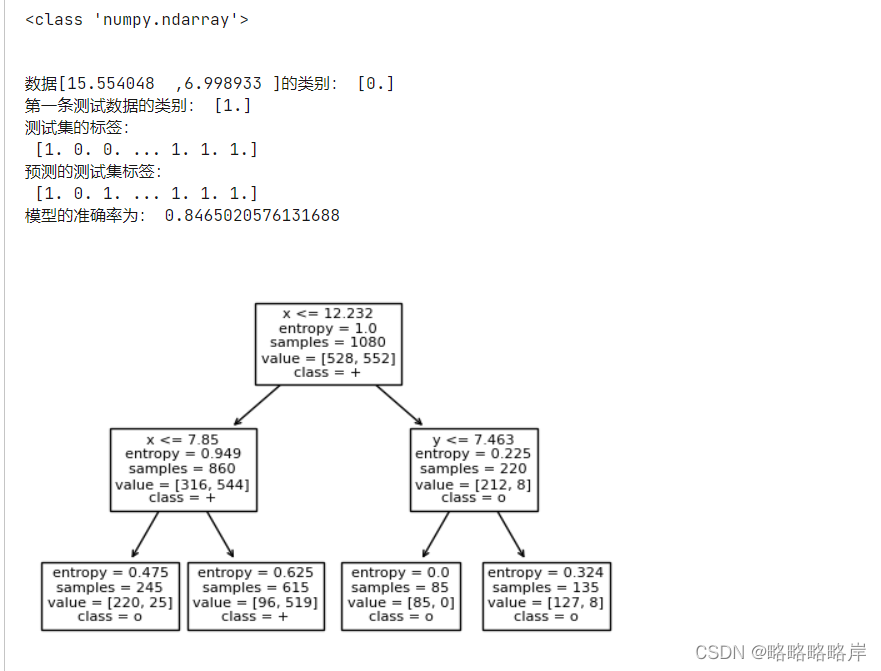
10%训练,90%测试创建决策树
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
X=data[['x','y']].values#将DataFrame的特定列x,y转换为ndarray
y=data['labels'].values
X_train, X_test, Y_train, Y_test = train_test_split(X,y,test_size=0.9,random_state=0,shuffle=True)
print(type(X_test))
clf = DecisionTreeClassifier(criterion='entropy', max_depth=2)#创建决策树模型,criterion属性缺省为‘gini'
clf.fit(X_train, Y_train) #拟合模型
plt.figure(dpi=100)
feature_names=['x','y']
target_names=['o','+']
tree.plot_tree(clf,feature_names=feature_names,class_names=target_names) #feature_names属性设置决策树中显示的特征名称
plt.show()
# Predict for 1 observation
print('数据[15.554048 ,6.998933 ]的类别:',clf.predict([[15.554048 ,6.998933 ]]))
print('第一条测试数据的类别:',clf.predict(X_test[0].reshape(1,-1)))
# Predict for multiple observations
print('测试集的标签:\n',Y_test)
Y_pre=clf.predict(X_test)
print('预测的测试集标签:\n',Y_pre)
# The score method returns the accuracy of the model
#(正确预测的分数):正确预测/数据点总数
print('模型的准确率为:',clf.score(X_test,Y_test))
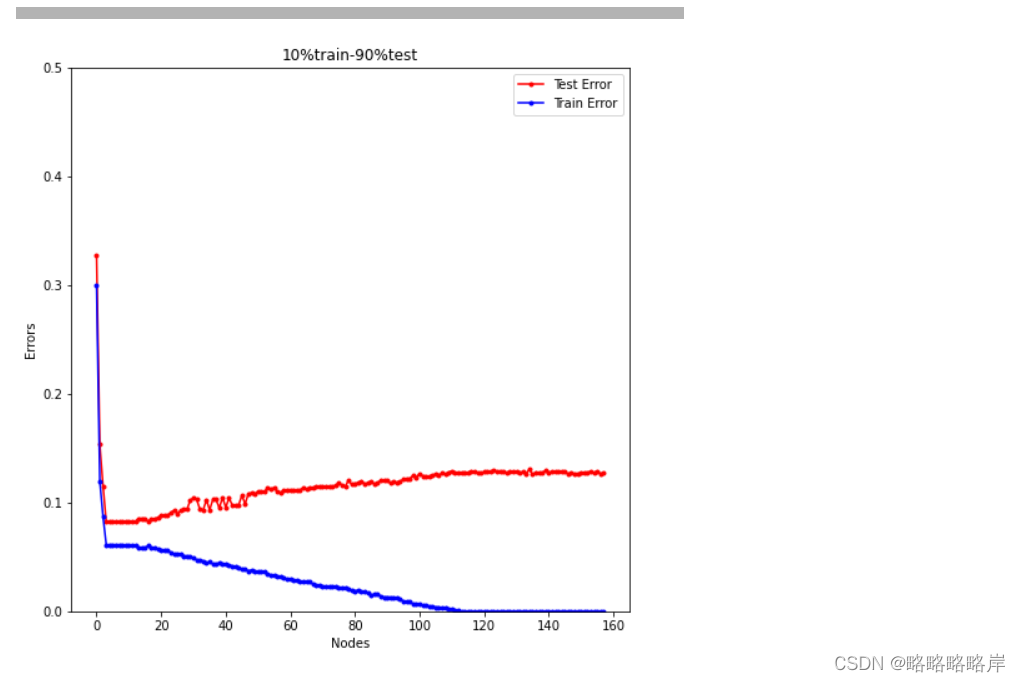
10%的数据进行训练,剩余90%用于测试时树的大小(叶结点数)从1到150进行变化时,训练误差和测试误差的变化情况
scores_test = []
scores_train=[]
for i in range(2,160) :#限制最大叶子节点数
##### 训练模型
dtcf = DecisionTreeClassifier( criterion='entropy', max_leaf_nodes=i)
# criterion 选entropy---信息熵
dtcf.fit(X_train, Y_train)
#获取训练误差
score_test = dtcf.score(X_test, Y_test)
score_train = dtcf.score(X_train, Y_train)
scores_test.append(1-score_test)
