






过拟合
过拟合,是指模型在训练集上表现的很好,但是在交叉验证集合测试集上表现一般,也就是说模型对未知样本的预测表现一般,泛化(generalization)能力较差。
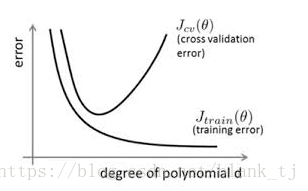
一般防止过拟合的方法有early stopping、数据集扩增(Data augmentation)、正则化(Regularization)、Dropout等。
Early stopping:
在模型对训练数据集迭代收敛之前停止迭代来防止过拟合。
正则化
指的是在目标函数(损失函数)后面添加一个正则化项,一般有L1正则化与L2正则化。L1正则是基于L1范数,即参数绝对值之和与参数的乘积。
C=C0+λn∑|ω| C = C 0 + λ n ∑ | ω |
L2正则是基于L2范数,即在目标函数后面加上参数的L2范数和项,即参数的平方和与参数的乘积。
C=C0+λ2n∑ω2 C = C 0 + λ 2 n ∑ ω 2
数据集扩增
有效的数据集扩增方法:
1)从数据源头采集更多数据
2)复制原有数据并加上随机噪声
3)重采样
4)根据当前数据集估计数据分布参数,使用该分布产生更多数据等
DropOut:
简单说就是在神经网络中,对隐藏层的神经元随机的进行隐藏,认为这些神经元不存在,即不参与当前次训练,同时保持输入层与输出层神经元的个数不变。下一次迭代中,同样随机删除一些神经元,与上次不一样,做随机选择。















 499
499











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









