






距上次发博客以及是很久以前的事情了,博主自己也因总是偷懒找借口没写博客而感到愧疚(QAQ),今天开始,一定要努力学习(•̀ᴗ•́)و ̑̑。
这篇文章主要是博主在学习的过程中发现有很多陌生的评估指标,于是打算写一篇博客,梳理一下深度学习中常用的一些训练参数和评估指标和相应的原理,希望能帮助大家更好地理解和应用深度学习技术。
文章目录
(5)ROC 曲线(Receiver Operating Characteristic Curve)
(6)AUC 值(Area Under the Curve)
(3)dfl_loss(Distribution Focal Loss 损失)
一、通用参数(超参数)
超参数一般在训练前手动设置的变量,用于控制训练过程和模型结构,不同的超参数取值可能会导致模型在准确性、泛化能力、训练速度等方面产生一些差异。以下是一些常用的超参数:
(1)学习率(Learning Rate)
学习率用于控制反向传播中参数更新的步长,控制损失函数梯度下降的速度,具体来说,梯度下降是一种常用的优化算法,它通过计算损失函数关于模型参数的梯度,来确定参数更新的方向和幅度。假设存在一个模型中的参数 ,损失函数为
,在每次的迭代中,参数的更新公式为:
其中为当前迭代的参数值,
是损失函数在当前参数值下的梯度,
就是学习率,那么由上式中可以看出学习率
决定了在梯度方向上参数更新的步长。如果学习率过大,模型可能会跳过最优解,导致损失函数无法收敛甚至发散;如果学习率过小,模型的收敛速度会非常缓慢。
通常我们一般默认学习率0.01 ~0.001比较合适,此为固定学习率的方法,我们也可以在一些情况下(如模型初期损失下降快但后期难以收敛)使用衰减学习率的方法,也就是随着训练的进行,逐渐降低学习率。例如,其中
为第t次迭代时的学习率,
为初始学习率,
为衰减系数。
(2)批次大小 (Batch Size)
在训练模型时,需要计算损失函数关于模型参数的梯度来更新参数。批次大小决定了每次计算梯度时所使用的样本数量。假设训练集中共包含N个样本,批次大小为B,则每次迭代计算梯度时,会从数据集中选取B个样本组成一个批次,计算这B个样本的平均损失函数关于参数的梯度。
较大的批次大小可以利用硬件的并行计算能力,一次处理更多的样本,减少迭代次数,从而在一定程度上缩短训练时间。较大的批次大小可以使梯度估计更加稳定,因为它综合了更多样本的信息。根据大数定律,样本数量越多,梯度估计越接近真实的梯度方向,模型更新更稳定,更有可能朝着最优解的方向收敛。
但同时较大的批次大小可能会使模型过于适应训练数据,导致过拟合。相应的较小的批次大小可以让模型在训练过程中更频繁地接触到不同的样本组合,更好地捕捉数据的多样性,有助于提高模型的泛化能力。所以我们要根据训练集大小、模型结构、模型训练情况以及各种因素来综合考量批次大小的选取。
选择批大小作为 2 的幂或 8 的倍数,一般来说我们可以根据自己设备的性能以及根据数据集的大小和类型进行选择,一般可以选择内存大小的1~4倍作为批处理大小的上限。
(3)迭代次数(epochs)
迭代次数决定了模型在整个训练数据集上进行训练的轮数。在每次迭代中,模型根据当前的参数计算损失函数对参数的梯度,然后沿着梯度的反方向更新参数,以减小损失函数的值。每一次遍历,模型都会根据数据集中的所有样本计算一次梯度并更新参数。随着迭代次数的增加,模型逐渐学习到数据中的模式和规律,参数不断调整,使得损失函数逐渐减小,以提高模型在对应数据集下任务的性能。