scores_train.append(1-score_train)
plt.figure(figsize=(8,8))
#绘制折线图
plt.plot(range(158), scores_test,'-o',MarkerSize=3,color='red',label='Test Error')#修改符号大小粗细
plt.plot(range(158), scores_train,'-o',MarkerSize=3,color='blue',label='Train Error')#修改符号大小粗细
plt.xlabel('Nodes')
plt.ylabel('Errors')
plt.title('10%train-90%test')
plt.ylim([0,0.5])#设置了x,y轴的范围
#plt.xlim([0,160])
plt.legend()
plt.show()
#print(scores)
20%训练的数据时,训练误差和测试误差的变化情况
scores_test_ex = []
scores_train_ex=[]
for i in range(2,160) :#限制最大叶子节点数
##### 训练模型
dtcf_ex = DecisionTreeClassifier( criterion='entropy', max_leaf_nodes=i)
# criterion 选entropy---信息熵
dtcf_ex.fit(X_train_ex, Y_train_ex)
#获取训练误差
score_test_ex = dtcf_ex.score(X_test_ex, Y_test_ex)
score_train_ex = dtcf_ex.score(X_train_ex, Y_train_ex)
scores_test_ex.append(1-score_test_ex)#1-准确率获得误差
scores_train_ex.append(1-score_train_ex)
plt.figure(figsize=(8,8))
#绘制折线图
plt.plot(range(158), scores_test_ex,'-o',MarkerSize=3,color='red',label='Test Error')#修改符号大小粗细
plt.plot(range(158), scores_train_ex,'-o',MarkerSize=3,color='blue',label='Train Error')#修改符号大小粗细
plt.xlabel('Nodes')
plt.ylabel('Errors')
plt.title('20%train-80%test')
plt.ylim([0,0.5])#设置了x,y轴的范围
#plt.xlim([0,160])
plt.legend()
plt.show()
#print(scores)
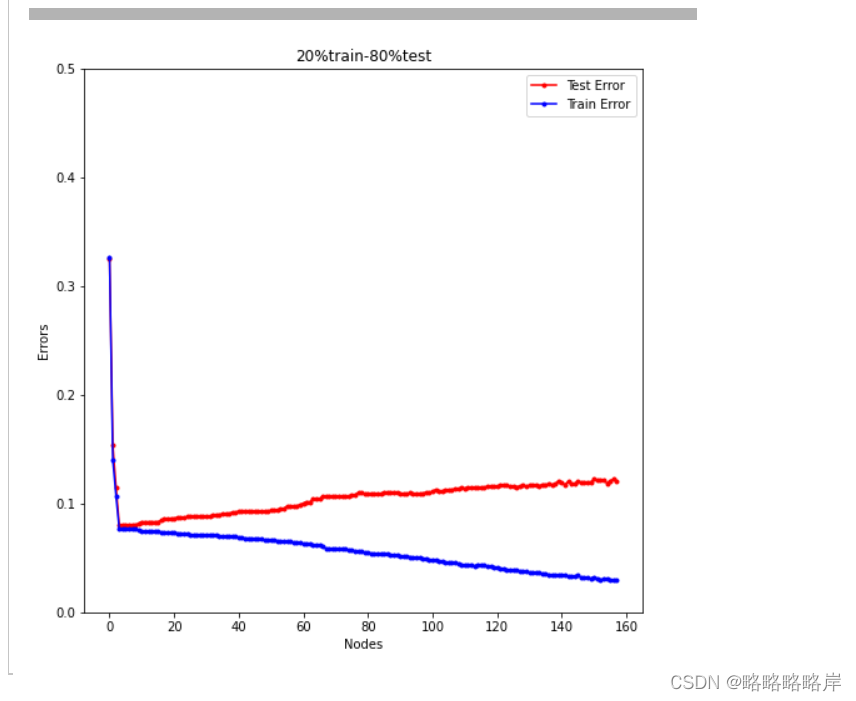
总结:
在最优的nodes时训练误差和测试误差之间的差距,第一个误差图会比第二个误差图差距更大














 6108
6108











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









