







互联网大数据框架介绍(一)Hadoop,HDFS,yarn,Mapreduce
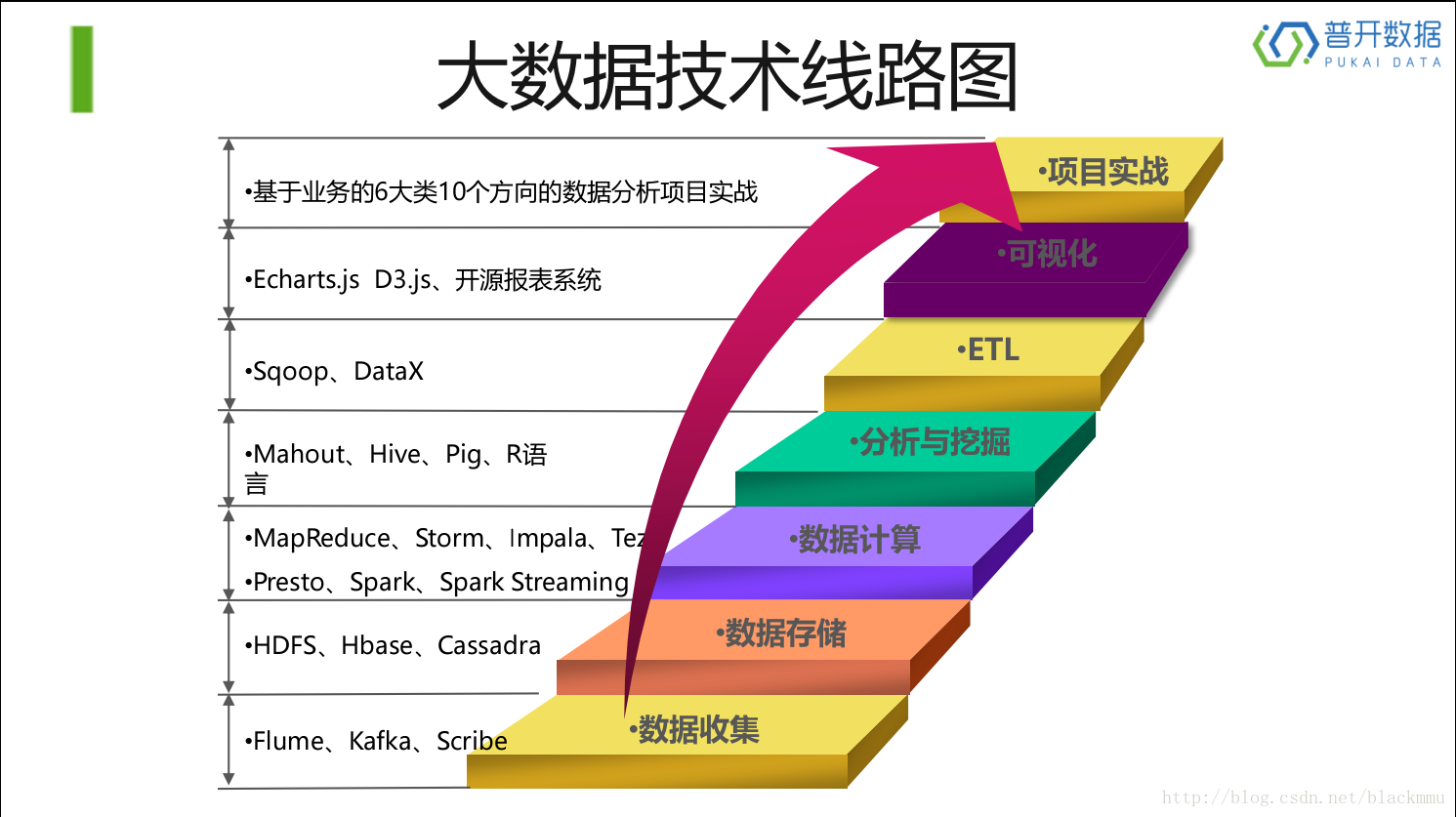
如下图,这是现在流行的大数据技术线路图,也是最近才学习大数据的课程,所以对以下几个方面,hadoop,HDFS,yarn,Hbase,Mapreduce,Spark,Spark Streaming,Hive,Sqoop,这几个方面从数据存储到ETL这些核心部分进行介绍,。
第一部分:hadoop
首先,什么是hadoop:
Hadoop是Apache开源软件基金会开发的运行于大规模普通服务器上的大数据存储、计算、分析的分布式存储系统和分布式运算框架。
hadoop的优点

现在主要使用的是Hadoop2.0,它由以下三个部分组成:
1)分布式文件系统HDFS资源分配系统
2)Yarn分布式运算框架
3)MapReduce。
所以接下来对这三个部分进行介绍:
HDFS