通常我们会根据任务类型的不同、模型的复杂程度以及数据集的大小去进行迭代次数的选择:
对于简单任务(如MNIST手写数据集),数据特征较为明显,一般迭代15-30次就可以学习到很多的特征以达到较好的准确率,对于复杂的任务(语言理解、多类复杂图像识别)可能需要50-100次以上的迭代次数才能取得较好的效果。
对于简单模型(线性回归,决策树)参数较少的模型,其本身的模型表达能力有限,训练相对比较容易收敛,一般迭代50次左右就能使损失函数收敛,而对于大型深度神经网络,例如ResNet50 这样的深度卷积神经网络,通常需要100次以上的迭代次数。
对于小数据集(几百到几千个样本),模型能够较快的学习到数据中的信息,通常只需要20到50次迭代就可以,而对于大数据集,往往需要模型通过更多的迭代次数和时间去充分学习数据中的特征,可能达到100-300甚至更多的迭代次数。
二、常用评价指标
2.1分类任务
在具体介绍之前我们要先了解一些基础概念,先了解一下二分类问题下的根据模型预测结果和真实标签的组合,继而推广到多分类问题,对于二分类问题,可以将样本分为以下四类:
真正例(True Positive, TP):模型预测为正类,且真实标签也为正类的样本数量。
假正例(False Positive, FP):模型预测为正类,但真实标签为负类的样本数量。
真反例(True Negative, TN):模型预测为反类,且真实标签也为反类的样本数量。
假反例(False Negative, FN):模型预测为反类,但真实标签为正类的样本数量。
tip:是不是很绕很难记╮(╯▽╰)╭,我们可以直接看第二个字母,P就是预测为正的样本,N就是预测为反的样本,然后再看前面的字母若是T说明实际情况和预测吻合,F就是不吻合,比如FP,就是预测为对,但实际上是错,这样就好记住了(~ ̄▽ ̄)~
(1)准确率 (Accuracy)
准确率表示正确预测数(TP与TN)占全部样本数的比例。它是最直观的评价指标之一,能反映模型整体的预测能力。但在类别不平衡的情况下,准确率可能会给出误导性的结果。例如,在一个疾病诊断任务中,健康样本占比 99%,疾病样本占比 1%,即使模型将所有样本都预测为健康,准确率也能达到 99%,但实际上模型对疾病样本的预测能力为零。
(2)精确率 (precision)
精确率也称为查准率,是指模型预测为正类的样本中,真正为正类的样本比例,精确率关注的是模型预测为正类的结果中有多少是正确的。在一些对误判正类有较高成本的场景中,如垃圾邮件分类,精确率尤为重要,因为将正常邮件误判为垃圾邮件会给用户带来较大的困扰。
(3)召回率(Recall)
召回率也称为查全率,是指真实正类样本中,被模型正确预测为正类的样本比例。召回率衡量了模型找到所有正类样本的能力。在一些需要尽可能找到所有正类样本的场景中,如疾病筛查,召回率非常关键,因为漏诊一个患病患者可能会导致严重的后果。
(4)F1 值(F1 - Score)
F1 值是精确率和召回率的调和平均数,F1 值综合考虑了精确率和召回率,当精确率和召回率都较高时,F1 值也会较高。它在需要同时平衡精确率和召回率的场景中非常有用,能够更全面地评价模型的性能。
