







Spark 基础及RDD基本操作
spark的优势
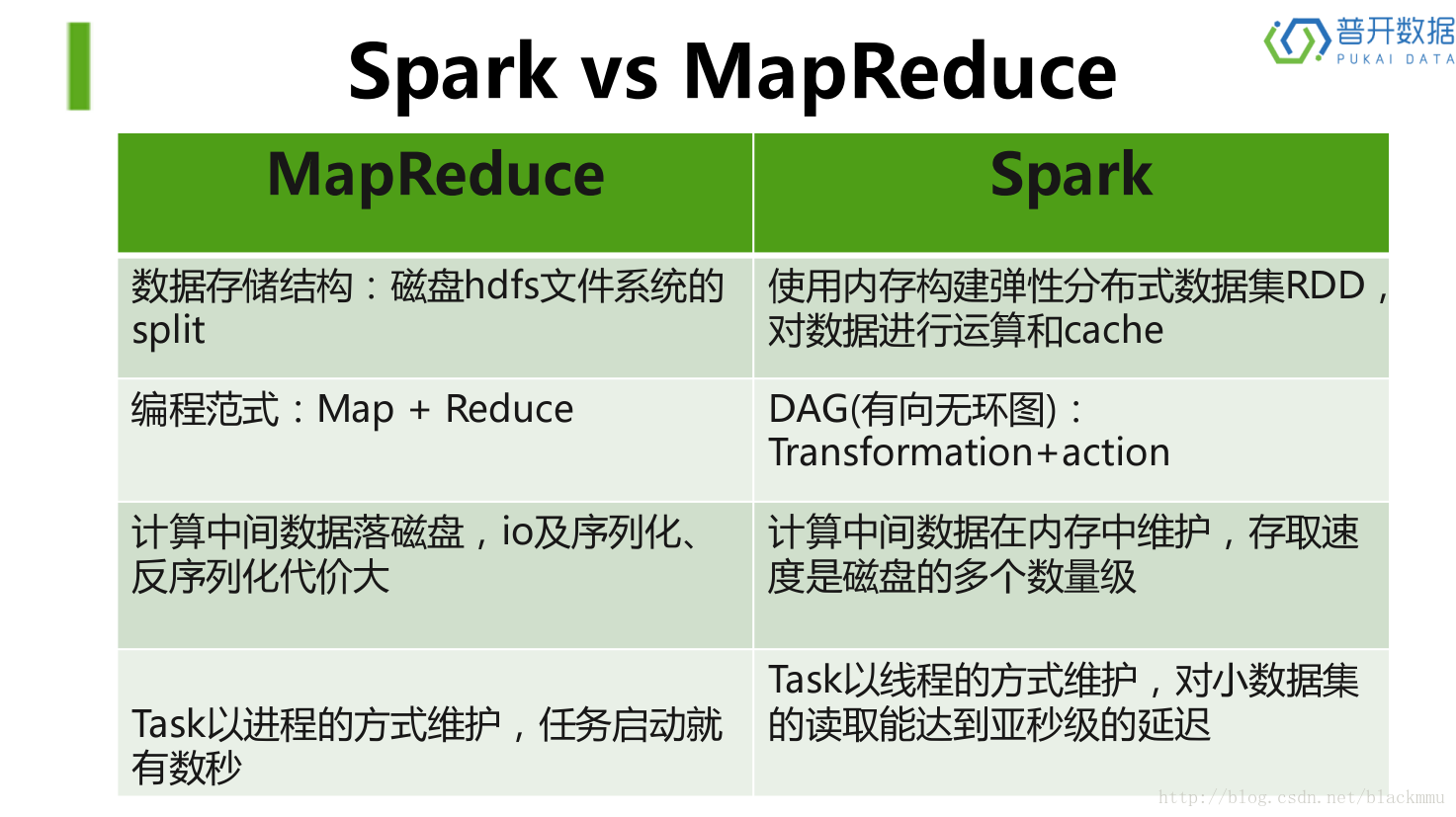
首先,Hadoop这项大数据处理技术大概已有十年历史,而且被看做是首选的大数据集合处理的解决方案。MapReduce是一路计算的优秀解决方案,不过对于需要多路计算和算法的用例来说,并非十分高效。数据处理流程中的每一步都需要一个Map阶段和一个Reduce阶段,而且如果要利用这一解决方案,需要将所有用例都转换成MapReduce模式。
在下一步开始之前,上一步的作业输出数据必须要存储到分布式文件系统中。因此,复制和磁盘存储会导致这种方式速度变慢。另外Hadoop解决方案中通常会包含难以安装和管理的集群。而且为了处理不同的大数据用例,还需要集成多种不同的工具(如用于机器学习的Mahout和流数据处理的Storm)。
而,Spark将中间结果保存在内存中而不是将其写入磁盘,当需要多次处理同一数据集时,这一点特别实用。Spark的设计初衷就是既可以在内存中又可以在磁盘上工作的执行引擎。当内存中的数据不适用时,Spark操作符就会执行外部操作。Spark可以用于处理大于集群内存容量总和的数据集。
什么是RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
基本RDD操作
RDD支持两种类型的操作:
1)变换(Transformation)
2)行动(Action)
变换:变换的返回值是一个新的RDD集合,而不是单个值。调用一个变换方法,不会有任何求值计算,它只获取一个RDD作为参数,然后返回一个新的RDD。
变换函数包括:map,filter,flatMap,groupByKey,reduceByKey,aggregateByKey,pipe和coalesce。
行动:行动操作计算并返回一个新的值。当在一个RDD对象上调用行动函数时,会在这一时刻计算全部的数据处理查询并返回结果值。
行动操作包括:reduce,collect,count,first,take,countByKey以及foreach。
具体的实际操作可以看这个链接,链接中明白的写出了关于RDD有向无环图的运行方法:http://blog.csdn.net/jiangwlee/article/details/50774561
创建RDD:
1)读取外部数据集
val file=sc.textFile(“hdfs://hadoop1:9000/input/word/word.txt”)
2)在驱动器程序中对一个集合进行并行化
val lines = sc.parallelize(List(“pandas”,”i like pandas”))
RDD操作:
RDD转化操作是返回一个新的RDD的操作,比如map()和filter()
RDD行动操作则是向驱动器程序返回结果或把结果写入外部系统的操作,会触发实际的计算,spark是一个惰性计算。是有处=触发实际的计算时,才会执行前边的一系列步骤。
1)变换操作
val inputRDD = sc.textFile(“hdfs://hadoop1:9000/input/word/word.txt”)
val keyRDD = inputRDD.filter(line => line.contains("guofei"))
2)行动操作0
val keyRDD = inputRDD.filter(line => line.contains(“guofei”))
wantRDD.take(10).foreach(println)
常见的转化操作和行动操作
1.转化操作
map()与flatMap()区别
flatMap 将函数应用于RDD中的每个元素,将返回的迭代器的所有的内容构成新的RDD,通常用来切分单词
val lines = sc.parallelize(List(“come on”,”guofei”))
var words = lines.flatMap(line => line.split(” “))
words.collect()
map 将函数应用于RDD中的每个元素,将返回值构成新的RDD
var words1 = lines.map(line => line.split(” “))
words1.collect()
filter 返回一个由通过传给filter()的函数的元素组成的RDD
val list = sc.parallelize(List(1,2,3,3))
val listFilter = list.filter(x => x != 1)
