






异常检测基本概念与方法-datawhale
异常检测
异常检测(Outlier Detection),顾名思义,是识别与正常数据不同的数据,与预期⾏为差异⼤的数
据。
识别如信⽤卡欺诈,⼯业⽣产异常,⽹络流⾥的异常(⽹络侵⼊)等问题,针对的是少数的事件。
个人更加感兴趣:
1.对异常信号出现的检测
2.去除模型异常数据提升模型的准确性
1.1 异常的类别
点异常:指的是少数个体实例是异常的,⼤多数个体实例是正常的,例如正常⼈与病⼈的健康指标;
上下⽂异常:⼜称上下⽂异常,指的是在特定情境下个体实例是异常的,在其他情境下都是正常的,例如在特定时间下的温度突然上升或下降,在特定场景中的快速信⽤卡交易;
群体异常:指的是在群体集合中的个体实例出现异常的情况,而该个体实例⾃⾝可能不是异常,例如社交⽹络中虚假账号形成的集合作为群体异常⼦集,但⼦集中的个体节点可能与真实账号⼀样正常。
1.2 异常检测任务分类
有监督:训练集的正例和反例均有标签
⽆监督:训练集⽆标签
半监督:在训练集中只有单⼀类别(正常实例)的实例,没有异常实例参与训练
半监督似乎投入实用更强;
无监督应该可以作用于模型数据优化的应用中;
有监督条件最苛刻但是实际场景中会出现的更多。
还有一种广泛的场景:大部分标签正常的实例,少部分人工确定的异常实例。
1.3 异常检测场景
故障检测
物联⽹异常检测
欺诈检测
⼯业异常检测
时间序列异常检测
视频异常检测
⽇志异常检测
医疗⽇常检测
⽹络⼊侵检测
2、异常检测常⽤⽅法
2.1 传统⽅法
2.1.1 基于统计学的⽅法
统计学⽅法对数据的正常性做出假定。它们假定正常的数据对象由⼀个统计模型产⽣,而不遵守该模型的数据是异常点。统计学⽅法的有效性⾼度依赖于对给定数据所做的统计模型假定是否成⽴。
异常检测的统计学⽅法的⼀般思想是:学习⼀个拟合给定数据集的⽣成模型,然后识别该模型低概率区域中的对象,把它们作为异常点。即利⽤统计学⽅法建⽴⼀个模型,然后考虑对象有多⼤可能符合该模型。假定输⼊数据集为 ,数据集中的样本服从正态分布,即我们可以根据样本求出参数和 。
2.1.2 线性模型
PCA(Principle Component Analysis)主成分分析。
它的应⽤场景是对数据集进⾏降维。降维后的数据能够最⼤程度地保留原始数据的特征(以数据协⽅差为衡量标准)。
2.1.3 基于相似度的⽅法
这类算法适⽤于数据点的聚集程度⾼、离群点较少的情况。同时,因为相似度算法通常需要对每⼀个数据分别进⾏相应计算,所以这类算法通常计算量⼤,不太适⽤于数据量⼤、维度⾼的数据。
基于相似度的检测⽅法⼤致可以分为三类:
1.基于集群(簇)的检测,如DBSCAN等聚类算法。(K-means)
聚类算法是将数据点划分为⼀个个相对密集的“簇”,而那些不能被归为某个簇的点,则被视作离群点。这类算法对簇个数的选择⾼度敏感,数量选择不当可能造成较多正常值被划为离群点或成小簇的离群点被归为正常。因此对于每⼀个数据集需要设置特定的参数,才可以保证聚类的效果,
在数据集之间的通⽤性较差。聚类的主要⽬的通常是为了寻找成簇的数据,而将异常值和噪声⼀同
作为⽆价值的数据而忽略或丢弃,在专⻔的异常点检测中使⽤较少。