HDFS(hadoop distribute file system),也就是基于hadoop的分布式文件系统,HDFS只是存储文件的地方,区别于数据库,在这点上又是总的会搞混。
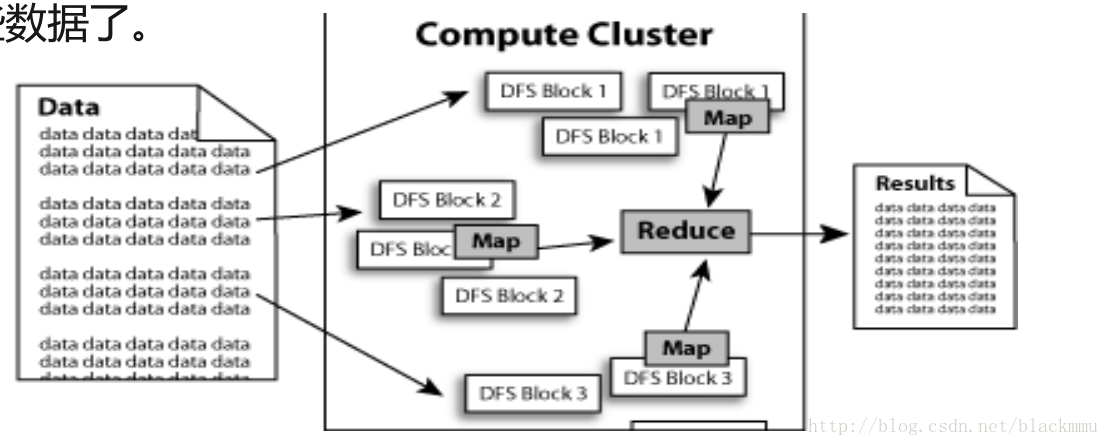
如下图所示,HDFS为了做到可靠性(reliability)创建了多份数据块(data blocks)的复制(replicas),并将它们放置在服务器群的计算节点中(compute nodes),MapReduce就可以在它们所在的节点上处理这些数据了。这里提一下mapreduce,后续会介绍。
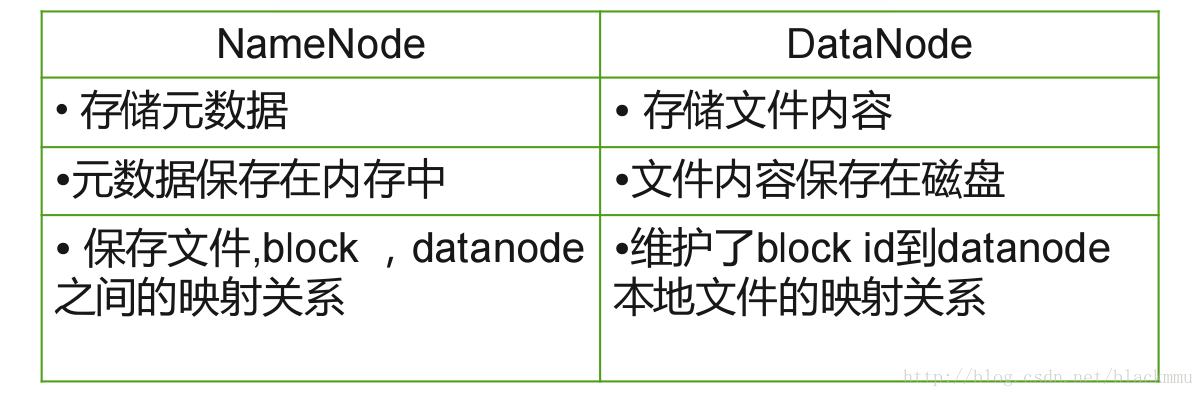
在HDFS中存储结构分两个部分,并且文件存储时被切分成块(默认大小128M),以块为单位,每个块有多个副本存储在不同的机器上,副本数可在文件生成时指定(默认3), NameNode是主节点,存储文件的元数据如文件名,文件目录结构,文件属性(生成时间,副本数,文件权限),以及每个文件的块列表以及块所在的DataNode等等。