(5)ROC 曲线(Receiver Operating Characteristic Curve)
ROC 曲线是以假正例率(False Positive Rate, FPR)为横轴,真正例率(True Positive Rate, TPR)为纵轴绘制的曲线。其中,假正例率的计算公式为:
真正例为召回率:
这里可能比较绕,但是大家只要记住:一个好的模型的 ROC 曲线应该尽可能靠近左上角,即假正例率低,真正例率高。例图如下:
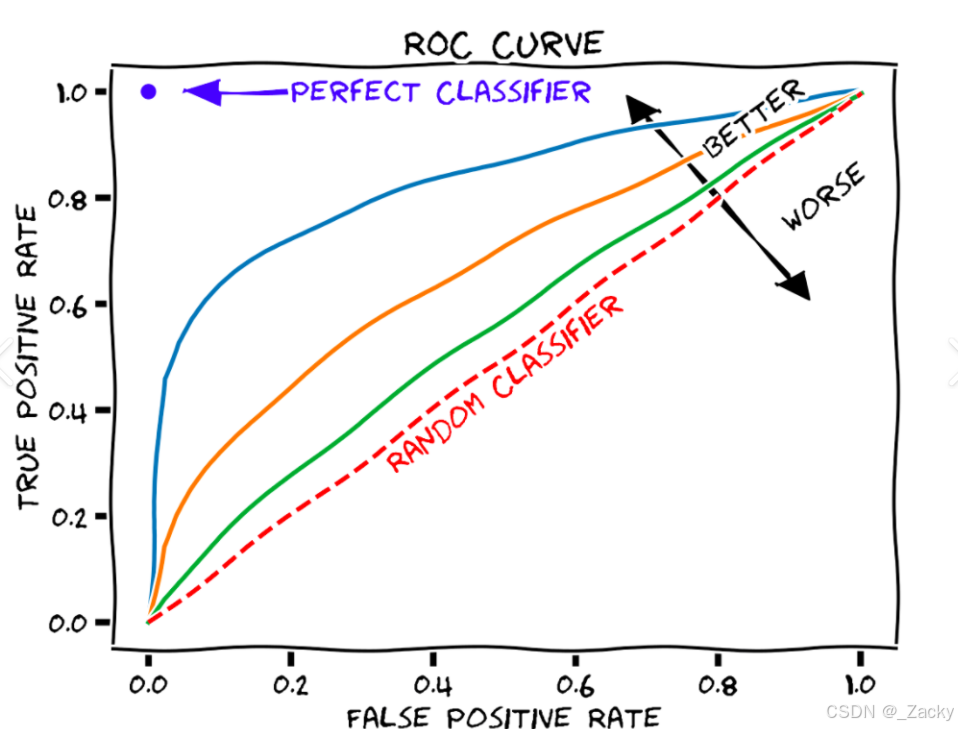
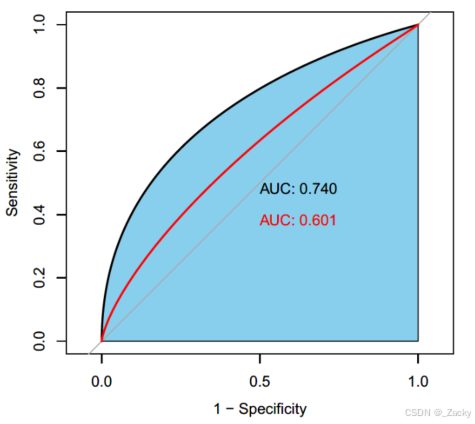
(6)AUC 值(Area Under the Curve)
AUC 值是 ROC 曲线下的面积,取值范围在 0 到 1 之间,AUC 值可以作为一个综合的评价指标,用于衡量模型的整体性能。AUC 值越接近 1,表示模型的性能越好;当 AUC 值为 0.5 时,模型的表现相当于随机猜测。AUC 值不受类别不平衡的影响,因此在处理不平衡数据集时非常有用。
2.2回归任务
(1)均方误差 (MSE)
其中n是样本数量,是第i个样本的真实值,
是模型对第i个样本的预测值。均方误差计算的是预测值与真实值之间差值的平方的平均值。由于对误差进行了平方运算,所以 MSE 对异常值十分敏感。在实际应用中,比如在预测股票价格走势时,如果某一天股票价格因为突发的重大事件而出现异常波动,那么这个样本的误差在 MSE 的计算中会被显著放大,进而对整体的评估结果产生较大影响
(2)平均绝对误差 (MAE)
MAE 计算的是预测值与真实值差值的绝对值的平均值,这使得它对异常值具有较好的鲁棒性。在一些需要平稳评估预测效果的场景中表现出色,例如在预测商品销量时,即使偶尔出现个别特殊促销活动导致销量异常,MAE 也不会像 MSE 那样被大幅度影响,能够更稳定地反映模型预测误差的平均水平 。
2.3其他任务
(1)IoU (目标检测 / 分割)
预测区域与真实区域的交集面积 / 预测区域与真实区域的并集面积
IoU(Intersection over Union)即交并比,是目标检测和图像分割任务中常用的评价指标。它通过计算预测区域(如目标检测中的预测框、图像分割中的预测掩码)与真实区域(真实标注的目标框或掩码)之间的交集面积与并集面积的比值,来衡量两者的重合程度。
(2)mAP (目标检测)
mAP(Mean Average Precision)是目标检测中用于综合评估模型在多个类别上检测性能的指标。它基于每个类别的精度 - 召回率(Precision-Recall)曲线。
对于每个类别,通过改变检测阈值(如分类器的置信度阈值),可以得到一系列的精度和召回率值,从而绘制出精度 - 召回率曲线。该曲线下的面积就是该类别的平均精度(Average Precision,AP)。mAP 则是对所有类别的 AP 值求平均,得到的平均值。
我们一般会看到 mAP(平均精度均值)出现 0.5 和 0.9 这样的取值,一般写成 mAP@0.5 和 mAP@0.9 或 mAP@0.5:0.95 等形式,这主要与评估时所采用的交并比(IoU)阈值有关。