聚类算法的优缺点:
(1)能够较好发现小簇的异常;
(2)通常⽤于簇的发现,而对异常值采取丢弃处理,对异常值的处理不够友好;
(3)产⽣的离群点集和它们的得分可能⾮常依赖所⽤的簇的个数和数据中离群点的存在性;
(4)聚类算法产⽣的簇的质量对该算法产⽣的离群点的质量影响⾮常⼤。
2.基于距离的度量,如k近邻算法。
k近邻算法的基本思路是对每⼀个点,计算其与最近k个相邻点的距离,通过距离的⼤小来判断
它是否为离群点。在这⾥,离群距离⼤小对k的取值⾼度敏感。如果k太小(例如1),则少量的邻近离群点可能导致较低的离群点得分;如果k太⼤,则点数少于k的簇中所有的对象可能都成了离群点。为了使模型更加稳定,距离值的计算通常使⽤k个最近邻的平均距离。
k近邻算法的优缺点:
(1)简单;
(2)基于邻近度的⽅法需要O(m2)时间,⼤数据集不适⽤;
(3)对参数的选择敏感;
(4)不能处理具有不同密度区域的数据集,因为它使⽤全局阈值,不能考虑这种密度的变化。
3.基于密度的度量,如LOF(局部离群因⼦)算法。
局部离群因⼦(LOF)算法与k近邻类似,不同的是它以相对于其邻居的局部密度偏差而不是距离来进⾏度量。它将相邻点之间的距离进⼀步转化为“邻域”,从而得到邻域中点的数量(即密度),认为密度远低于其邻居的样本为异常值。
LOF(局部离群因⼦)算法的优缺点:
(1)给出了对离群度的定量度量;
(2)能够很好地处理不同密度区域的数据;
(3)对参数的选择敏感。
2.2 集成⽅法
集成是提⾼数据挖掘算法精度的常⽤⽅法。集成⽅法将多个算法或多个基检测器的输出结合起来。其基本思想是⼀些算法在某些⼦集上表现很好,⼀些算法在其他⼦集上表现很好,然后集成起来使得输出更加鲁棒。
常⽤的集成⽅法有Feature bagging,孤⽴森林等。
2.3 机器学习
在有标签的情况下,可以使⽤树模型(gbdt,xgboost等)进⾏分类,缺点是异常检测场景下数据标签是不均衡的,但是利⽤机器学习算法的好处是可以构造不同特征。
3、异常检测常⽤开源库
Scikit-learn:
Scikit-learn是⼀个Python语⾔的开源机器学习库。它具有各种分类,回归和聚类算法。也包含了⼀些异常检测算法,例如LOF和孤⽴森林。
PyOD:
Python Outlier Detection(PyOD)是当下最流⾏的Python异常检测⼯具库。
4、Pyod实践
在ubuntu服务器上配置了pyod包,并跑了例子
from pyod.models.knn import KNN # kNN detector
from pyod.utils.data import evaluate_print,generate_data
from pyod.utils.example import visualize
import pdb
contamination = 0.1 # percentage of outliers
n_train = 200 # number of training points
n_test = 100 # number of testing points