listFilter.collect()
distinct 去重
val listDistinct = list.distinct()
listDistinct.collect()
union() 生成一个包含俩哥哥RDD中所有元素的RDD
val list = sc.parallelize(List(3,4,5))
val list1 = sc.parallelize(List(1,2,3))
val union = list.union(list1)
union.collect()
intersection() 求两个RDD共同的元素的RDD
list.intersection(list1).collect()
subtract() 移除里一个RDD中的内容
list.subtract(list1).collect()
cartesian() 与另一个RDD的笛卡儿积
list.cartesian(list1).collect()
2.行动操作
reduce()
val list = sc.parallelize(List(3,4,5))
list.reduce((x,y) => x + y)
collect() 返回RDD中的所有元素
count() RDD中的元素个数
countByValue() 各元素在RDD中出现的次数
take(num) 从RDD中返回num个数
top(num) RDD中返回最前面的num个元素
takeOrdered(num)(ordering) 从RDD中按照提供的舒徐返回最前见的num元素
reduce(func) 并行整合RDD中左右数据
fold(zero)(func) 和reduce一样,但是需要提供初始值
aggregate(zeroValue)(seqOp,combOp) 和reduce相似,但是通常返回不同类型的函数
键值对操作:
创建Pair RDD
使用第一个单词作为键创建出一个pair RDD
val file=sc.textFile(“hdfs://hadoop1:9000/input/word/word.txt”)
file.map(x => (x.split(” “)(0),x)).collect()
Pair RDD的转化操作
创建Pair
val list1 = sc.parallelize(List((1,2),(3,4),(3,6)))
list1.collect()
reduceByKey(func) 合并具有相同键的值
list1.reduceByKey((x,y) => x+y).collect()
groupByKey() 对具有相同键的值进行分组
list1.groupByKey.collect()
mapValues(func) 对pair RDD中的每个值应用一个函数而不改变键
list1.mapValues(x => x+1).collect()
flatMapValues(func) 对pair RDD中的每个值应用一个返回迭代器的函数,然后对返回的每个元素都生成一个对应原键对记录。通常用于符号化
list1.flatMapValues(x => (x to 5)).collect()
keys() 返回一个仅包含键的RDD
list1.keys.collect()
values() 返回一个仅包含值得RDD
list1.values.collect()
sortByKey() 返回一个根据键排序的RDD
list1.sortByKey().collect()
针对两个pair RDD的转化操作
val rdd = sc.parallelize(List((1,2),(3,4),(3,6)))
val other = sc.parallelize(List((1,2)))
subtractByKey 删掉RDD中键与other中的键相同的元素
rdd.subtractByKey(other).collect()
join 对两个RDD进行内连接
rdd.join(other).collect()
leftOuterJoin() 对两个RDD进行连接操作,确保第二个RDD的键必须存在(左外连接)
rdd.leftOuterJoin(other).collect()
cogroup() 将两个RDD中拥有相同键的数据分组到一起
rdd.cogroup(other).collect()















 2641
2641

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