例如mAP@0.5表示在计算 mAP 时,以 0.5 作为 IoU 的阈值来判断检测结果是否正确。即只有当预测框与真实框的 IoU 大于等于 0.5 时,才认为该检测是一个正确的预测,否则视为错误预测。而mAP@0.9是指以 0.9 作为 IoU 阈值来计算 mAP。意味着预测框与真实框需要有更高的重合度才能被认定为正确检测,对检测的准确性要求更高。
三、各类损失值
(1)box_loss(边界框损失)
衡量模型预测的边界框和真实边界框之间的差异。在目标检测里,准确预测边界框很重要,常用特定损失函数计算,像 GIoU Loss、CIoU Loss 等。其中:
- GIoU Loss:在 IoU(交并比)基础上,考虑了两个框非重叠部分,能更好反映框间相对位置。
- CIoU Loss:进一步考虑了框中心点距离和长宽比一致性,使模型收敛更快、定位更准。
体现模型定位目标的能力。损失值越小,模型预测的边界框越接近真实框,定位精度越高。训练时,该损失应随训练轮次增加而减小。
(2)cls_loss(分类损失)
衡量模型对目标类别预测的准确性。常用交叉熵损失函数,分二分类和多分类交叉熵损失。其中:
- 二分类交叉熵损失:用于二分类问题,根据模型预测概率和真实标签计算损失。
- 多分类交叉熵损失:用于多分类问题,促使模型输出概率接近真实类别分布。
反映模型的分类表现。损失值越小,模型对目标类别的预测越准确。训练中,此损失应随训练轮次下降。
(3)dfl_loss(Distribution Focal Loss 损失)
dfl损失是一种用于目标检测的损失函数,主要用于优化模型对边界框位置分布的预测。传统的边界框回归方法通常假设边界框的位置是一个确定的值,但在实际情况中,边界框的位置存在一定的不确定性。DFL 关注的就是这种边界框位置的不确定性建模。
四、其他参数(简单介绍)
(1)CNN(卷积神经网络)
-
卷积核尺寸 (Kernel Size):如3×3,决定感受野大小。
-
滤波器数量 (Filters):控制输出通道数,影响特征丰富度。
-
步长 (Stride):滑动步长,影响输出尺寸(如步长2使尺寸减半)。
-
填充 (Padding):保持输入输出尺寸一致(如“same”填充)。
(2)Transformer
-
头数 (Num Heads):多头注意力机制的头数,并行捕捉不同特征。
-
层数 (Num Layers):堆叠的Encoder/Decoder层数,增加模型深度。
-
注意力维度 (d_model):输入向量维度,需与嵌入维度一致。
(3)BERT等预训练模型
-
层数 (Num Layers):Transformer层数(如BERT-base为12层)。
-
注意力头数 (Num Attention Heads):每层的头数(如BERT-base为12头)。
-
隐藏层维度 (Hidden Size):前馈网络维度(如BERT-base为768)。
以上就是本文的全部内容,本篇文章仅对一些常见的指标和参数进行了简单介绍,可能会有一些遗漏,如果各位读者有感兴趣或者疑问的地方都可以一起讨论,那就这样,下期见(^o^)/

















 32万+
32万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