DataNode在本地文件系统存储文件块数据,在一个集群中,namenode通常只有一台,客户端(Client)在写数据的时候只写一份,复制(replication)的过程由HDFS来完成。这里的node相当于一台机器。
以下描述图为HDFS的基本架构图:
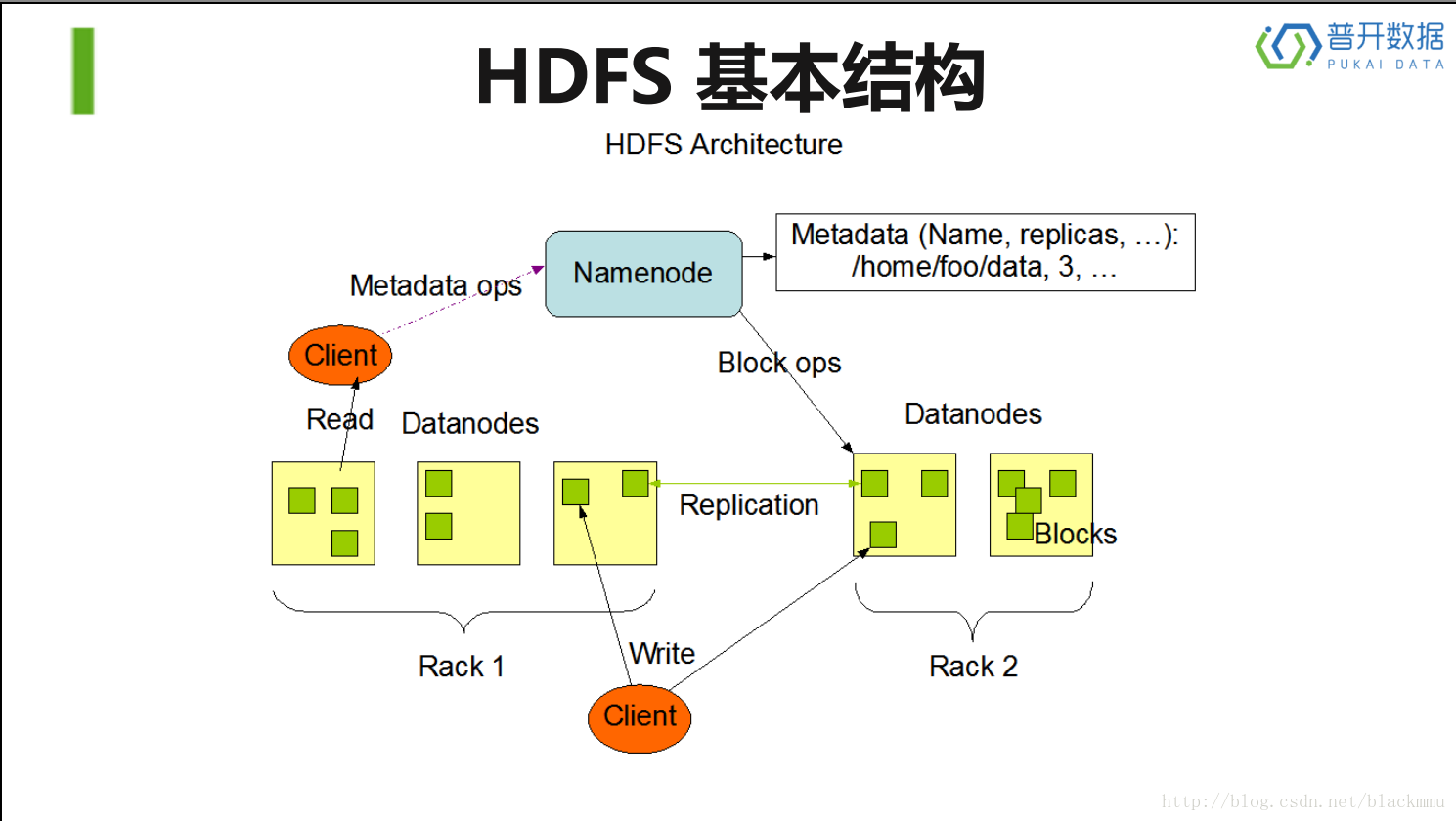
写过程:
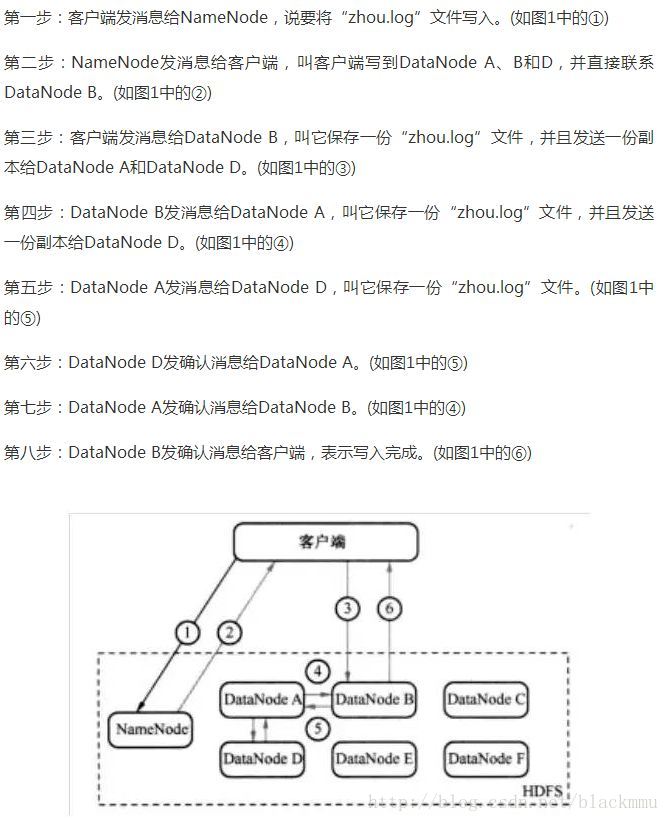
读过程:
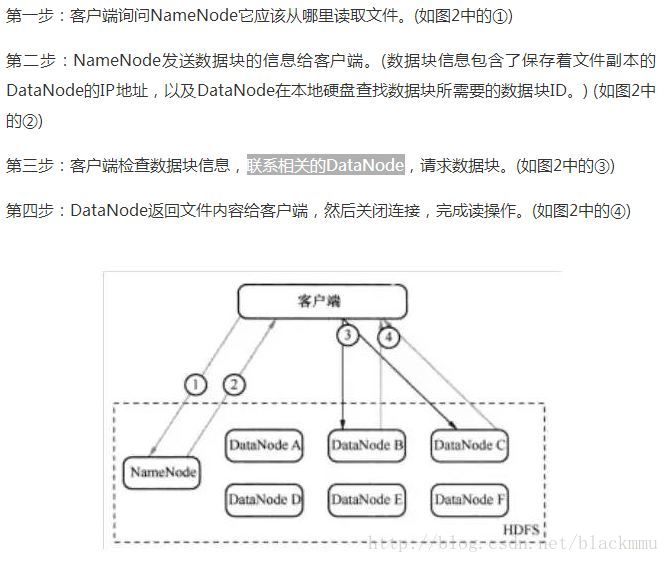
那么HDFS适合做什么呢:
1)存储并管理PB级数据
2)处理非结构化数据
3)注重数据处理的吞吐量(latency不敏感)
4)应用模式为:write-once-read-many存取模式
不适合做什么呢:
1)存储小文件 (不建议使用)(因为这样会建立很多的datanode,是的源数据信息过于庞大)