X_train, y_train, X_test, y_test = generate_data(
n_train=n_train, n_test=n_test, contamination=contamination)
#pdb.set_trace()
# train kNN detector
clf_name = 'KNN'
clf = KNN()
clf.fit(X_train)
# get the prediction labels and outlier scores of the training data
y_train_pred = clf.labels_ # binary labels (0: inliers, 1: outliers)
y_train_scores = clf.decision_scores_ # raw outlier scores
# get the prediction on the test data
y_test_pred = clf.predict(X_test) # outlier labels (0 or 1)
y_test_scores = clf.decision_function(X_test) # outlier scores
# evaluate and print the results
print("\nOn Training Data:")
evaluate_print(clf_name, y_train, y_train_scores)
print("\nOn Test Data:")
evaluate_print(clf_name, y_test, y_test_scores)
visualize(clf_name, X_train, y_train, X_test, y_test, y_train_pred,
y_test_pred, show_figure=False, save_figure=True)
#show_figure=True, save_figure=False
结果图:
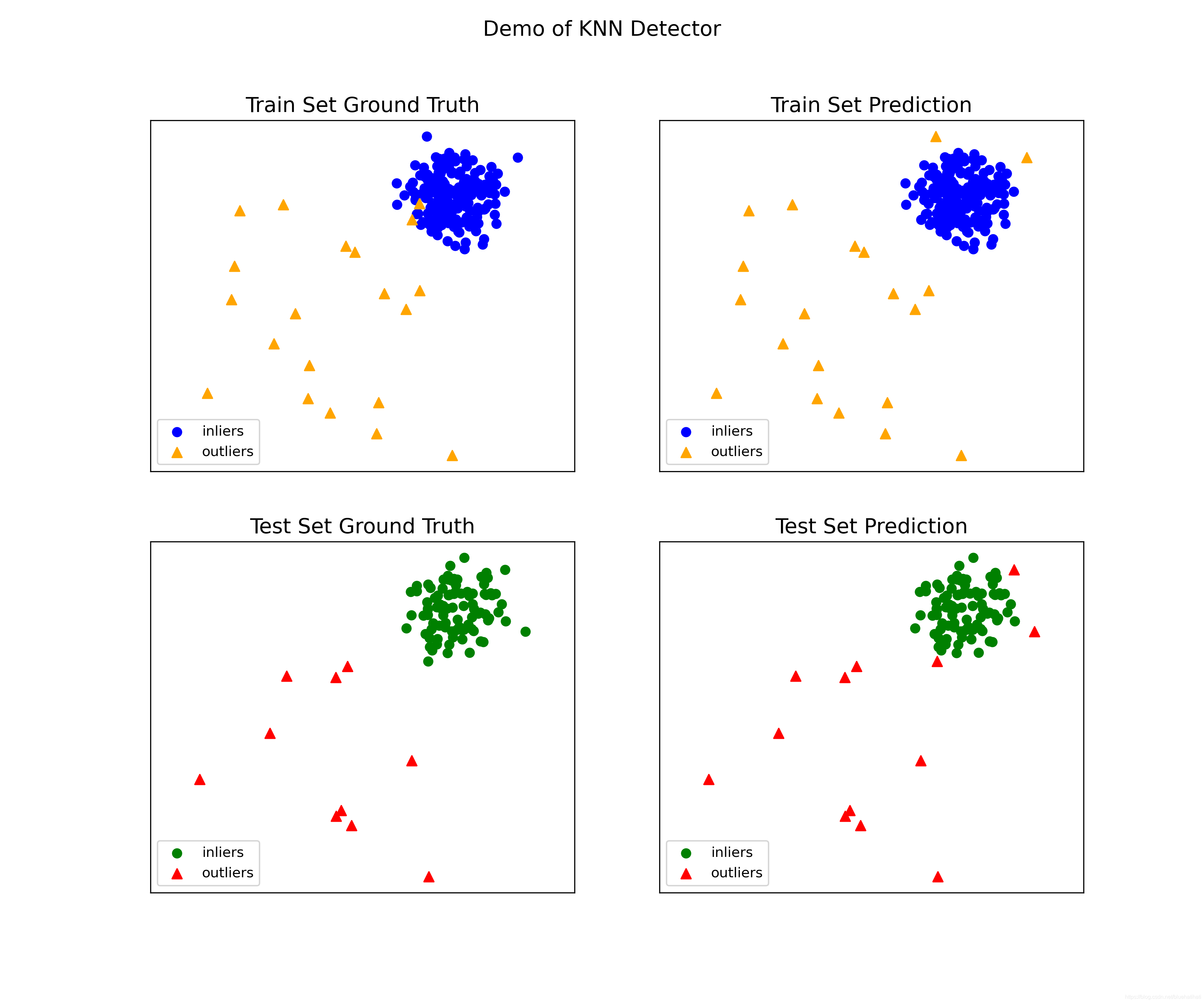
经过断点测试
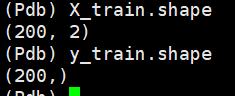
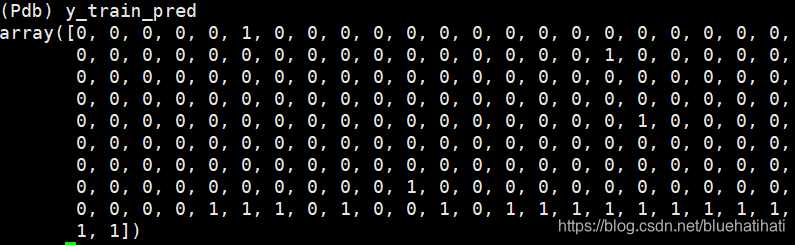
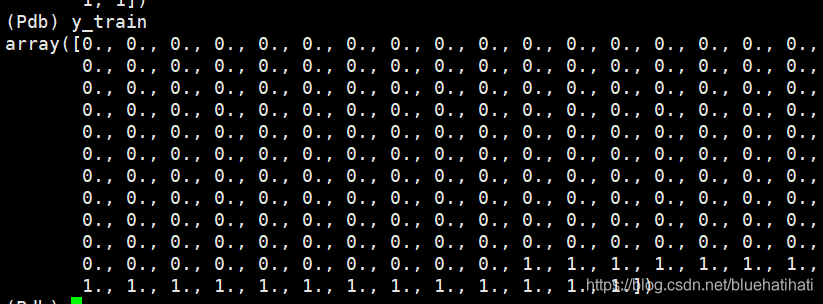
数据点都是2维的,训练集的true标签和预测标签如下所示
测试集的得分
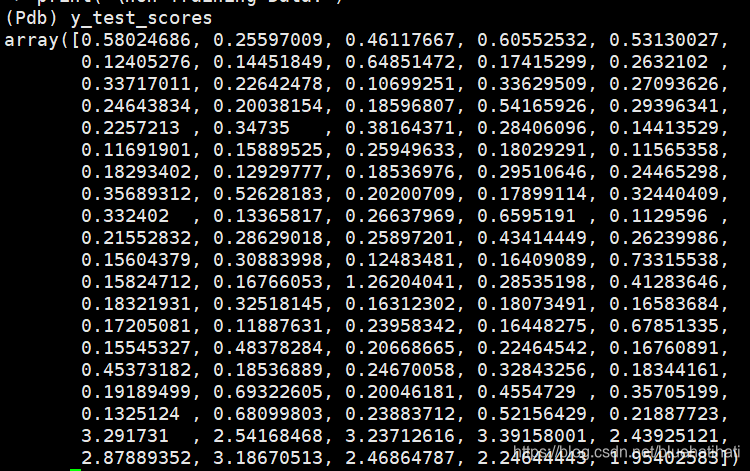
clf.predict()#预测标签
clf.decision_function()#预测得分
生成数据函数:generate_data

生成合成数据的效用函数。正态数据由多元高斯分布生成,异常值由均匀分布生成。
可视化函数:visualize
That all.














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