2)大量的随机读 (不建议使用)(HDFS一个数据块的大小为128M,且数据存于磁盘中,随机读会很慢)
3)需要对文件的修改 (不支持)(数据存到HDFS上之后不允许修改,需要从HDFS上取下来修改完再上传)
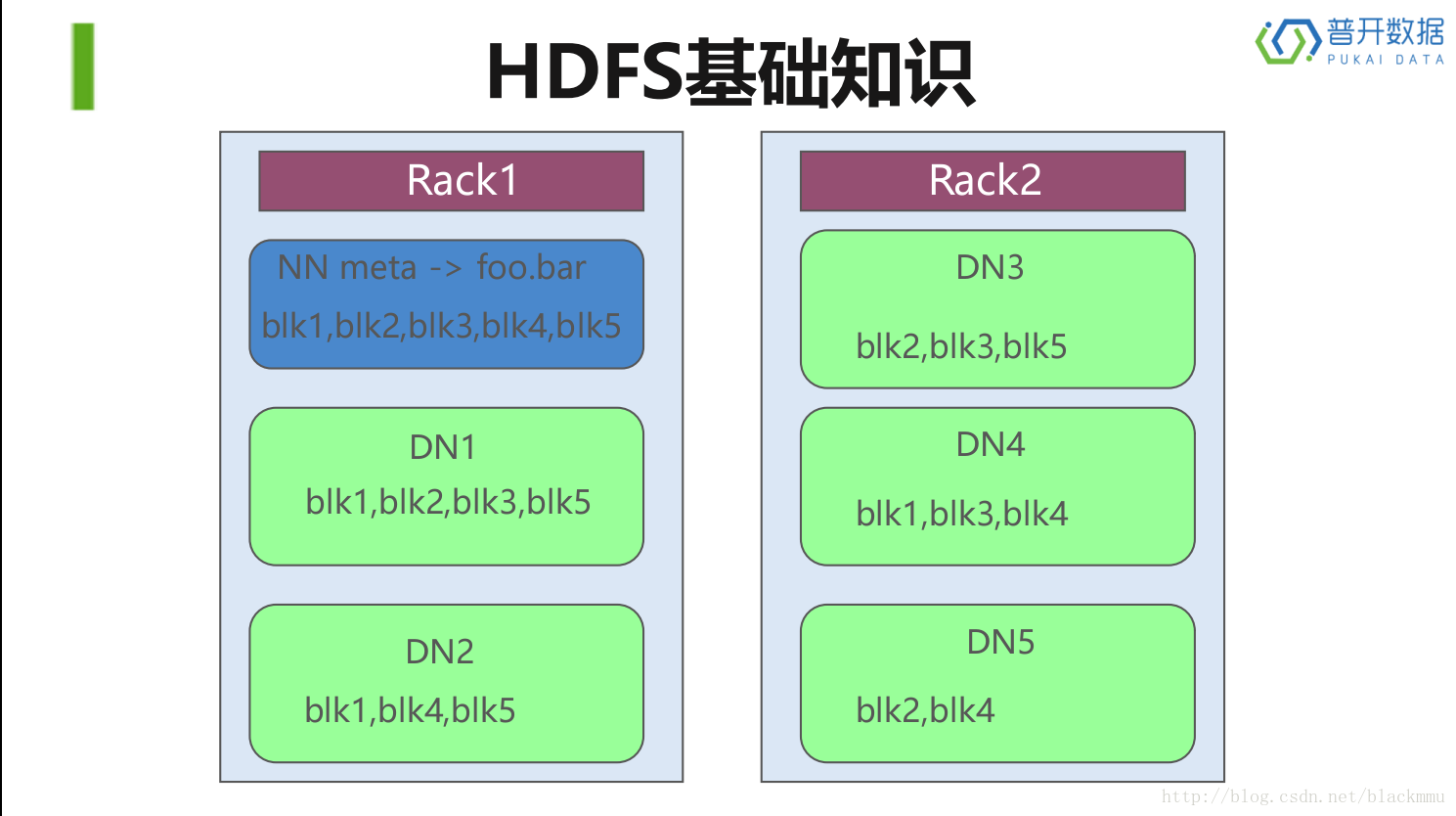
上图描述的是HDFS的的存储方式,rack是一个机柜,可以看到NN(namenode)只有一台,其他的都为DN(datanode),这个例子的复制数量是每个数据块(blk)复制三份,你可以看到,在绿的的块中,每个blk类别都出现了3次。至于blk的分配这是HDFS来自动分配的。启动DN线程的时候会向NN汇报block信息,通过向NN发送心跳保持与其联系(3秒一次),如果NN 10分钟没有收到DN的心跳,则认为其已经lost,就复制上面的blk块信息,到其他的datanode上找这些块。
这里再简单介绍以下HA(High Availability),上述说明了当datanode不好使的时候,我们因为复制了副本,所以可以找寻其他副本将丢失的block数据不全,那么如果namenode丢失了该怎么办,方法也是一样的,就是在同时建立一台备用的namenode节点,用着的节点叫做active namenode,备份为standby namenode,两个节点定期同步,已达到如果一台挂掉,另一台可以马上补上的效果。
yarn
YARN 是Hadoop 2.0 中的资源管理系统,它是一个通用的资源管理模块,可
为各类应用程序进行资源管理和调度。
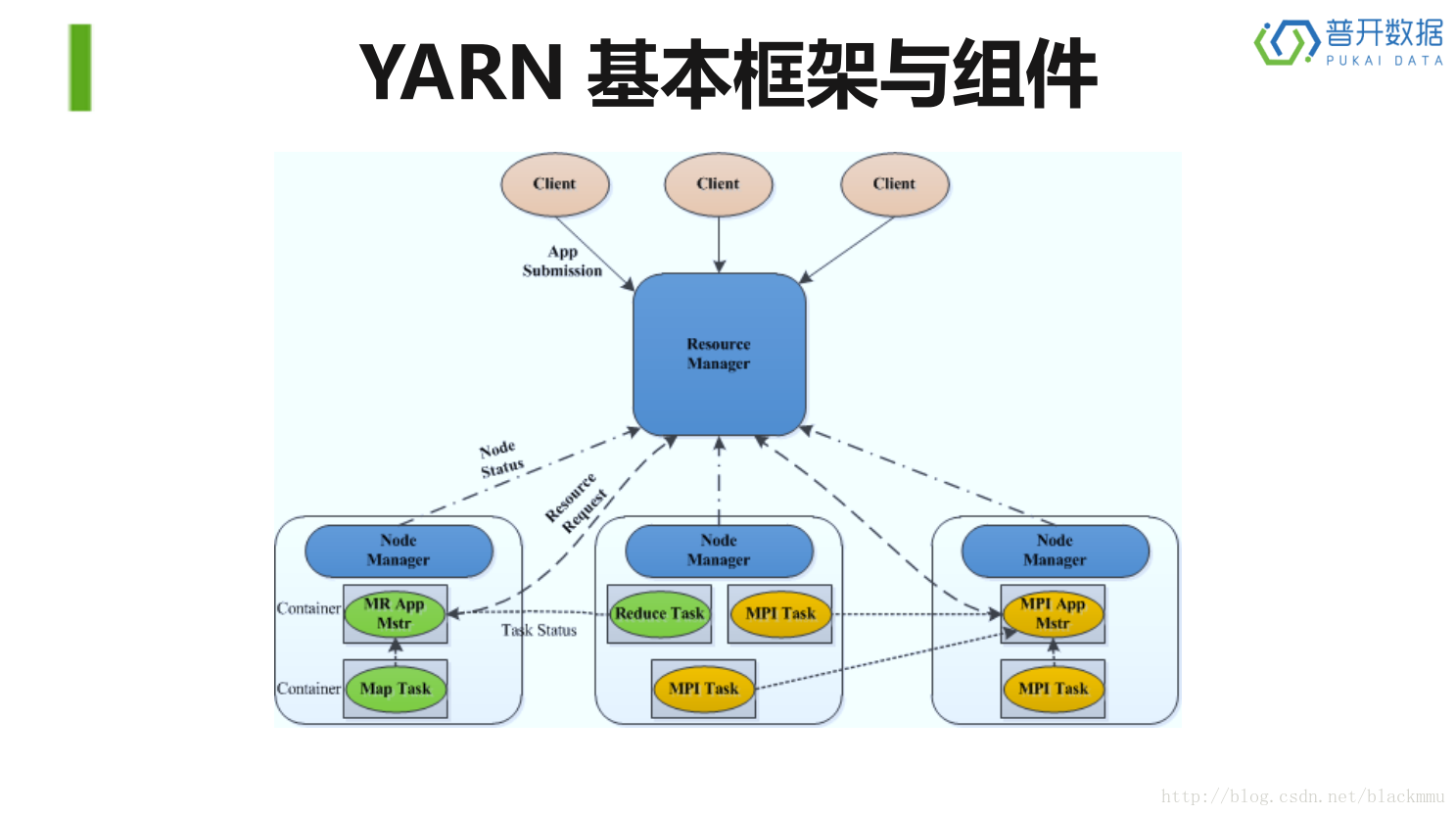
主要部分包括:ResourceManager 、NodeManager、ApplicationMaster,以及各个task。具体步骤可以分为:1,Client向RM发起命令。2,RM将任务传给NM,并让NM在启动一个appmaster。3,appmaster向RM进行注册并申请和领取资源。4,appmaster与NM进行通信,告诉其执行任务。5,各个task通过某种协议向appmaster汇报进度。6,待所有的task完成任务后,appmaster向RM申请注销关闭自己。这里的所有task在Centos7上都是以yarnchild的命名形式表示,不具体区分。
MapReduce
MapReduce的这个架构如下图所示,之所以选择这种方式,是因为寻址时间的提高速庙远远慢于传输速率的提高速度。
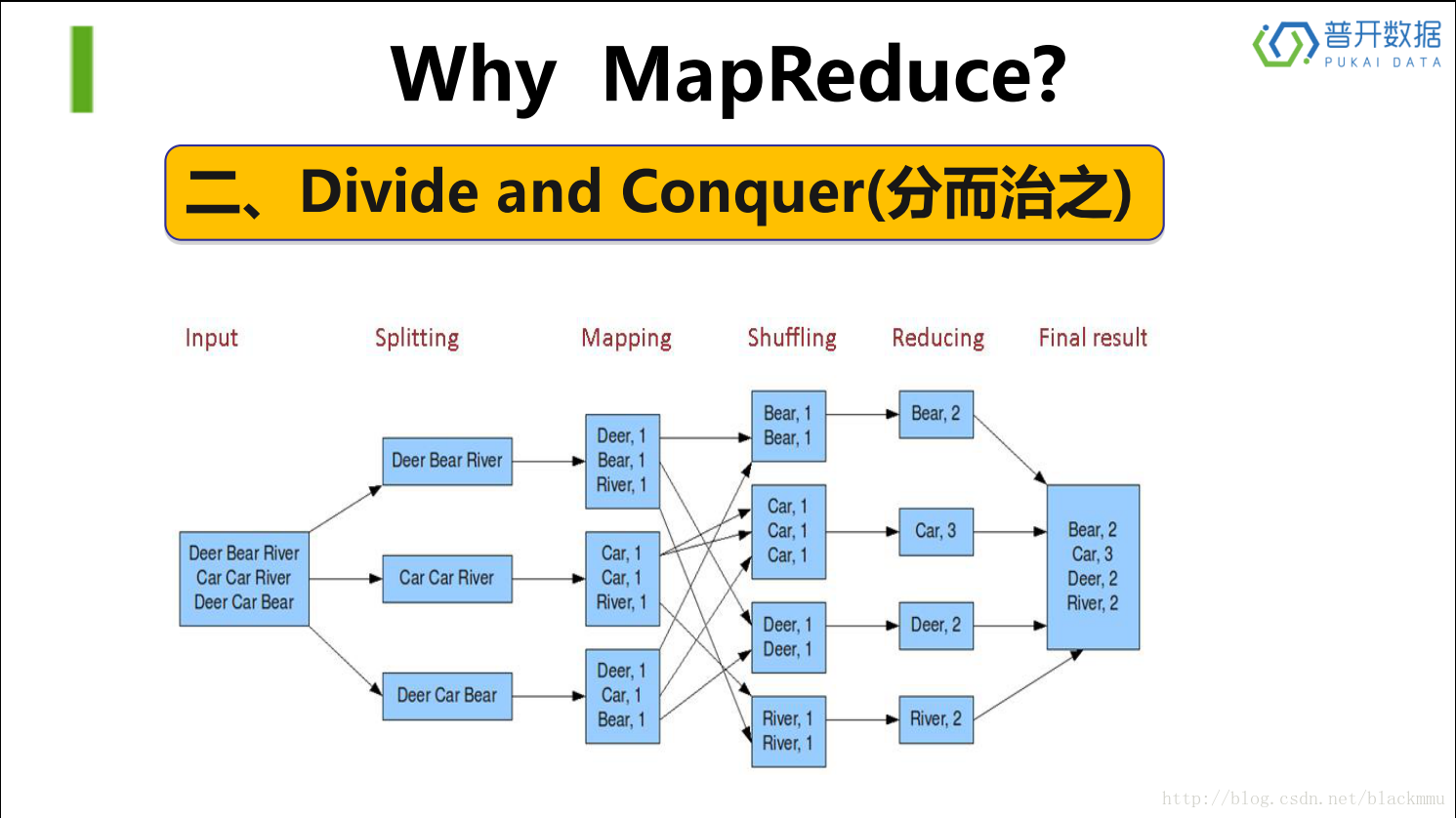
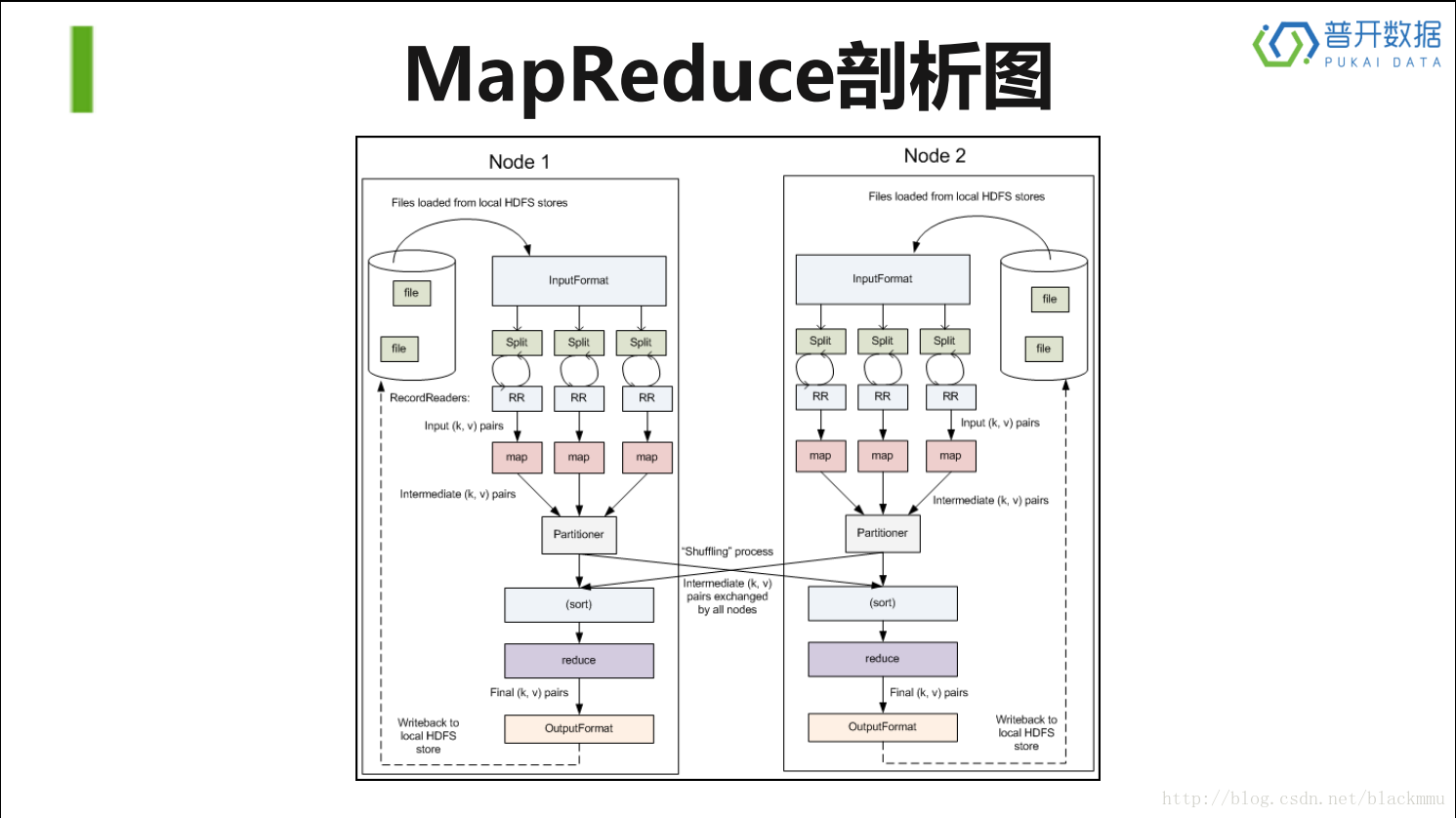
从上面两张图片可以清晰的看出MapReduce的计算框架,以及他和HDFS的联系。
在Splitting这一步上,首先将HDFS上取下来的数据进行分成很多的block,接着在Mapping步骤上对所有block上的数据进行遍历输出,采用(key,value)的形式(这个步骤是在RR(record reader)上实现的),接着在Shuffing步骤上进行各个node上的通信,将(key,value)这种类型的数据,key值相同的放在一起,之后在Reducing步骤上进行聚合,最后输出。这个shuffing步骤包括partition和sort两个小步骤,partition过程将mapping后的数据,按照key值进行分割,接着进行个node之间的通信,这里的sort相当于一个排序的过程。
MapReduce的过程基本都运行在yarn的框架下,所以下图是MapReduce,以下简称MR,运行在yarn上的全部过程。
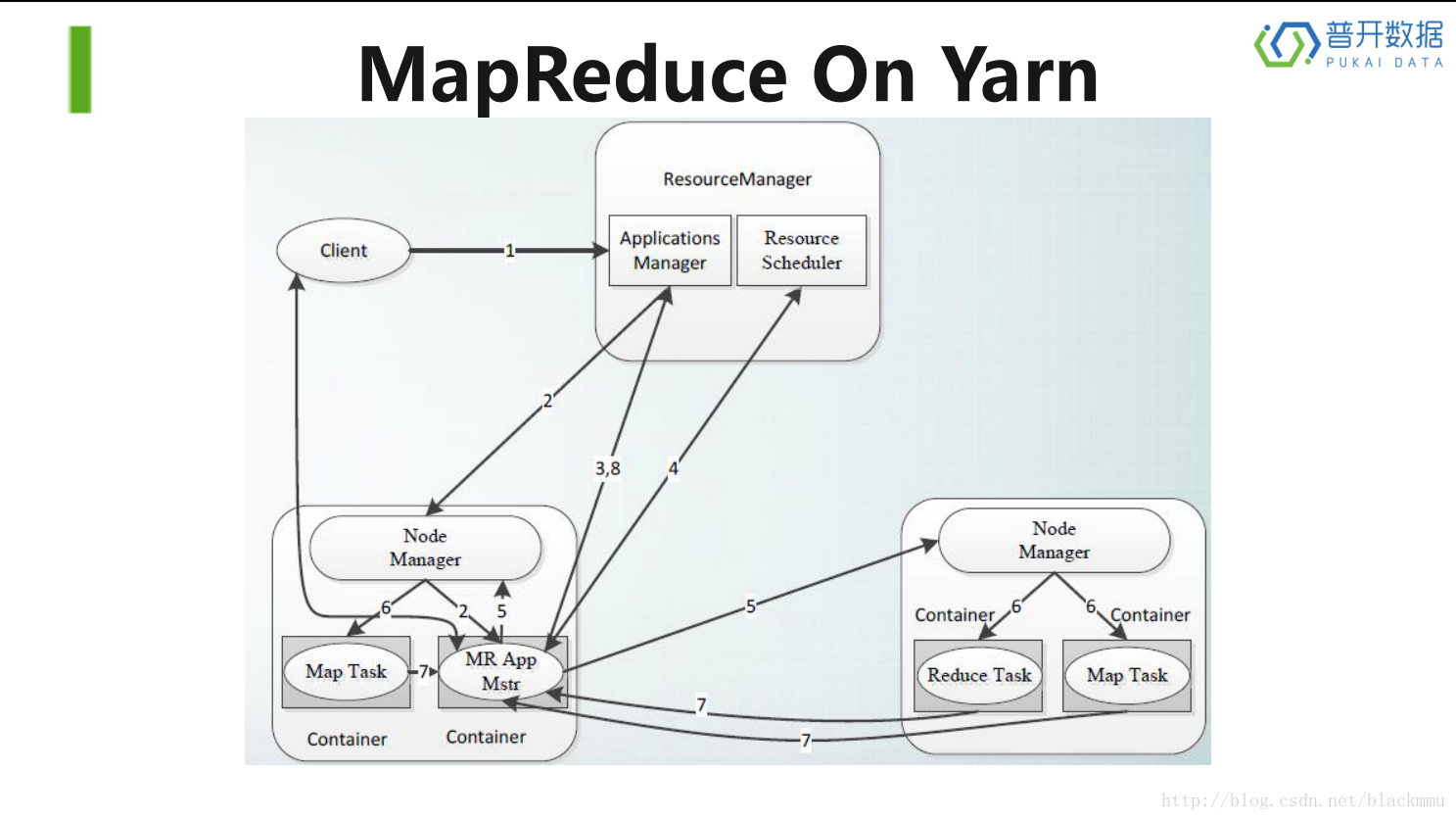
连线上的数字代表步骤顺序:
1)Client向RM发送命令
2)RM将任务传给其中一个node节点上的NM上,并要求NM启动一个MR appmaster
3)MR appmaster向RM的Applications Manager申请资源
4)采用轮询的方式向Resource Scheduler领取资源
5)MR appmaster与各个node上的NM进行通信,命令其执行任务
6)NM收到MR appmaster的命令开始执行任务
7)各个task定期的向MR appmaster汇报状态和进度,并在结束任务后向MR appmaster申请注销关闭自己
8)MR appmaster在执行完毕后,向RM申请注销关闭自己。
这就是MR的整个运行机制。
在下篇文章将继续介绍Hbase,Hive
附录这里附上一个Java写的单词个数统计的程序,从中可以看出基本的大步骤
WordCount v2.0
public class WordCount {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}














 531
531

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









